关于 java.util.Vector<E> 的部分笔记。Vector是线程安全版本的、可变长度的、可用随机访问的方式获取元素的、基于数组实现的集合容器实现类。但是由于其主要方法都通过synchronized保证了多线程的线程安全特性,所以其性能相对ArrayList而言会慢很多。本文演示代码段的执行环境基于JDK版本1.7。
概述
Vector是一个可变长度的集合容器,底层是基于数组实现的。由于其同样实现了RandomAccess接口,所以可以按照随机访问的方式来访问集合中的元素。
Vector生成的iterators同样带有快速失败属性。如果某个迭代器在运行时发现Vector集合最近一次的结构化修改不是由迭代器自身完成的,那么会抛出ConcurrentModificationException异常。
在List中,支持随机访问存储的集合实现有ArrayList和Vector。二者的底层实现都是依赖于数组完成的。但是ArrayList在多线程环境下无法保证线程安全,而Vector则可以用于多线程环境下的元素存储需要,通过在方法声明中加入synchronized关键字来保证多线程环境的线程安全。所以如果需要在多线程环境下实现可随机访问的List集合,那么需要使用的是Vector而不是ArrayList。需要注意的是,由于Vector的多线程特性,所以其性能会稍逊于ArrayList。所以,如果没有实际的多线程环境需要,可用ArrayList来替换Vector以提高性能。
继承关系
1 | // Vector<E> |
实现接口
| 类名 | 实现接口 |
|---|---|
| Vector<E> | Iterable<E>, Collection<E>, List<E>, RandomAccess, Serializable, Cloneable |
Vector
Constructor Summary
public Vector(int initialCapacity, int capacityIncrement)
1 | public Vector(int initialCapacity, int capacityIncrement) { |
根据入参initialCapacity指定的长度初始化一个Vector空集合实例。capacityIncrement参数指定了Vector在执行扩容操作时依据的扩容规模大小。
public Vector(int initialCapacity)
1 | public Vector(int initialCapacity) { |
根据入参initialCapacity指定的长度初始化一个Vector空集合实例。capacityIncrement默认为0。
public Vector(Collection<? extends E> c)
1 | public Vector(Collection<? extends E> c) { |
根据集合c初始化一个Vector集合实例,并将c中的内容复制到实例化后的集合实例中。初始化的实例集合中元素的位置和c一致。
elementCount是Vector当前已经容纳的元素数,非Vector可以容纳的元素总数,Vector可以容纳的元素总数可以从elementData.length中得到。
部分方法
public void trimToSize()
1 | public void trimToSize() { |
缩小Vector的存储容量。将暂时尚未存储元素的空间全部释放掉。
public synchronized void copyInto(Object[] anArray)
1 | public synchronized void copyInto(Object[] anArray) { |
将Vector中的元素复制到数组anArray中。由于System.arraycopy是浅复制,所以对anArray的修改会同步出现在Vector的集合中。
public synchronized void ensureCapacity(int minCapacity)
1 | public synchronized void ensureCapacity(int minCapacity) { |
扩容操作。由于扩容操作会修改Vector集合的空间大小,所以需要记录modCount值。这个方法没有在Vector内部调用,如果在需要用Vector的场景中可以预先估计到可能存储的元素数量,那么可以调用该方法提前完成内存空间的分配进而避免频繁分配存储空间降低执行性能。
private void ensureCapacityHelper(int minCapacity)
1 | private void ensureCapacityHelper(int minCapacity) { |
扩容底层操作。如果调用时需要的容量大小超过了当前Vector的elementData长度就执行扩容操作。反之不做处理。在计算扩充后容量时,如果指定了capacityIncrement大小,那么就在当前Vector空间容量的基础上增加capacityIncrement个空间。反之,如果未指定capacityIncrement大小,那么扩容后容量是当前容量的两倍大小。如果扩容后数量还是无法满足参数要求,那么就将Vector空间扩容为参数minCapacity指定的大小。
public synchronized void setSize(int newSize)
1 | public synchronized void setSize(int newSize) { |
重置Vector的存储元素个数。由于该操作会修改Vector集合的存储元素数,所以需要记录modCount值。如果newSize大于Vector集合中存储的元素数,那么就执行扩容处理,空出部分被填充为null。反之,则清除自newSize及以后位置的元素,并释放空间。最后更新elementCount,该字段标记了Vector集合中存储的元素个数。
public synchronized int capacity()
1 | public synchronized int capacity() { |
返回Vector集合的空间大小,既可以容纳的元素个数。
public synchronized int size()
1 | public synchronized int size() { |
返回Vector集合当前存储的元素个数。如果elementCount为0,那么isEmpty()方法就会返回true,否则返回false。
public Enumeration<E> elements()
1 | public Enumeration<E> elements() { |
以枚举方式返回Vector集合中的每一个元素。
public boolean contains(Object o)
1 | public boolean contains(Object o) { |
判断当前Vector集合中是否含有元素o。如果Vector集合存储了一个及以上元素o,那么就返回true,否则返回false。
public int indexOf(Object o)
1 | public int indexOf(Object o) { |
返回元素o在Vector集合中第一次出现的位置(即o在集合中第一次被存储的位置)。如果元素o为null,那么就返回null第一次被存储的位置,否则返回非null元素在Vector集合中第一次出现的位置。如果元素o不存在于集合Vector中,那么返回-1。
public synchronized int lastIndexOf(Object o)
1 | public synchronized int lastIndexOf(Object o) { |
返回元素o在Vector集合中最后一次出现的位置(即o在集合中最后一次被存储的位置)。将当前Vector集合从尾向首逐个遍历,如果元素o为null,那么就返回null最后一次被存储的位置,否则返回非null元素在Vector集合中最后一次出现的位置。如果元素o不存在于集合Vector中,那么返回-1。
public synchronized E elementAt(int index)
1 | public synchronized E elementAt(int index) { |
返回Vector中index位置指定的元素。如果index指示位置大于Vector的元素个数(index >= elementCount)则抛出边界溢出异常。实际调用elementData(int index)方法完成所有操作。
E elementData(int index)
1 | ("unchecked") |
返回Vector中index位置处的元素。
public synchronized E firstElement()
1 | public synchronized E firstElement() { |
返回Vector集合中第一个元素。
public synchronized E lastElement()
1 | public synchronized E lastElement() { |
返回Vector集合中最后一个元素。
public synchronized void setElementAt(E obj, int index)
1 | public synchronized void setElementAt(E obj, int index) { |
将index位置处的元素置换为obj。
public synchronized void removeElementAt(int index)
1 | public synchronized void removeElementAt(int index) { |
移除index位置处的元素。因为元素移除属于结构化修改,所以需要维护modCount的值。接着需要通过边界检查判定index的合法性以避免边界溢出。然后将index位置之后的元素(不包括index)统一向前移动一个单位,便会覆盖移除掉index位置处的元素。最后维护elementCount并更新其值。
public synchronized void insertElementAt(E obj, int index)
1 | public synchronized void insertElementAt(E obj, int index) { |
在index位置处插入元素obj。因为元素插入属于结构化修改,所以需要维护modCount的值。接着需要通过边界检查判定index的合法性以避免边界溢出。然后判断当前集合空间是否足够,如果空间不足的话需要执行扩容操作。最后将index位置之后的元素(包括index)统一向后移动一个单位,加入传入的元素obj,并维护更新elementCount的值。
public synchronized boolean add(E e)
1 | public synchronized boolean add(E e) { |
向Vector集合中加入元素o,返回true表示加入成功。
public void add(int index, E element)
1 | public void add(int index, E element) { |
向Vector集合中index指定的位置处加入元素element。
public synchronized void addElement(E obj)
1 | public synchronized void addElement(E obj) { |
向Vector集合中加入一个元素obj。因为元素加入属于结构化修改,所以需要维护modCount的值。加入元素之前需要先判断是否有必要执行扩容处理,如果需要的话先完成扩容处理提供足够的空间来容纳新元素。最后在集合尾部将元素obj加入到集合中。
public synchronized boolean addAll(int index, Collection<? extends E> c)
1 | public synchronized boolean addAll(int index, Collection<? extends E> c) { |
将集合c中的元素全部加入到Vector集合中自index位置起的空间里。因为元素加入属于结构化修改,所以需要维护modCount的值。获取到c集合中的元素数据内容和元素个数,判断当前Vector集合是否有足够空间存储c中所有元素,如果空间不足则需要执行扩容操作。第11 ~ 13行代码将Vector集合中自index位置起,长度为c中集合元素数的空间里存储的元素统一向后移动,留出的空间被用来存储c中元素。最后将c中元素存储到Vector集合中指定位置的空间里,更新elementCount的值。
public synchronized boolean addAll(Collection<? extends E> c)
1 | public synchronized boolean addAll(Collection<? extends E> c) { |
将集合c中的元素全部加入到Vector集合中。因为元素加入属于结构化修改,所以需要维护modCount的值。获取到c集合中的元素数据内容和元素个数,判断当前Vector集合是否有足够空间存储c中所有元素,如果空间不足则需要执行扩容操作。空间充足时将c中元素存储到Vector集合中,更新elementCount的值。
public synchronized E remove(int index)
1 | public synchronized E remove(int index) { |
移除index位置处存储的元素并返回被移除的元素。
public synchronized boolean removeElement(Object obj)
1 | public synchronized boolean removeElement(Object obj) { |
移除Vector集合中删除元素obj。删除原则是先判断obj是否存在于集合中,如果不存在返回false,否则确定obj被存储的下标index最小的位置,并把该位置处存储的obj删除调,返回true标识成功删除元素obj。
public boolean remove(Object o)
1 | public boolean remove(Object o) { |
移除Vector集合中删除元素o。
public synchronized void removeAllElements()
1 | public synchronized void removeAllElements() { |
清空Vector集合中的所有元素。集合容量重置为0。
public synchronized boolean removeAll(Collection<?> c)
1 | public synchronized boolean removeAll(Collection<?> c) { |
移除同时存在于Vector集合和c集合中的元素。调用的是AbstractCollection.removeAll(Collection<?> c)。
public void clear()
1 | public void clear() { |
清空Vector集合中的所有元素。集合容量重置为0。
public synchronized Object clone()
1 | public synchronized Object clone() { |
对象克隆复制。浅度复制,对复制内容的修改会在Vector集合中显现,反之亦然。
public synchronized Object[] toArray()
1 | public synchronized Object[] toArray() { |
将Vector集合中的元素按照数组的方式返回。
public synchronized <T> T[] toArray(T[] a)
1 | ("unchecked") |
将Vector集合中的元素以数组的方式存储到数组a中。如果a的空间小于Vector集合的元素数,那么就返回一个新的数组对象,该对象中以a的类型为基础,且存储的是Vector集合中的元素数据内容。如果a的长度大于集合中存储的元素总数,那么a数组中最后一个元素的下一个存储位置会被置为null,如果集合中没有存储任何null元素,那么这个操作执行完成后便可以非常方便的得到集合中存储的元素总数。
E elementData(int index)
1 | ("unchecked") |
返回Vector集合中index位置处的元素。
public synchronized E get(int index)
1 | public synchronized E get(int index) { |
返回Vector集合中index位置处的元素。在有效使用index之前对index做了边界校验,避免越界溢出发生。
public synchronized E set(int index, E element)
1 | public synchronized E set(int index, E element) { |
将Vector集合中index位置处的元素替换为element,并返回被替换的元素。
public synchronized boolean containsAll(Collection<?> c)
1 | public synchronized boolean containsAll(Collection<?> c) { |
判断Vector集合中是否包含c中所有元素。如果Vecto集合包含c中所有元素,那么返回true,否则返回false。实际调用AbstractCollection.containsAll(Collection<?> c)完成操作。
public synchronized boolean retainAll(Collection<?> c)
1 | public synchronized boolean retainAll(Collection<?> c) { |
保留同时包含在Vector集合和c集合中的元素,对于只存在于Vector集合,不存在于c集合的元素会被删除掉,类似于数学领域内的两个集合取交集操作。实际调用AbstractCollection.retainAll(Collection<?> c)完成操作。
public synchronized boolean equals(Object o)
1 | public synchronized boolean equals(Object o) { |
判断当前Vector集合是否等于对象o。实际调用AbstractList.equals(Object o)完成操作。
public synchronized int hashCode()
1 | public synchronized int hashCode() { |
返回当前Vector集合的散列值。实际调用AbstractList.hashCode()完成操作。
public synchronized String toString()
1 | public synchronized String toString() { |
返回当前Vector集合的字符串表示,内部元素也以字符串形式表示。实际调用AbstractCollection.toString()完成操作。
public synchronized List<E> subList(int fromIndex, int toIndex)
1 | public synchronized List<E> subList(int fromIndex, int toIndex) { |
通过调用AbstractList.subList(int fromIndex, int toIndex)方法获取Vector集合中自fromIndex位置起,到toIndex位置之间的子集合并返回。由于Vector被应用于多线程环境,而subList(int fromIndex, int toIndex)返回的是一个非线程安全的随机访问集合,所以通过Collections.synchronizedList(List
protected synchronized void removeRange(int fromIndex, int toIndex)
1 | protected synchronized void removeRange(int fromIndex, int toIndex) { |
移除Vector集合中自fromIndex位置起,到toIndex位置之间的所有元素。操作过程可见图1:
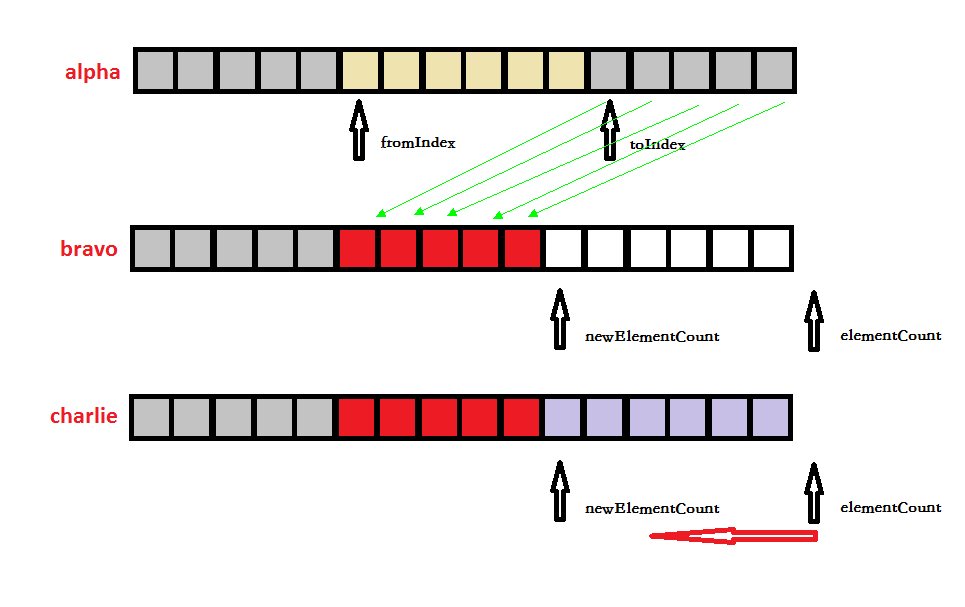
在alpha阶段由fromIndex和toIndex指定了需要删除的范围。第3 ~ 5行代码执行完之后则到达bravo阶段。灰色区域为fromIndex之前的元素,无变化。红色区域的元素由alpha阶段toIndex位置及之后的元素向左移动得到。第8行代码重新计算得到了newElementCount,也是从集合尾部删除元素操作的终点位置。在charlie中,elementCount逐个向左移动并删除元素释放空间,直到其到达newElementCount位置便停止操作。
private void writeObject(java.io.ObjectOutputStream s)
1 | private void writeObject(java.io.ObjectOutputStream s) |
序列化写操作。将当前Vector集合对象的内容以自定义的方式重新实现了其序列化过程。
public synchronized Iterator<E> iterator()
1 | public synchronized Iterator<E> iterator() { |
返回一个基于Vector集合的迭代器。该迭代器只能对集合做向后遍历。Itr类的相关实现如下:
1 | private class Itr implements Iterator<E> { |
public synchronized ListIterator<E> listIterator(int index)
1 | public synchronized ListIterator<E> listIterator(int index) { |
返回一个基于Vector集合的可以从index位置开始遍历的迭代器。如果index参数没有传,那么默认从首部位置开始迭代。该迭代器可以对Vector集合进行双向遍历。ListItr(0)的相关实现如下:
1 | final class ListItr extends Itr implements ListIterator<E> { |
涉及基础知识点
Enumeration和Iterator的联系
Enumeration接口是JDK1.0时推出的,在JDK1.5之后为Enumeration接口进行了扩充,增加了泛型的操作应用。Iterator迭代器取代了 Enumeration的功能,同时增添了删除元素的方法,并且对方法的名称进行了改进。为什么还要使用Enumeration?这是因为一些比较古老的系统或者类库中的方法还在使用Enumeration接口,因此为了兼容,继续保留Enumeration相关定义保证代码正常有效。本文中涉及到的Vector就仍有Enumeration的具体实现。还有Iterator 是 Fast-Fail的,但 Enumeration不是,也就是说,Iteartor可以对非自身作出的结构化修改作出响应,而Enumeration没有这方面的判断和操作。
Vector实现writeObject(java.io.ObjectOutputStream s)的意义
和ArrayList一样,Vector自己实现了writeObject方法用来对elementData、elementCount和capacityIncrement执行序列化操作。Vector通过writeObject把elementData、elementCount和capacityIncrement里的元素写入到输出流ObjectOutputStream )中,通过默认处理从输入流(ObjectInputStream )读取到被序列化的数据并反序列化之后存储到elementData。
需要注意的是,writeObject方法都被声明为私有方法,且在Vector内部没有任何地方调用了该方法。实际上,这两个方法是通过反射的方式出现在了ObjectOutputStream、的方法writeObject()和调用栈中。
为什么线程安全的Vector会比非线程安全的ArrayList慢
多线程环境中涉及到一个概念—上下文切换。由于CPU同一个时刻只能执行一个任务,所以如果让CPU在不同的任务之间来回切换任务执行的话不可避免的会执行保存当前任务状态、加载下一个任务状态、执行下一个任务等过程。任务的状态保存和再加载过程被称为上下文切换。而上下文切换会导致直接直接的性能消耗:状态和任务的加载、再加载,也包括间接的性能消耗:不同线程之间的数据共享等问题。
参考文献
- LINFO. Context Switch Definition [E]
- Wikipedia. 上下文交换 [E]
- rhwayfunn. Java并发编程系列之三十:多线程的代价 [E]