关于 java.util.concurrent.ConcurrentHashMap.Segment<K, V> 的部分笔记,Segment是ConcurrentHashMap的内部类,也是ConcurrentHashMap集合中存储键值对实体的底层数据结构。本文演示代码段的执行环境基于JDK版本1.7 。
概述 Segment是一个特殊的散列表。这个类继承了ReentrantLock,因此Segment自身具有锁和解锁的特性,可以在希望的场景中取得锁和释放锁,以此来保证多线程环境下的线程安全。
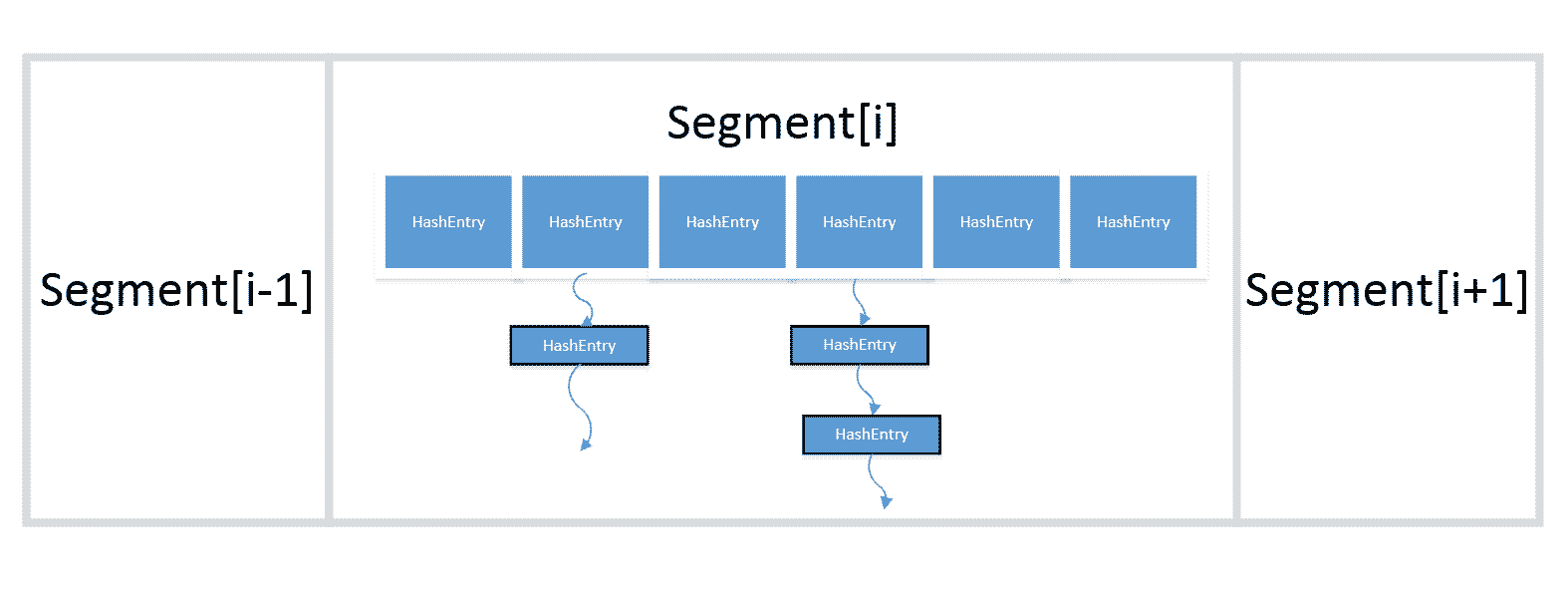
在ConcurrentHashMap的底层是一个Segment数组,每个元素都是一个Segment节点。而每个Segment节点内部维护了一个HashEntry对象,ConcurrentHashMap中的键值对都是存储在某个具体的Segment节点的HashEntry数组内。每个线程会对一个特定的Segment元素获取锁,也就是说,不同的线程会操作不同的Segment元素。在读取元素时,不会对Segment元素加锁,只有向集合中写入数据时才会尝试获取锁。Segment结构如图1所示:
继承关系 1 2 3 4 5 --java.lang.Object --java.util.AbstractMap<K,V> --java.util.concurrent.ConcurrentHashMap<K,V> --java.util.concurrent.ConcurrentHashMap.Segment<K,V>
实现接口
类名
实现接口
Segment<E, V>
Serializable, Lock
Segment Constructor Summary Segment(float lf, int threshold, HashEntry<K,V>[] tab) 1 2 3 4 5 Segment(float lf, int threshold, HashEntry<K,V>[] tab) { this .loadFactor = lf; this .threshold = threshold; this .table = tab; }
初始化一个空Segment实例,指定加载因子、扩容限制阈值和内部的HashEntry数组。
部分方法 final V put(K key, int hash, V value, boolean onlyIfAbsent) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 final V put (K key, int hash, V value, boolean onlyIfAbsent) HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { HashEntry<K,V>[] tab = table; int index = (tab.length - 1 ) & hash; HashEntry<K,V> first = entryAt(tab, index); for (HashEntry<K,V> e = first;;) { if (e != null ) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break ; } e = e.next; } else { if (node != null ) node.setNext(first); else node = new HashEntry<K,V>(hash, key, value, first); int c = count + 1 ; if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(node); else setEntryAt(tab, index, node); ++modCount; count = c; oldValue = null ; break ; } } } finally { unlock(); } return oldValue; }
将key=value键值对存储到当前segment实体的HashEntry集合中。第2行代码会尝试对当前segment获取锁控制。如果成功得到了锁,那么就直接执行后续后续代码,如果当前方法被其他锁占有,那么等待,直到当前线程得到锁并返回一个node对象(有可能是其他线程插入的,也有可能是当前线程自己生成的)。
根据hash值计算出node在当前HashEntry数组中的下标位置,如果该下标位置尚未存储HashEntry实体,且node已经生成(如果没有生成的话,第26行代码负责生成一个),那么首先通过rehash()方法判断是否需要执行扩容操作,之后将新生成的node节点存入当前segment的HashEntry数组中。如果该下标位置已经存储了HashEntry实体,那么循环遍历该链表集合,检查是否存在可以匹配key的键值对映射,如果存在,根据onlyIfAbsent字段决定是否需要替换。
最后释放当前线程对方法的占用。
private void rehash(HashEntry<K,V> node) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 @SuppressWarnings ("unchecked" )private void rehash (HashEntry<K,V> node) HashEntry<K,V>[] oldTable = table; int oldCapacity = oldTable.length; int newCapacity = oldCapacity << 1 ; threshold = (int )(newCapacity * loadFactor); HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity]; int sizeMask = newCapacity - 1 ; for (int i = 0 ; i < oldCapacity ; i++) { HashEntry<K,V> e = oldTable[i]; if (e != null ) { HashEntry<K,V> next = e.next; int idx = e.hash & sizeMask; if (next == null ) newTable[idx] = e; else { HashEntry<K,V> lastRun = e; int lastIdx = idx; for (HashEntry<K,V> last = next; last != null ; last = last.next) { int k = last.hash & sizeMask; if (k != lastIdx) { lastIdx = k; lastRun = last; } } newTable[lastIdx] = lastRun; for (HashEntry<K,V> p = e; p != lastRun; p = p.next) { V v = p.value; int h = p.hash; int k = h & sizeMask; HashEntry<K,V> n = newTable[k]; newTable[k] = new HashEntry<K,V>(h, p.key, v, n); } } } } int nodeIndex = node.hash & sizeMask; node.setNext(newTable[nodeIndex]); newTable[nodeIndex] = node; table = newTable; }
对当前segment的HashEntry数组进行扩容并完成元素迁移。第3 ~ 6行代码完成新数组容量、扩容限制阈值的计算,并在第7行代码中完成数组初始化操作。
第10 ~ 40行代码遍历整个数组,完成数组中元素向新数组的迁移。第11行代码取得数组中不为null的元素,如果该元素的链表集合中仅有一个元素,那么计算该元素在新数组的下标并保存到新数组中。反之,如果当前数组元素的链表集合中有多个元素,那么首先遍历该链表集合,找到这样的一个节点:1)该节点及之后的所有节点在新数组的同一个下标位置,2)满足条件(1)的节点是当前数组元素的链表集合中最后一个满足条件(1)的节点。之后在第29行代码会把找到的节点及其之后的所有节点移到新数组的对应下标中。第31 ~ 36行代码则遍历当前数组元素的链表集合中剩余的元素,循环计算它们在新数组的下标并保存到新数组的对应位置中。
最后,第41 ~ 44行代码计算新元素节点在新数组中的下标位置,并把新元素节点放到该下标位置的链表集合的首部位置。
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 private HashEntry<K,V> scanAndLockForPut (K key, int hash, V value) HashEntry<K,V> first = entryForHash(this , hash); HashEntry<K,V> e = first; HashEntry<K,V> node = null ; int retries = -1 ; while (!tryLock()) { HashEntry<K,V> f; if (retries < 0 ) { if (e == null ) { if (node == null ) node = new HashEntry<K,V>(hash, key, value, null ); retries = 0 ; } else if (key.equals(e.key)) retries = 0 ; else e = e.next; } else if (++retries > MAX_SCAN_RETRIES) { lock(); break ; } else if ((retries & 1 ) == 0 && (f = entryForHash(this , hash)) != first) { e = first = f; retries = -1 ; } } return node; }
当前线程等待其他线程释放对当前segment的控制,并返回(生成)一个node节点,该node的key等于入参key,node的hash等于入参hash,node的value等于入参value。
这个方法可能会在两个地方获得锁,第6行代码和第20行代码,在任何一个地方得到锁以后都会退出循环且得到一个node对象,最后返回到put方法。
private void scanAndLock(Object key, int hash) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 private void scanAndLock (Object key, int hash) HashEntry<K,V> first = entryForHash(this , hash); HashEntry<K,V> e = first; int retries = -1 ; while (!tryLock()) { HashEntry<K,V> f; if (retries < 0 ) { if (e == null || key.equals(e.key)) retries = 0 ; else e = e.next; } else if (++retries > MAX_SCAN_RETRIES) { lock(); break ; } else if ((retries & 1 ) == 0 && (f = entryForHash(this , hash)) != first) { e = first = f; retries = -1 ; } } }
当前线程尝试对当前segment对象获取锁控制。
final V remove(Object key, int hash, Object value) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 final V remove (Object key, int hash, Object value) if (!tryLock()) scanAndLock(key, hash); V oldValue = null ; try { HashEntry<K,V>[] tab = table; int index = (tab.length - 1 ) & hash; HashEntry<K,V> e = entryAt(tab, index); HashEntry<K,V> pred = null ; while (e != null ) { K k; HashEntry<K,V> next = e.next; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { V v = e.value; if (value == null || value == v || value.equals(v)) { if (pred == null ) setEntryAt(tab, index, next); else pred.setNext(next); ++modCount; --count; oldValue = v; } break ; } pred = e; e = next; } } finally { unlock(); } return oldValue; }
从当前segment实体中删除key=value映射实体。
第2 ~ 3行代码执行时当前线程会尝试获取对方法的锁控制,如果得到锁以后,第7行代码会计算入参key=value键值对在当前segment的HashEntry数组中的下标位置。得到该下标位置处的链表集合后,遍历该集合中的每个键值对实体。如果存在key相同且value相同的记录,那么如果该节点是链表的第一个节点,那么执行第18行代码用该节点的后继节点完成删除操作。如果该节点不是链表的第一个节点,那么就采用第20行代码的方式完成删除操作。如果没有找到key相同的记录,那么向后遍历直至整个链表集合全部被遍历过。
最后释放对方法的锁控制并返回被删除的键值对实体的value值。
final boolean replace(K key, int hash, V oldValue, V newValue) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 final boolean replace (K key, int hash, V oldValue, V newValue) if (!tryLock()) scanAndLock(key, hash); boolean replaced = false ; try { HashEntry<K,V> e; for (e = entryForHash(this , hash); e != null ; e = e.next) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { if (oldValue.equals(e.value)) { e.value = newValue; ++modCount; replaced = true ; } break ; } } } finally { unlock(); } return replaced; }
用key=value键值对替换当前segment实体中HashEntry数组中可以匹配的键值对实体。第2 ~ 3行代码会尝试得到锁控制。在得到锁以后,根据hash计算出键值对在HashEntry数组中的下标位置并遍历该下标处的链表集合,找到可以匹配入参key、value和hash的键值对实体。如果有,那么完成value替换。替换完成或者遍历完成后释放锁控制,返回替换结果(true - 替换完成,false - 替换未执行)。
final V replace(K key, int hash, V value) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 final V replace (K key, int hash, V value) if (!tryLock()) scanAndLock(key, hash); V oldValue = null ; try { HashEntry<K,V> e; for (e = entryForHash(this , hash); e != null ; e = e.next) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; e.value = value; ++modCount; break ; } } } finally { unlock(); } return oldValue; }
用key=value键值对替换当前segment实体中HashEntry数组中可以匹配的键值对实体。第2 ~ 3行代码会尝试得到锁控制。在得到锁以后,根据hash计算出键值对在HashEntry数组中的下标位置并遍历该下标处的链表集合,找到可以匹配入参key、value和hash的键值对实体。如果有,那么完成value替换。替换完成或者遍历完成后释放锁控制,返回被替换value值。
final void clear() 1 2 3 4 5 6 7 8 9 10 11 12 final void clear () lock(); try { HashEntry<K,V>[] tab = table; for (int i = 0 ; i < tab.length ; i++) setEntryAt(tab, i, null ); ++modCount; count = 0 ; } finally { unlock(); } }
清空当前Segment实体的HashEntry集合。
涉及基础知识点
NIL
参考文献
NIL