关于 java.lang.String 的部分笔记,基于JDK版本1.7。
概述
Java语言中关于基础数据类型char的封装类型,包含了一些类型之间的字符串查找比较、相互转换封装方法,除此之外还有一些非String类型数据转换String的封装方法API供开发人员使用。
继承关系
1 | --java.lang.Object |
实现接口
Serializable, CharSequence, Comparable<String>
部分方法
hashCode()
1 | public int hashCode() { |
该方法计算每个string字符串的hash值。计算过程中,代码行6-8遵循公式 s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1]进行计算,最终算出整个string字符串的hash值。关于计算公式中底数的选择,原作者采用31作为指数计算的底数参与计算,对于这一选择,做如下分析和讨论:
首先,在散列表的设计中有一个概念是冲突率,也就是采用相同的散列函数对不同的数据值进行计算会获取到相同的散列值,于是这些拥有相同散列值的数据会存储在同一个散列表队列中,这样会降低散列查找时的性能。于是在设计散列函数时会尽可能的降低冲突率,使得全域数据值可以尽可能平均的散列在每个散列表中以保证查找效率。鉴于此,在设计散列函数时会考虑选择一些质数来参与计算,诸如2,31,33,37,41,43,101等,这样可以一定程度上保证数据值能均匀分布以降低冲突率(经过数学证明)。
那么为什么会选择31参与计算而不是2或者其他质数呢?在上述公式中,我们假设n=6,那么 $ 2^{6-1} = 32 $ 得出的散列值集中在一个小的区间里,当数据量逐渐增大时,冲突率也会逐渐上升。所以不会采用2参与散列计算。同理,31,33,37,41,43,101等值与n做幂运算会得到一个相对大的散列区间。但是需要注意的是,101求出的散列区间可能会产生溢出(如果用int表示散列值的话),这样会导致数据丢失,所以101也不是一个好的选择。至于31,33,37,41,43这几个质数应该是比较合理的选择,在这里我们引用《Effective Java》中的一段话:
The value 31 was chosen because it is an odd prime. If it were even and the multiplication overflowed, information would be lost, as multiplication by 2 is equivalent to shifting. The advantage of using a prime is less clear, but it is traditional. A nice property of 31 is that the multiplication can be replaced by a shift and a subtraction for better performance:
31 * i == (i << 5) - i. Modern VMs do this sort of optimization automatically.
其中提及到了现代虚拟机对于 31 * i 的一个优化,因为31相对于其他质数来说可以更简单的通过移位和减法操作来实现,所以源码作者最终采用31这个质数参与散列函数的计算。
public native String intern()
Returns a canonical representation for the string object.
A pool of strings, initially empty, is maintained privately by the classString.
When the intern method is invoked, if the pool already contains a string equal to thisStringobject as determined by theequals(Object)method, then the string from the pool is returned. Otherwise, thisStringobject is added to the pool and a reference to thisStringobject is returned.
It follows that for any two stringssandt,s.intern() == t.intern()istrueif and only ifs.equals(t)istrue.
All literal strings and string-valued constant expressions are interned. String literals are defined in section 3.10.5 of the The Java™ Language Specification.
Returns:
a string that has the same contents as this string, but is guaranteed to be from a pool of unique strings.
这个方法在java语言中没有对应实现,具体实现是通过其他语言在底层实现具体逻辑的。这个方法的作用是当调用intern()方法时,如果常量池中已经存在该字符串,则返回池中的字符串引用;否则将此字符串添加到常量池中,并返回字符串的引用。关于在常量池中维护字符串的具体细节,JDK1.6 和JDK1.7之间有一点差别,在1.6中,如果常量池中不存在指定的字符串,那么就实例化一个字符串,并维护到常量池中。但是在1.7中,如果常量池中不存在指定的字符串,那么就把堆内存中该字符串的引用(地址)维护到常量池中,不再单独创建新的字符串对象了。这里通过一段网络上比较流行的示例来了解和学习 intern() 这个方法在JDK1.6和1.7之间的区别(更详细的论述可参考文章《深入解析String#intern》):
1 | String s = new String("1"); |
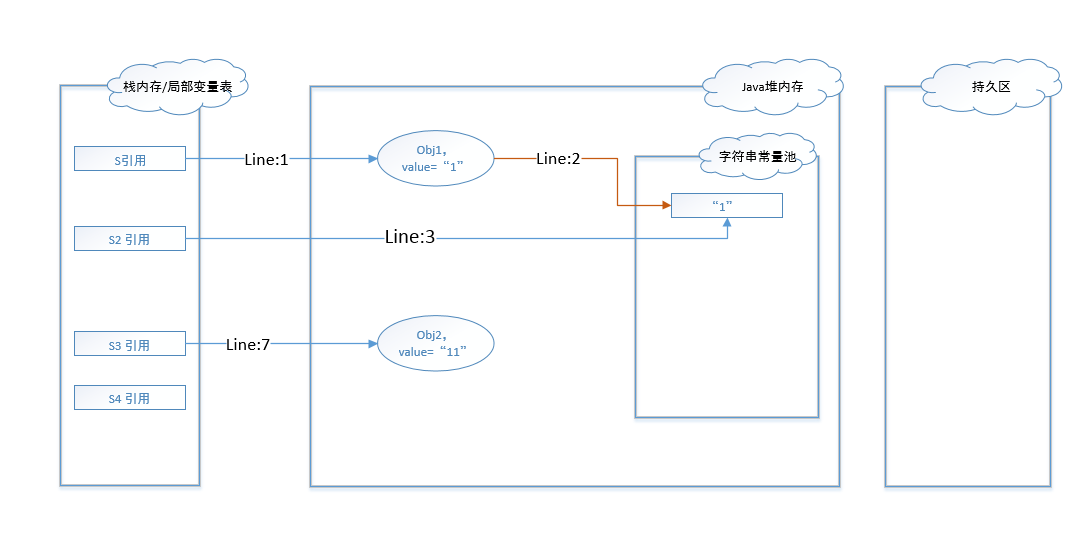
图 -1 到图 - 3展示的是JDK1.6环境下代码的执行过程和数据变化。在该环境下,字符串常量池被维护在了持久区,该区域和Java堆内存是相互独立的。(在代码执行的过程中,不可避免的会生成一些辅助对象实例,这里为了简化解释,故这些辅助对象都不予展示和讨论。)
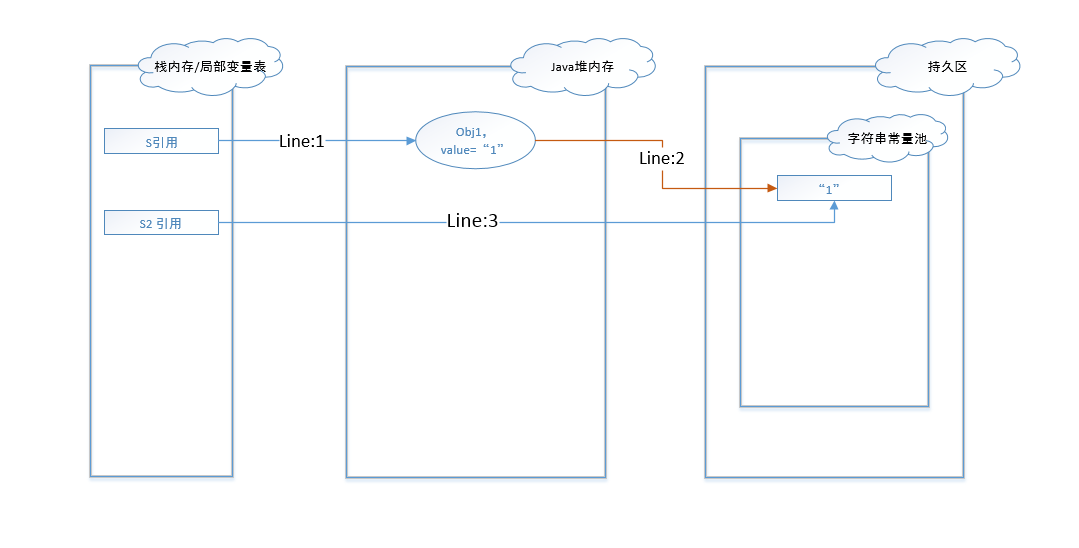
图 - 1展示了代码行1-4的执行过程。在代码编译阶段,常量池中便维护了字符串”1”这个值,所以常量池中会有一份”1”的引用。行1代码执行完之后,堆内存中创建了一个String对象实例,其值为1。行2代码执行后,判断常量池中是否有值为”1”的字符串,发现有,那么直接返回常量池中的引用给堆内存中实例。行3代码直接将常量池中的字符串对象赋给引用s2。
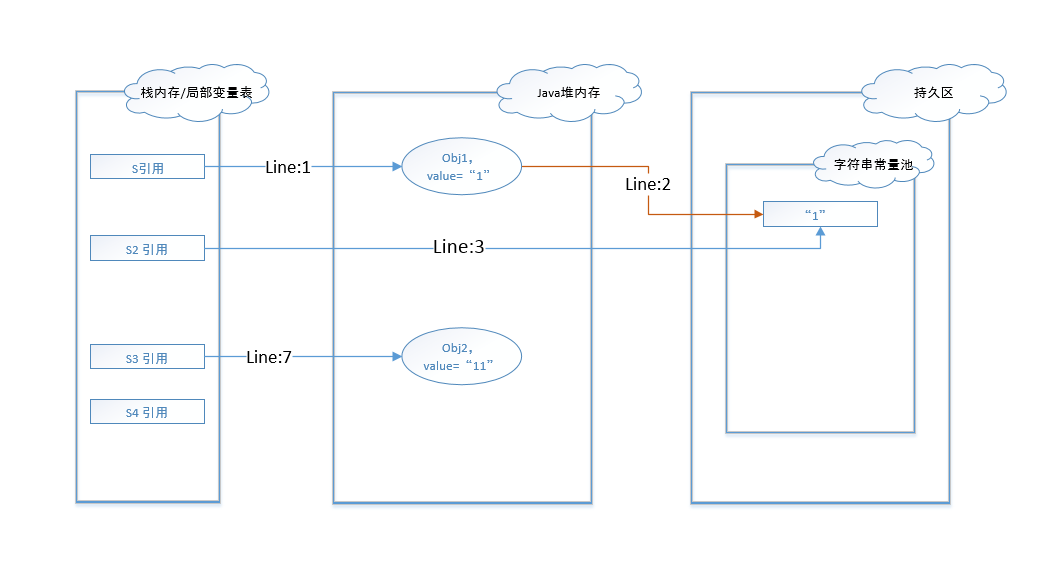
在代码行7执行后,则会在堆内存中创建一个String对象实例,其值为”11”。
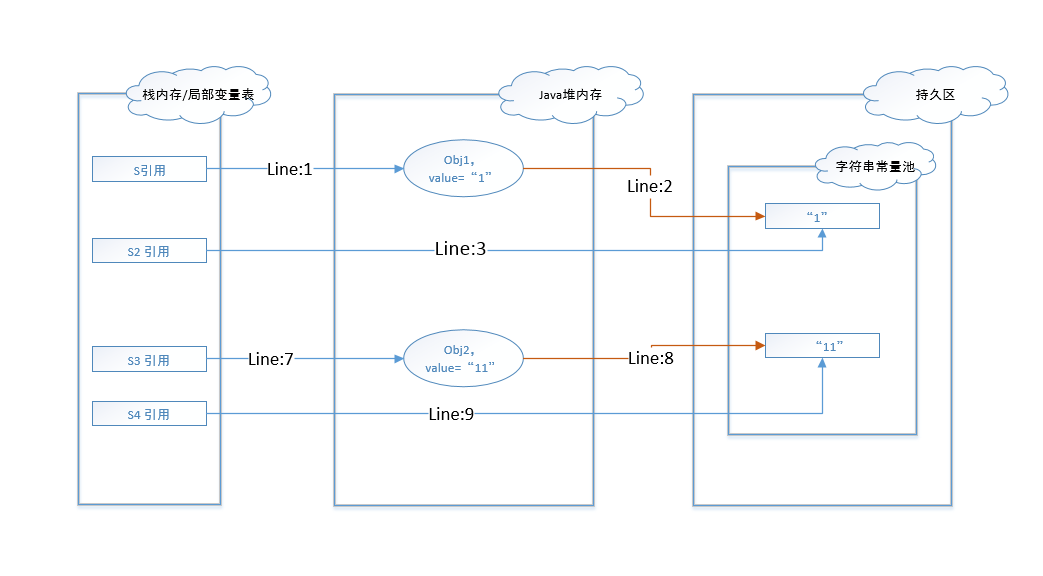
在代码行8执行后,发现字符串常量池中并没有值为”11”的字符串,所以在持久区创建了一个同值的字符串。并将该字符串的地址返回给了堆内存中的obj2。代码行9执行完后,直接将s4的引用指向了字符串常量池中的字符串”11”。
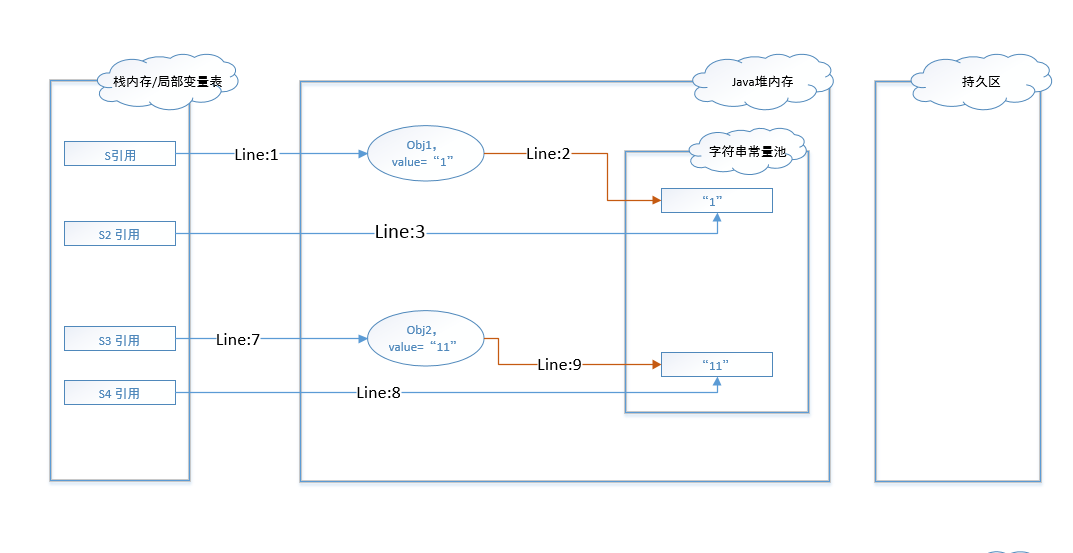
图 - 4到图 - 6展示的是JDK1.7环境下代码的执行过程和数据变化。在该环境下,字符串常量池从持久区中迁移到了堆内存中。
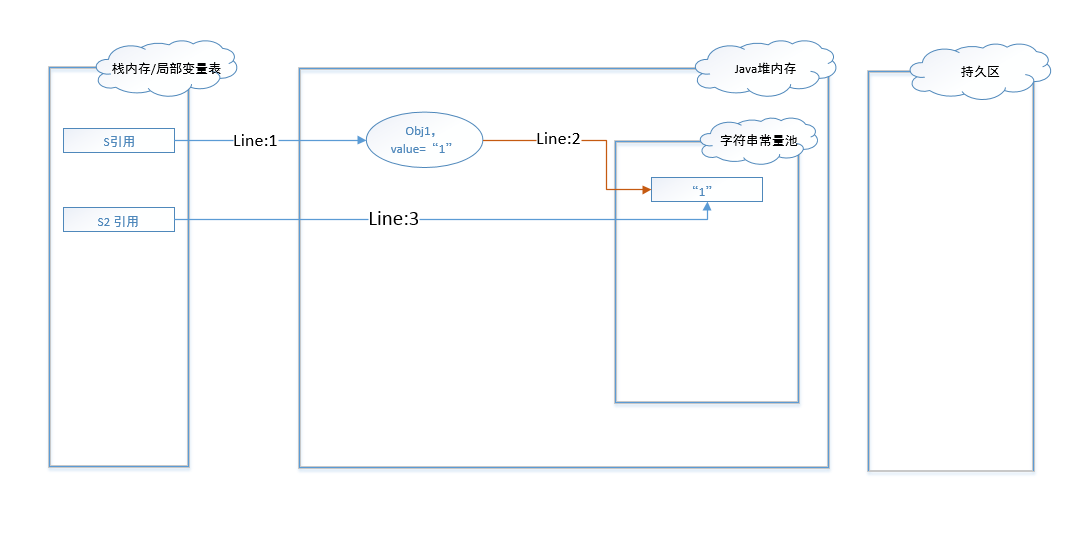
图 - 4的执行过程和图 - 1相似,在代码编译阶段维护了字符串”1”在常量池中,创建实例在堆内存中并通过intern()方法指向常量池中的同值字符串。如果是通过String str = “”的形式则直接指向字符串常量池中的同值字符串。
在代码行7执行后,则会在堆内存中创建一个String对象实例,其值为”11”。
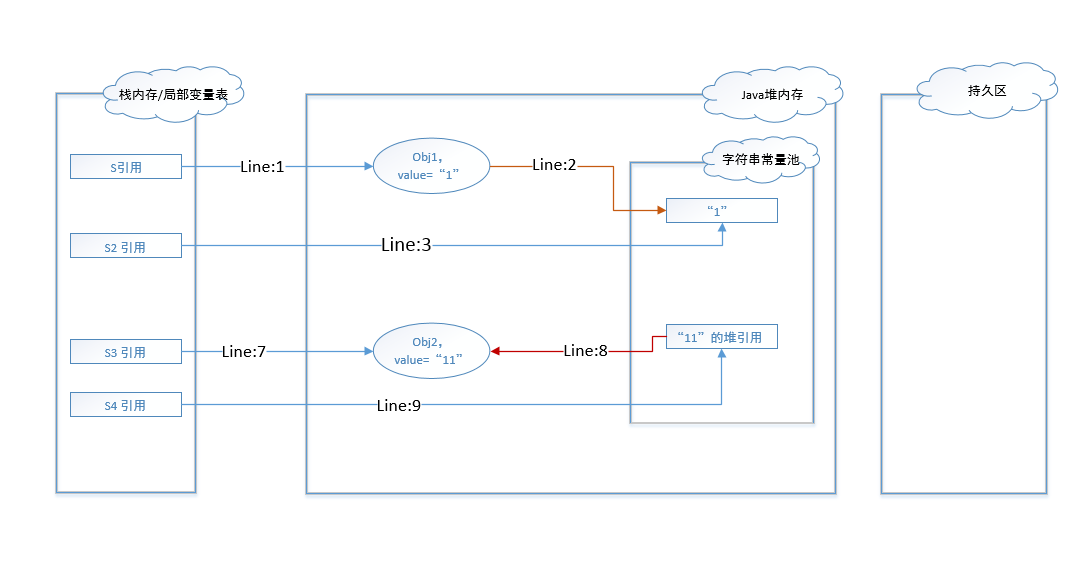
这里期末考试会考!这里期末考试会考!这里期末考试会考!在行8代码执行完以后,不再单独创建值为”11”的字符串对象并维护到常量池中,而是直接将堆中实例obj2的地址维护到了常量池中。于是在行9代码执行完之后,最终实际指向的也是obj2。
将上述代码中调用intern()方法做一下顺序调整,最终得到如下代码段,判定结果又会不一样,就问你意不意外,惊不惊喜!
1 | String s = new String("1"); |
图 - 7到图 - 8还是先从JDK1.6环境开始说起。图 - 9到图 - 10则基于环境JDK1.7。
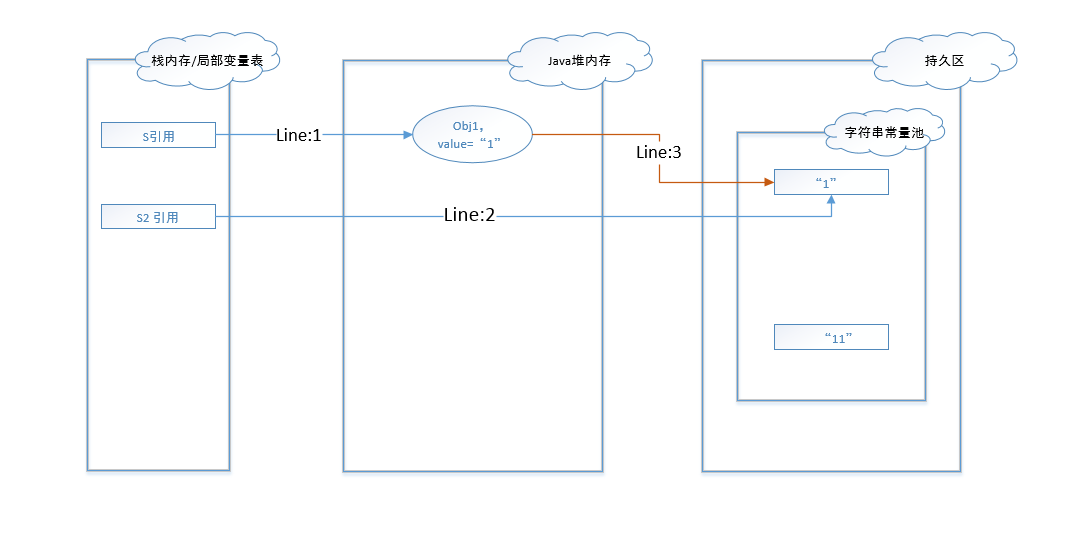
图 - 7的过程和图 -1 相似,只是行2和行3的执行顺序不一致,但是最终结果相同。
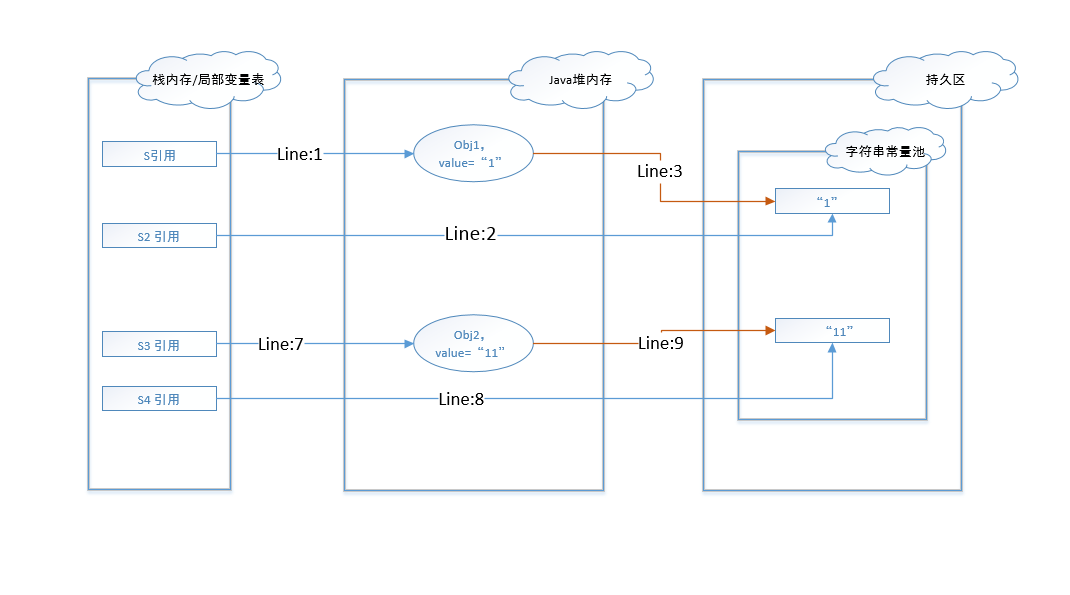
由于字符串”11”在编译阶段就被维护到了常量池中,所以行8直接指向了常量池中的同值字符串”11”。在行9代码执行时,由于常量池中存在同值字符串,所以直接获取其引用。
图 - 9到图 - 10展示的是JDK1.7环境下代码的执行过程和数据变化。在该环境下,字符串常量池从持久区中迁移到了堆内存中。
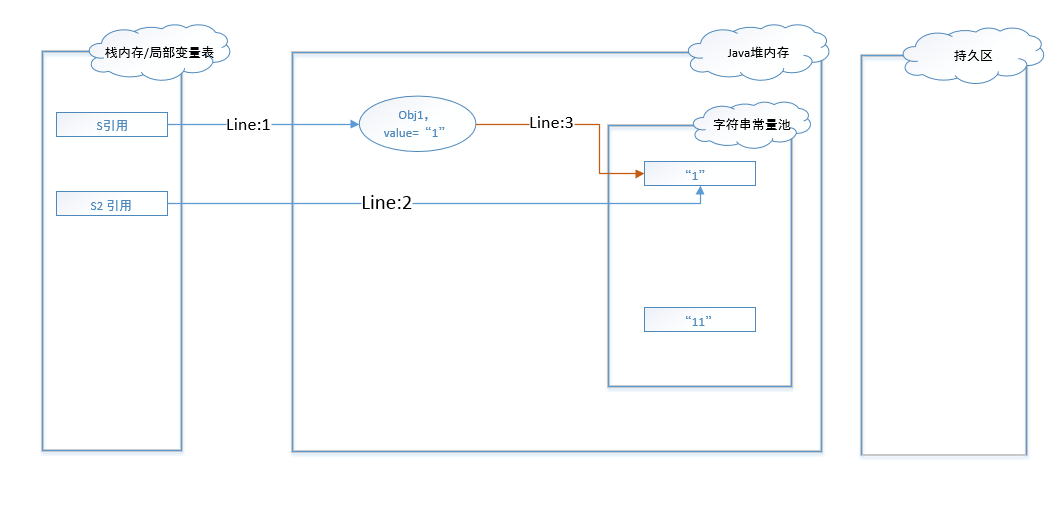
图 - 9执行过程和图 - 7相同,这里不予赘述。
由于常量池中已经维护了字符串”11”,所以在行9调用intern()方法时直接获取了字符串”11”的引用。
这里需要注意的是,只有在调用了intern()后,才会在常量池中判断并维护字符串,如果通过new的方式创建的字符串对象一直未曾调用过intern()方法,那么该对象包含的值也就不会被维护到常量池中。
String 不可变性
String类型的对象一旦创建了就无法修改,这个特性称为不可变性。如下述代码声明:
1 | public final class String |
作者采用关键字final来修饰String类型和value数组。对于String类型来说,final意味着String不可被继承,因此也就不会有子类会重写父类的相关方法,对内容赋值做到了有效控制。对于类中私有变量value来说,这意味着String对象一旦创建并对value数组赋值之后,不会有API去修改value数组的值。关于String的不可变性,《Java核心技术 卷I》 有一个论述:
将方法或类声明为final主要目的是:确保它们不会再子类中改变语义。String类是final类,这意味着不允许任何人定义String的子类。换言之,如果有一个String的引用,它引用的一定是一个String对象,而不可能是其他类的对象。
——《Java核心技术 卷 I》
关于String字符串,JVM为了提高性能和降低内存消耗设计了一个字符串常量池。每当创建一个字符串对象时,JVM首先会在常量池中寻找是否有已存在的具有相同内容值的字符串,如果有,就返回常量池中的引用给到对象,反之则创建一个新的字符串实例并维护到常量池中。
关于字符串常量池,JDK1.6和JDK1.7有一些不一致的地方。如上文陈述,在1.6中,常量池被分配在了永久代中,所以在1.6环境中常量池的数量会有一个上限。这也是为什么在1.6环境中不建议使用String.intern()方法,因为这会导致OOM(Out of memory)。除此之外,在永久代中的常量池也不会参与垃圾回收过程,一旦创建便会一直存在。而在1.7中,常量池被分配在了堆内存中,鉴于此,常量池的容量通过配置-XX:StringTableSize参数得到了大幅提升。所以在1.7环境中,因为常量池被分配到了堆内存的缘故,常量池中的失效内容所占据的内存资源会被垃圾回收过程释放。
连接符号”+”
Java中String对象可以通过”+”来拼接两个字符串,底层原理是通过创建一个Stringbuilder实例对象来完成字符串的拼接,也就是说,通过”+”完成一次字符串拼接会产生一个Stringbuilder对象实例,该实例的值等于拼接操作执行后的预期结果,并通过Stringbuilder对象的toString方法返回执行结果。在JDK1.5之前,底层创建的是Stringbuffer对象,之所以在1.5之后采用Stringbuilder是因为Stringbuilder相对于Stringbuffer来说更有效率。相关代码如下:
1 | public class Test { |
涉及基础知识点
- String的初始化方式及区别:
- String string = “helloworld”;
直接在字符串常量池中创建字符串常量并将地址赋给对象。 - String STR = new String(“RT”):
先在堆中创建对象,然后把对象引用赋给变量。
- String string = “helloworld”;
- 字符串相加:
- 字符串如果是变量相加,先开空间,在拼接。除非变量是用final修饰的,那么可以把用final修饰的变量视为常量处理;
- 字符串如果是常量相加,是先加,然后在常量池找,如果有就直接返回,否则,就创建。
Java语言规范(The Java Language Specification Java SE 7 Edition)关于字符串常量的一些论述如下:
Literal strings within the same class in the same package represent references to the same String object.
Literal strings within different classes in the same package represent references to the same String object.
Literal strings within different classes in different packages likewise represent references to the same String object.
Strings computed by constant expressions are computed at compile time and then treated as if they were literals.
Strings computed by concatenation at run time are newly created and therefore distinct.
The result of explicitly interning a computed string is the same string as any pre-existing literal string with the same contents.同一个包下同一个类中的字符串常量的引用指向同一个字符串对象;
同一个包下不同的类中的字符串常量的引用指向同一个字符串对象;
不同的包下不同的类中的字符串常量的引用仍然指向同一个字符串对象;
参考文献
- [美] Joshua Bloch. Effective Java 2nd Edition[M]. Boston:Addison-Wesley Professional, 2008.
- [美] James Gosling, etc. The Java Language Specification Java SE 7 Edition[M]. Boston:Addison-Wesley Professional, 2013.
- coolblog. 科普:为什么 String hashCode 方法选择数字31作为乘子[E]
- ScienJus. [Java]String中“+”的实现原理及效率[E]
- SEU_Calvin. Java技术——你真的了解String类的intern()方法吗[E]
- Mikhail Vorontsov. String.intern in Java 6, 7 and 8 – string pooling[E]
- lumeng689. 什么是字符串常量池? [E]
- 美团技术团队. 深入解析String#intern [E]