在计算机网络中,IP协议(Internet Protocol,互联网络协议)是TCP/IP协议簇中的核心协议,该协议作用于网络层,要求计算机通过遵循一套相同的规则,从而实现计算机之间可以相互通信。在网络层中,数据以IP报文的形式存在,报文通过IP地址标识来源和目的主机。当前IP地址普遍遵循的是第四版互联网络协议(Internet Protocol version 4)也就是IPv4,在该版本协议中,一台主机的IP地址以点分十进制(Dotted Decimal Notation)方式表示,同时按照<网络地址/网络号>+<主机地址/主机号>的方式进行寻址。其中,网络地址(网络号)表示当前主机所在的网段,主机地址(主机号)表示当前主机在其所在网段中的唯一ID。
为了便于对IP地址进行管理,IETF(Internet Engineering Task Force,互联网工程任务组)在RFC 791[1]中将IP地址定义为5种类型:
表 - 1:IP地址分类[2]
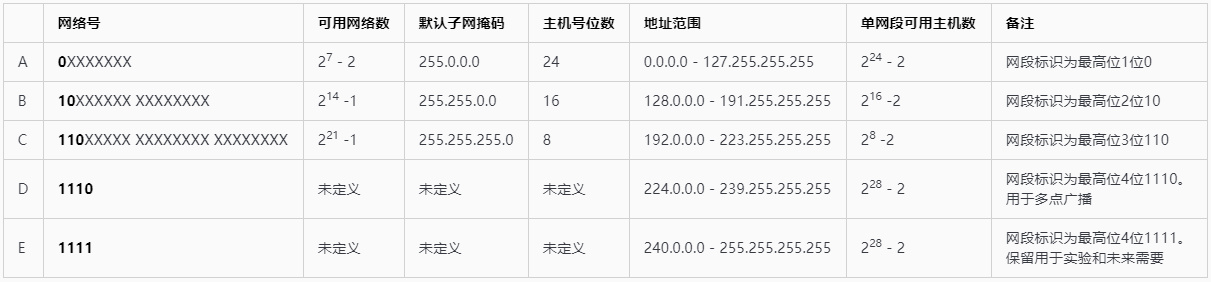
对于A类网络,网络号”X”部分全为0的IP地址是个保留地址,网络号”X”部分全为1的IP地址是个环回地址,保留用作本地软件环回测试本主机的进程之间相互通信,所以A类网络可用的网络数量为$ 2^7 $ - 2。对B类和C类网络而言,128.0.0.0和192.0.0.0也是不对外分配使用的[3],所以可用网络数量分别为$ 2^{14} $ -1和$ 2^{21} $ -1。
在每个类别的每个网段中,都有两个特殊的地址:
- 主机位全为0的网络地址;
- 主机位全为1的广播地址;
所以各个网段的可用主机号为$ 2^n $ (n为主机号位数)减去一个网络地址和一个广播地址,即为$ 2^n $ -2。

因此,诸如互联网名称与数字地址分配机构(ICANN,The Internet Corporation for Assigned Names and Numbers)等IP地址分配和管理机构会根据实际需求分配一个IP地址段给申请者,根据RFC791的描述,A类网络每个网段可容纳$ 2^{24} $ -2个主机,B类网络每个网段可容纳$ 2^{16} $ -2个主机,C类网络每个网段可容纳$ 2^8 $ -2个主机,如果申请者的需求小于A,B,C类网络各个网段的可用主机数,那么如果将整个网段全都分配出去,会造成IP地址的浪费,从而加剧IP地址的消耗速度。出于
- 节约IP地址避免浪费;
- 限制广播风暴的影响范围;
- 通过分隔网段的方式保证各个网络的安全性;
等目的,故在RFC 950[5]中定义了子网掩码的相关概念及操作流程,从而按照实际需要分配IP地址,使得分配后的IP地址数量能在满足实际需要的前提下最大程度的减少浪费。
子网及子网掩码
子网是对于IP地址网络的一种逻辑划分,把一个网段划分成两个及以上更小网段的过程就称为子网划分。划分子网后,寻址方式便由之前的<网络号>+<主机号>变成了<网络号>+<子网号>+<主机号>:
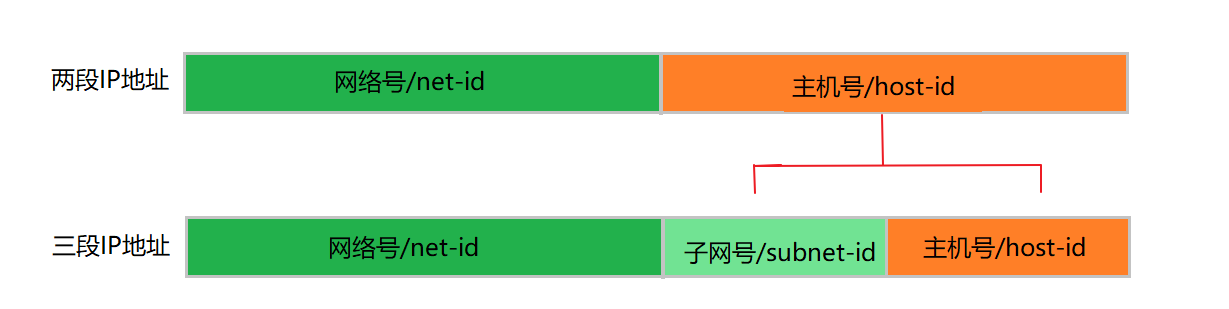
为了区分同一网段下的不同子网,需要使用子网掩码来进行区分。通常情况下,子网掩码由从左起若干个值为1的进制位表示。RFC950和RFC 1219[6]中指出,1进制位可以不连续,但是并不推荐这么做。需要注意的是,在RFC950中,子网号全为0或者1的子网是不会被实际分配使用的,但是在RFC 1878[8]废除了这个约定,所以本文也会遵照RFC 1878这个约定不再另行说明。在构成一个网段的所有子网段中,各个子网的子网掩码的长度是固定的,因此这种子网掩码也被称为FLSM(Fixed Length Subnet Masking)。子网掩码由如下的方式表示(以B类地址130.130.200.34为例):

鉴于在某些场景下这种表示方法可能有些繁琐和不便,可采用CIDR斜线记法在IP地址后加“/n”表示当前IP地址所对应的子网掩码值,n为从主机号中“借走”的位数,在此例中n为4。故图 - 3的子网掩码可表示为130.130.200.34/20,这里的“/20”表示子网掩码由自左向右连续的20个1进制位和12个0进制位表示。
在得知子网掩码后,便可以根据IP地址和子网掩码计算该地址所处的子网和在子网中的主机号,子网号的具体计算方法如下:
1 | IP地址点分十进制表示法:130. 130. 200. 34 |
当前IP地址在所处子网中的对应主机号计算方法如下:
1 | IP地址点分十进制表示法:130. 130. 200. 34 |
一般情况下,会有两种子网划分的分配场景:根据期望的子网数进行划分和根据每个子网区域内期望的主机数进行划分。下面会以一个B类地址为背景说明这两种场景是如何进行子网划分的。
根据期望的子网数进行划分
当给定期望的子网数x后,计算得到一个能使$ 2^n $大于等于x的最小整数n,此时这个n值就是需要从主机号位数中借出来用作子网划分的位数。
e.g. 1. 给定一个B类地址,默认子网掩码是255.255.0.0
期望得到一个包含有6个子网的B类网络,那么x=6,由此可得能使$ 2^n $大于等于6的最小整数n=3,所以实际的子网掩码是255.255.224.0。由于在子网划分时从主机位借走了n=3位,所以实际的主机位数为16 - 3 = 13,那么当前的每个子网可容纳$ 2^{13} $个主机,其中有效主机数为$ 2^{13} $ - 2。
根据单个子网内期望的主机数进行划分
当给定单个子网内期望的主机数x时,计算得到一个能使$ 2^n $大于等于x + 3的最小整数n,此时这个n值就是目的子网需要的主机号位数,而用来进行子网划分的位数N = 主机位数 - n(PS:主机位数等于当前地址对应的主机号位数)。这里的“+ 3”表示除了实际需要的主机数外,还需要包含一个主机号全为0的网络地址,一个主机号全为1的广播地址和一个网关地址。
e.g. 2. 给定一个B类地址,默认子网掩码是255.255.0.0
由于某些原因,每个网段能容纳的主机数为49,那么x=49,由此可得能使$ 2^n $大于等于49 + 3的最小整数n=6,划分后每个子网可用主机数为62。所以划分到子网号部分的二进制位数N = 16 - 6 = 10,所以实际的子网掩码是255.255.255.192。
子网划分虽然可以通过将一个大的网段划分成若干个小的网段来更加高效的使用IP地址资源,但是子网划分也带来了一些缺点和不足:
- 网络复杂性提高
子网划分实施后,有可能使得划分前处在同一个网段的的IP地址在划分后处在两个不同的网段,尤其是当IP地址相邻时。这使得网络的复杂度和维护成本显著提高。 - 通信成本开销上升
由于划分子网后,不同子网之间是无法直接通信的,必须通过网关等中间层实现相互通信,通信成本也会上升。 - 还是会造成可观的IP地址浪费
尽管实施了子网划分,但是划分出的每个子网的可用主机数量是相同的,实际中还是会出现某些子网的可用主机数量利用率高,而有些子网的可用主机数量利用率低的问题。
可变长子网掩码(VLSM)
可变长子网掩码(Variable Length Subnet Masking)[8]是为了更合理的利用IP地址资源而设计的一种可以多次进行子网划分以产生不同大小网络的网络分配机制。通过前面的介绍我们已经知道,固定长度子网掩码使得每个子网的子网掩码位数是相同的,每个子网包含的主机数也是相同的。一旦子网分配后,该子网内尚未使用的IP地址便无法供不属于当前子网所有者的主机使用,造成了浪费。通过应用VLSM可以最小程度的避免IP地址资源的浪费,在公共IP地址分类方面VLSM的优势更加明显。下面会通过一个例子来说明可变长度子网掩码是如何工作的。
背景:
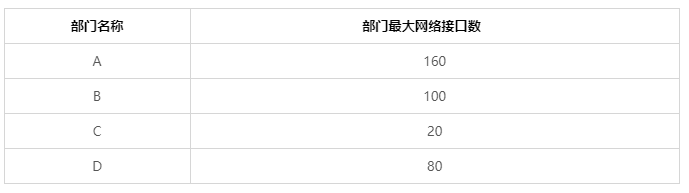
张三最近新成立了组织,需要构建组织的办公网络,于是向当地的互联网地址分配机构申请了一个B类地址130.130.0.0/16。这个组织有4个部门,部门概要如表 - 2所示:
于是乎,组织的网络划分架构实施过程如下:
- 首先根据从大到小的顺序将各个部门的网络接口数排序,结果是:
A(160) > B(100) > D(80)> C(20) 先对部门A进行子网划分
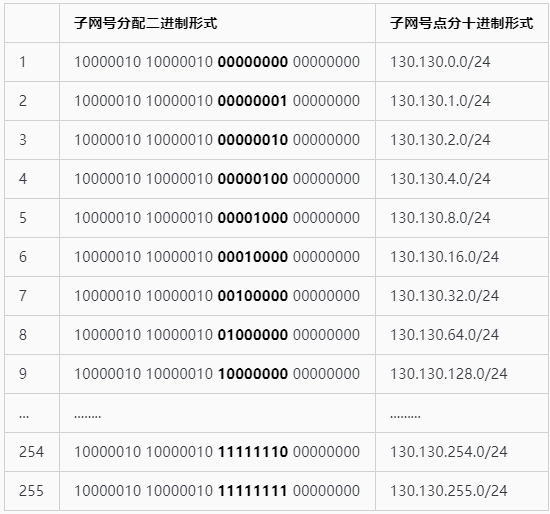
- A需要160个网络接口,根据公式 计算得到满足公式的最小整数n = 8,子网号占据16 - 8 = 8位。所以便把130.130.0.0/16划分成了如下的255个子网号: 表 - 3:子网划分及其子网号表示
- 部门A的网络规划配置如下
部门A的子网掩码:255.255.255.0
部门A的子网号:130.130.0.0/24(表 - 3中1号子网)
第一个可用地址为:130.130.0.1
最后一个可用地址为:130.130.0.254
可用地址数量:254
已用数量:160
剩余数量:94
- A需要160个网络接口,根据公式 计算得到满足公式的最小整数n = 8,子网号占据16 - 8 = 8位。所以便把130.130.0.0/16划分成了如下的255个子网号:
对部门B进行网络规划
B需要100个网络接口,在(2)中我们可知使用24位子网掩码时可以满足B的需求。我们选择将表 - 3中2号子网130.130.1.0/24分配给部门B并进行进一步的划分。尝试继续增加子网号位数,当子网掩码位数为25时,每个子网可容纳126个主机。所以对130.130.1.0/24做如下划分:
表 - 4:子网130.130.1.0/24的划分结果
- 部门B的网络规划配置如下:
部门B的子网掩码:255.255.255.128
部门B的子网号:130.130.1.0/25(表 - 4中1号子网)
第一个可用地址为:130.130.1.1
最后一个可用地址为:130.130.1.126
可用地址数量:126
已用数量:100
剩余数量:26
对部门D进行网络规划
- D需要80个网络接口,在(3)中我们知道可以使用和部门B相同的子网掩码位数,每个子网可容纳126个主机。所以将表 - 4 中2号子网130.130.1.128/25分配给部门D使用。
- 部门D的网络规划配置如下:
部门D的子网掩码为:255.255.255.128
部门D的子网号:130.130.1.128/25(表 - 4中2号子网)
第一个可用地址为:130.130.1.129
最后一个可用地址为:130.130.1.254
可用地址数量:126
已用数量:80
剩余数量:46
对部门C进行网络规划
C需要20个网络接口,故划分后主机位数为5位,子网位数为11位。所以将表 - 3中3号子网130.130.2.0/24分配给部门C并做出如下划分:
表 - 5:子网130.130.2.0/24的划分结果
- 部门C的网络规划配置如下:
部门C的子网掩码为:255.255.255.224
部门C的子网号:130.130.2.0/27(表 - 5中1号子网)
第一个可用地址为:130.130.2.1
最后一个可用地址为:130.130.1.30
可用地址数量:30
已用数量:20
剩余数量:10
综上所述,整个组织的网络规划配置如下:
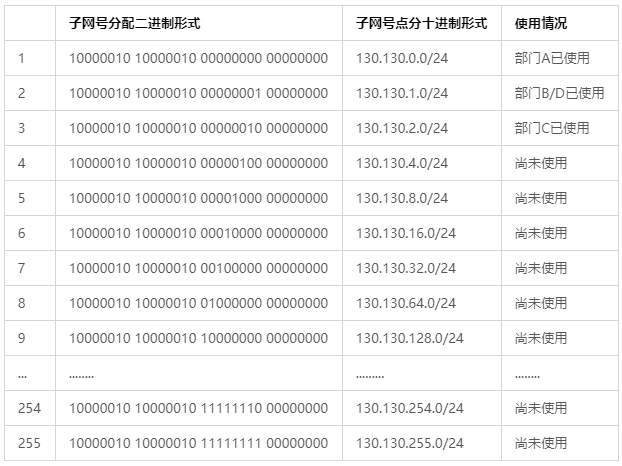
网络规划结束
需要注意的是,如果要使用VLSM对网络进行划分,那么包括但不限于路由器、网关等设施都需要支持VLSM。
无类别域间路由(CIDR)
标准的IP地址格式(也就是<网络号>+<主机号>格式)虽然简单易行,但是也有一些缺点,首先就是分配时很容易产生浪费,且这种浪费是不可再分配的。对于个人或者小型组织而言,一个C类网络很明显太大了,而对于多数企业而言又不太够。一个可容纳6万5千多台主机的B类网络很显然对大多数企业而言也会浪费很多IP地址资源。其次,不同网段之间相互通信需要建立路由表信息,随着网络数的增加,路由表的规模越来越大,对其进行有效维护变得越来越复杂。再加上IP地址耗尽等问题,ITEF尝试了一些优化和解决办法,其中一个就是于1993年提出的无类别域间路由技术。
无类别域间路由(Classless Inter-Domain Routing,CIDR /ˈsaɪdər, ˈsɪ-/) [9][10][11]是一种应用于IP地址分配和IP路由的方法和技术。ITEF期望通过CIDR取代早先的A/B/C类IP地址分类架构。CIDR的实现依赖于可变长子网掩码,借助于可变长子网掩码技术,CIDR可以使用自最高位起8 ~ 30位二进制位构建网络号前缀。前文提到的”X.X.X.X/N”表示法也是CIDR首先提出来的。CIDR通过路由聚合,使得若干个小的子网聚合一个更大的网络,即所谓的超网(Supernetting)[12][13],将路由表中的按照规则尝试合并为成更少的数目,缓解了路由表数量快速攀升的问题,减少路由通告,同时也相应的提高了网络通信的速度和性能。
CIDR以二进制位为单位、使用基于前缀的标准和规则来表示IP地址和路由表条目属性,它通过将多个IP地址块合并成组并映射到一条路由表条目来简化路由操作,减少了不必要的路由表条目冗余。这些合并成组的地址块被称为CIDR地址块,块内的每个IP地址自最高位起具有若干位相同的二进制位表示,采用“X.X.X.X/n”表示,“/n”表示自最高位起共n位是相同的。比如,“130.130.13.23/24”表示自最高位起24位是相同的IP地址共有$ 2^{32 - 24} $个。如果n越小,那么每个网段可用的IP地址越多,反之亦然。下面通过维基百科的一段说明来了解CIDR是如何工作的:
For example, in the late 1990s, the IP address 208.130.29.33 (since reassigned) was used by www.freesoft.org. An analysis of this address identified three CIDR prefixes. 208.128.0.0/11, a large CIDR block containing over 2 million addresses, had been assigned by ARIN (the North American RIR) to MCI. Automation Research Systems, a Virginia VAR, leased an Internet connection from MCI and was assigned the 208.130.28.0/22 block, capable of addressing just over 1000 devices. ARS used a /24 block for its publicly accessible servers, of which 208.130.29.33 was one. All of these CIDR prefixes would be used, at different locations in the network. Outside MCI’s network, the 208.128.0.0/11 prefix would be used to direct to MCI traffic bound not only for 208.130.29.33, but also for any of the roughly two million IP addresses with the same initial 11 bits. Within MCI’s network, 208.130.28.0/22 would become visible, directing traffic to the leased line serving ARS. Only within the ARS corporate network would the 208.130.29.0/24 prefix have been used.
— wikipedia
ARIN机构向MCI分配了一个208.128.0.0/11的CIDR地址块,这个地址块包含了超过200万个IP地址资源。Automation Research Systems从MCI申请接入互联网,得到了一个可以容纳超过1000台设备的网段,地址是208.130.28.0/22。ARS则申请得到了一个“208.130.29.0/24”的地址块。在MCI之外所有目的地址自最高位起11位与208.128.0.0/11相同的流量都会被转发到MCI,当流量到达MCI后,再根据自最高位起22位或者24位的匹配情况,决定是否将流量转发到Automation Research Systems或者ARS。

从上述例子中,我们看到原来需要2个及以上的全局路由表条目现在只需要一个到MCI的路由表条目就能完成流量路由和转发,大大减少了路由表条目的维护成本。所以可以将CIDR看做是子网划分的逆过程:子网划分通过向右划出二进制位给子网号部分使得子网数量增多,每个子网所包含的主机数量下降,而CIDR则向左归还二进制给主机位部分使得子网数量减少,单个子网的规模增加。二者看似截然相反,但是两者的目的和使用场景是完全不同的,所以二者本质上并无矛盾。实际上,两者只有结合起来才能更加灵活地进行IP地址资源分配,既保证IP地址利用率最大化,同时又保证了一定的网络通信性能和网络复杂度。
综上,由于IPv4地址结构的固有性质决定了IPv4地址资源的耗尽是一个不容忽视的问题。为了减缓IPv4地址资源消耗的速度和避免浪费,子网划分技术被提出并得到了广泛应用。子网划分可以固定长度的子网掩码进行,也可以采用可变长子网掩码技术,相较于固定长度子网掩码而言,可变长子网掩码技术更加灵活,能更好的避免IP地址资源浪费。但是子网划分带来的一个副作用就是需要为每个子网维护一个路由表条目,结果就是导致路由表规模越来越大,维护成本越来越高。为了解决这个问题,CIDR基于可变长子网掩码技术将多个小的子网聚合成一个大的超网,这些子网共享相同的指向超网的路由表信息和子网掩码,既保证了路由表条目不会增长太快,同时也保留了网络划分的灵活性。
参考文献
- 1.Postel, J., Internet protocol―DARPA internet program protocol specification, ITEF RFC 791, September 1981.
- 2.Wikipedia contributors. Classful network. Wikipedia, The Free Encyclopedia, 6 April 2021.
- 3.Comer, Douglas E. Internetworking with TCP/IP Vol. 1: Principles, Protocols and Applications, 6ed. Pearson, 2014.
- 4.Postel, J., Address Mappings, ITEF RFC 796, September 1981.
- 5.Mogul J., and J. Postel, Internet Standard Subnetting Procedure, STD 5, ITEF RFC 950, Stanford, USC/Information, August 1985.
- 6.Tsuchiya, P. F. On the assignment of subnet numbers, ITEF RFC 1219, April 1991.
- 7.Wikipedia contributors. Subnetwork. Wikipedia, The Free Encyclopedia, 14 April 2021.
- 8.Pummill, T., and B. Manning. Variable Length Subnet Table For IPv4, ITEF RFC 1878, December 1995.
- 9.Wikipedia contributors. Classless Inter-Domain Routing. Wikipedia, The Free Encyclopedia, 20 April 2021.
- 10.Fuller, Vince, et al. Classless inter-domain routing (CIDR): an address assignment and aggregation strategy, ITEF RFC 1519, September 1993.
- 11.Rekhter, Y., and T. Li. An Architecture for IP Address Allocation with CIDR, ITEF RFC 1518, September 1993.
- 12.Wikipedia contributors. Supernetwork. Wikipedia, The Free Encyclopedia, 1 Febuary. 2021.
- 13.Fuller, Vince, et al. Supernetting: An address assignment and aggregation strategy, ITEF RFC-1338, June, 1992.