Kubernetes网络是Kubernetes得以正常工作的重要基础之一,这其中涉及到了包括但不限于IP地址划分、MAC地址学习、路由转发、服务发现、网络通信等诸多领域。借助于CNI接口及其实现产品,Kubernetes可以提供丰富的网络配置架构方案。关于Kubernetes网络,将会有一系列笔记,本篇是第一篇—关于Kubernetes网络模型和策略的初步学习,知其然,稍微知其所以然。出于篇幅考虑,相关的yaml配置不会在文章中出现,特殊情况除外,相关的yaml配置可以参考Kubernetes官方文档。
2. K8s network之二:Kubernetes的域名解析、服务发现和外部访问
4.K8s network之四:Kubernetes集群通信的实现原理
5.K8s network之五:Kubernetes集群Pod和Service之间通信的实现原理
网络模型
Kubernetes网络模型遵循的一个核心原则是每个Pod都拥有一个唯一且独立的IP地址,只要彼此通信的Pod在同一个集群里,那么就可以通过IP地址的方式实现Pod间的直接访问而无需借助其他工具和手段,即使它们不在同一个node节点上。也就是说,同一个集群里的所有Pod形成了一个扁平的、可相互通信的网络组织。于是乎,每个Pod可以像虚拟机或者物理机实体那样执行诸如端口分配、命名、服务发现、负载均衡、应用配置和迁移等动作。因此,基于这个核心原则建立的模型就是“IP-Per-Pod”模型。
IP-Per-Pod模型认为,Pod之间会通过目标方的IP地址来完成通信和交互行为,无论是在Pod的内部还是外部,这个Pod的IP地址、端口等信息都是一致的,因此,Pod内部和外部之间、Pod和Pod之间、Node和Pod之间也就不再需要NAT操作来确保通信成功。没有了NAT之后,整个集群的通信性能会更好,源地址伪装的情况也就不复存在,因此具备了源地址可溯源的能力,对于集群维护和排障都有非常重要的帮助。而且这个模型可以很好的兼容现有的应用架构,如果我们的应用是运行在虚拟机上,每个虚拟机有自己的IP地址而且彼此之间可以相互通信,那么这个应用就可以很容易的迁移到Kubernetes集群上,降低成本和风险。这个模型还有另外一个好处,那就是同一个Pod内的容器之间共享了同一个网络命名空间,这些容器之间通过同一个IP地址对外发送消息,通过同一个IP地址接收来自Pod之外的消息。它们相互之间的访问可以通过localhost加端口的形式直接访问。在整个集群范围内,每个Node都有一个与其他Node节点无交集的IP地址段,这个IP地址段内的IP地址会拿来分配给该节点上的Pod使用。
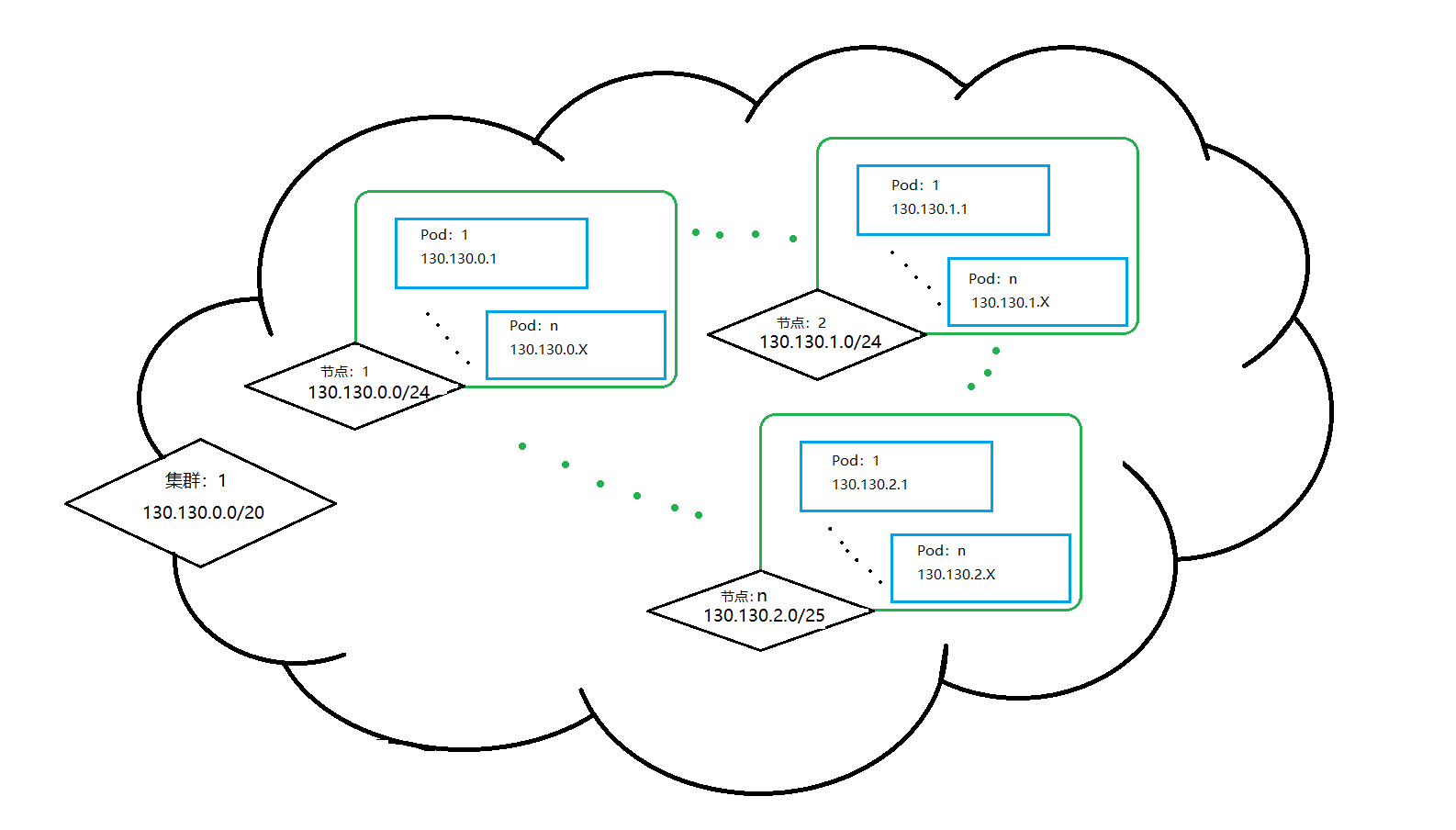
为了保证集群的正常运行和工作,Kubernetes对集群网络提出了如下的要求:
- 任意节点上的Pod可以在不借助NAT的情况下与任意节点上的任意Pod进行通信;
- 节点上的代理(诸如系统守护进程、kubelet等)可以在不借助NAT的情况下与该节点上的任意Pod进行通信;
- 处于一个节点的主机网络中的Pod可以在不借助NAT的情况下与任意节点上的任意Pod进行通信(当且仅当支持Pod运行在主机网络的平台上,比如Linux等);
- 不论在Pod内部还是外部,该Pod的IP地址和端口信息都是一致的。
在上述要求得到保证后,Kubernetes网络主要聚焦于两个任务—IP地址管理和路由,并致力于解决如下问题:
- 同一个Pod内多个容器之间如何通信
- 同一个Node节点中多个Pod之间如何通信
- 不同Node节点上的多个Pod之间如何通信
- Pod和Service之间如何通信
- Pod和集群外的实体如何通信
- Service和集群外的实体如何通信
Container Network Interface(CNI)
众所周知,Kubernetes是由Google开源并维护的一个容器编排工具,是Google十多年容器技术应用经验的集大成之作。于是乎,支撑Kubernetes正常工作的公有云GCE(Google Compute Engine Network)自然满足上述提及的各种要求。但并非所有的Kubernetes集群都部署在GCE、AWS、Azure等公有云环境上,私有云的部署方案也日渐增多。在这种情况下,如何保证集群网络可以满足Kubernetes的要求就成为了一个首要问题。换句话说,Kubernetes仅关注和负责容器编排领域的相关事宜,而网络管理并不是它最核心的分内之事。起初,Kubernetes通过开发Kubenet来实现网络管理功能以提供满足要求的集群网络。Kubenet是一个非常简单、基础的网络插件实现。但它本身并不支持任何跨节点之间的网络通信和网络策略等高级功能,且仅适用于Linux系统,所以Kubernetes试图找到一个更优秀的方案来替代Kubenet。为了解决这个问题,CoreOs公司和Docker各自推出了CNI(Container Network Interface)和CNM (Container Network Model)规范,CNI以其完善的规范和优雅的设计击败了CNM,并成为了Kubernetes首选的网络插件接口规范。
CNI的基本思想是在容器运行时环境中创建容器时,先创建好网络命名空间(netns),然后调用CNI插件为这个网络命名空间配置网络,之后再启动容器内的进程。CNI通过Json Schema定义了容器运行环境和网络插件之间的接口声明,描述当前容器网络的配置和规范,尝试通过一种普适的方式来实现容器网络的标准化 。它仅专注于在创建容器时分配网络资源(IP、网卡、网段等)和在容器被回收时如何删除网络资源两个方面的能力。CNI作为Kubernetes和底层网络之间的一个抽象存在,屏蔽了底层网络实现的细节、实现了Kubernetes和具体网络实现方案的解耦,继而为Kubernetes建立一个满足其运行要求的网络组织结构,同时也克服了Kubenet不能实现跨主机容器间的相互通信等不足和短板。CNI凭借其轻便、实现成本小等优点,成功地被Kubernetes、rkt、Apache Mesos等项目所认可和采纳,各个公司和社区也发布了包括但不限于Flannel、Calico、Weave等CNI规范实现方案,进一步增强了CNI规范的影响力。
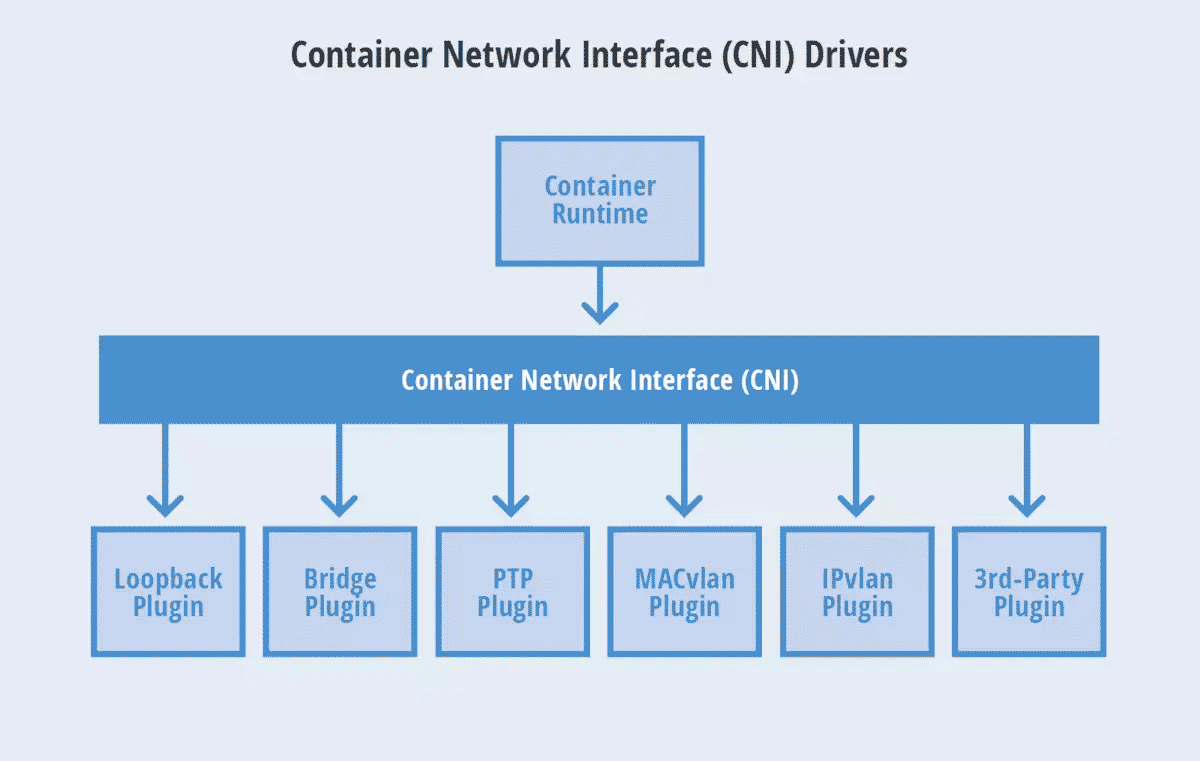
如前所述,CNI规范只是一个规范,规定了如何连接容器编排系统(比如K8s)和网络插件以完成Pod网络管理。实际执行Pod网络管理的是遵循CNI规范的各个CNI网络插件,目前官方提供的CNI网络插件包括如下三类[2]:
Main: interface-creating
- bridge: 创建一个桥接网络,并将宿主机和容器加入到这个桥接网络中
- ipvlan: 在容器中加入一个ipvlan接口
- loopback: 设置环回接口的状态为up状态
- macvlan: 创建一个新的mac地址,并将所有到该地址的流量转发到容器
- ptp: 创建一个新的veth对
- vlan: 分配一个vlan设备
- host-device: 将宿主机现有的网络接口移到容器内。
IPAM: IP address allocation
- dhcp: 在宿主机上运行一个daemon进程并代表容器发起DHCP请求。
- host-local: 维护一个已分配IP的本地数据库
- static: 向容器分配一个静态的IPv4/IPv6地址,这个地址仅用于调试目的。
Meta: other plugins
- flannel: 根据flannel配置文件生成一个网络接口
- tuning: 调整一个已有网络接口的sysctl参数
- portmap: 一个基于iptables的端口映射插件,将宿主机地址空间的端口映射到容器中
- bandwidth: 通过流量控制工具tbf来实现带宽限制
- sbr: 为接口配置基于源IP地址的路由
- firewall: 一个借助iptables或者firewalld来添加规则来限制出入容器流量的防火墙插件。
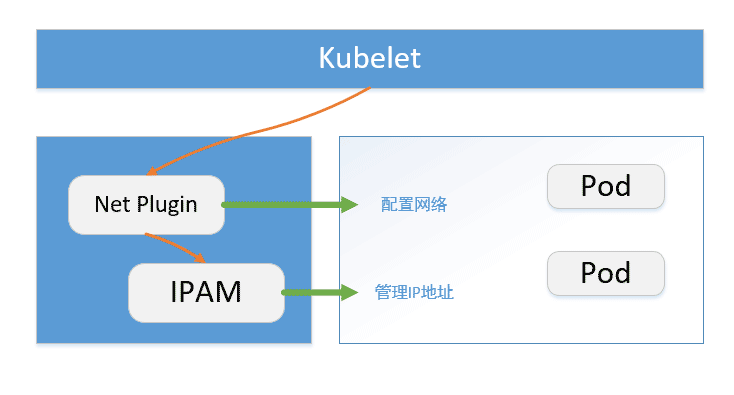
针对这三种类型的插件,官方都提供了一些内置的实现方案可供用户直接使用。Main插件也称为“网络插件(NetPlugin)”,它是一个由容器编排系统调用的可执行文件,实现某种特定的网络功能,负责创建/删除网络、向容器的网络空间插入一个网络接口以及向网络添加/删除容器,专注于连通容器与容器之间以及容器和宿主机之间的通信。
为网络接口分配和维护IP地址以及配置与该接口相关的路由信息是CNI插件的一个重要职责,这使得CNI插件变得更加灵活的同时也带来了很大的负担。诸多CNI插件为了向用户提供期望的IP管理功能(诸如DHCP、HOST-LOCAL等)可能会使用相同的代码实现。为了减轻CNI插件的负担,也为了让IP管理策略和前述的NetPlugin插件的职责和功能相互独立,于是便定义了一种新的插件类型—IPAM(IP Address Management)。IPAM不提供网络功能,仅负责创建/删除IP地址池以及分配/回收容器的IP地址。IPAM由Main插件调用,并向Main插件提供接口的IP、子网、网关、路由等信息,与Main插件协同完成工作。IPAM的独立使得各个网络插件可以基于自己的实际需要和期望选择最适合自己的IPAM策略。
和Main插件一样,IPAM也是一个可执行文件,通过变量CNI_PATH指定IPAM的二进制文件位置,和Main插件共享相同的环境变量,并且通过stdin和stdout接收网络配置和返回结果输出。如果执行结果是成功状态,那么会返回一个0标识执行状态,并将成功执行的结果类型输出到stdout。
Meta插件不实现任何网络功能,不参与IP地址分配和回收,它调用其他网络工具或者插件完成一些管理或者测试功能。
在上述的三个插件中,Main插件是最重要的一个,由它来完成创建虚拟网络、为Pod生成网络接口设备、将Pod接入网络等核心任务。除了上面的提到的几种内置实现方案,诸多公司和社区也提供了遵循CNI规范的第三方插件实现,他们中的大多数属于Main插件类型,致力于提供Netplugin功能,用来提供配置容器接口和网络。也有不少方案甚至能够支持Kubernetes的网络策略。这些第三方插件实现常用的网络架构有Overlay网络和Underlay网络两大类:
- Overlay 网络: 一个建立在现有物理网络之上的虚拟的、逻辑的网络。Overlay网络是建立在已有物理网络上的虚拟网络,具有独立的控制和转发平面,对于连接到Overlay的终端设备(例如服务器)来说,物理网络是透明的,从而可以实现承载网络(物理网络)和业务网络(逻辑网络)的分离。
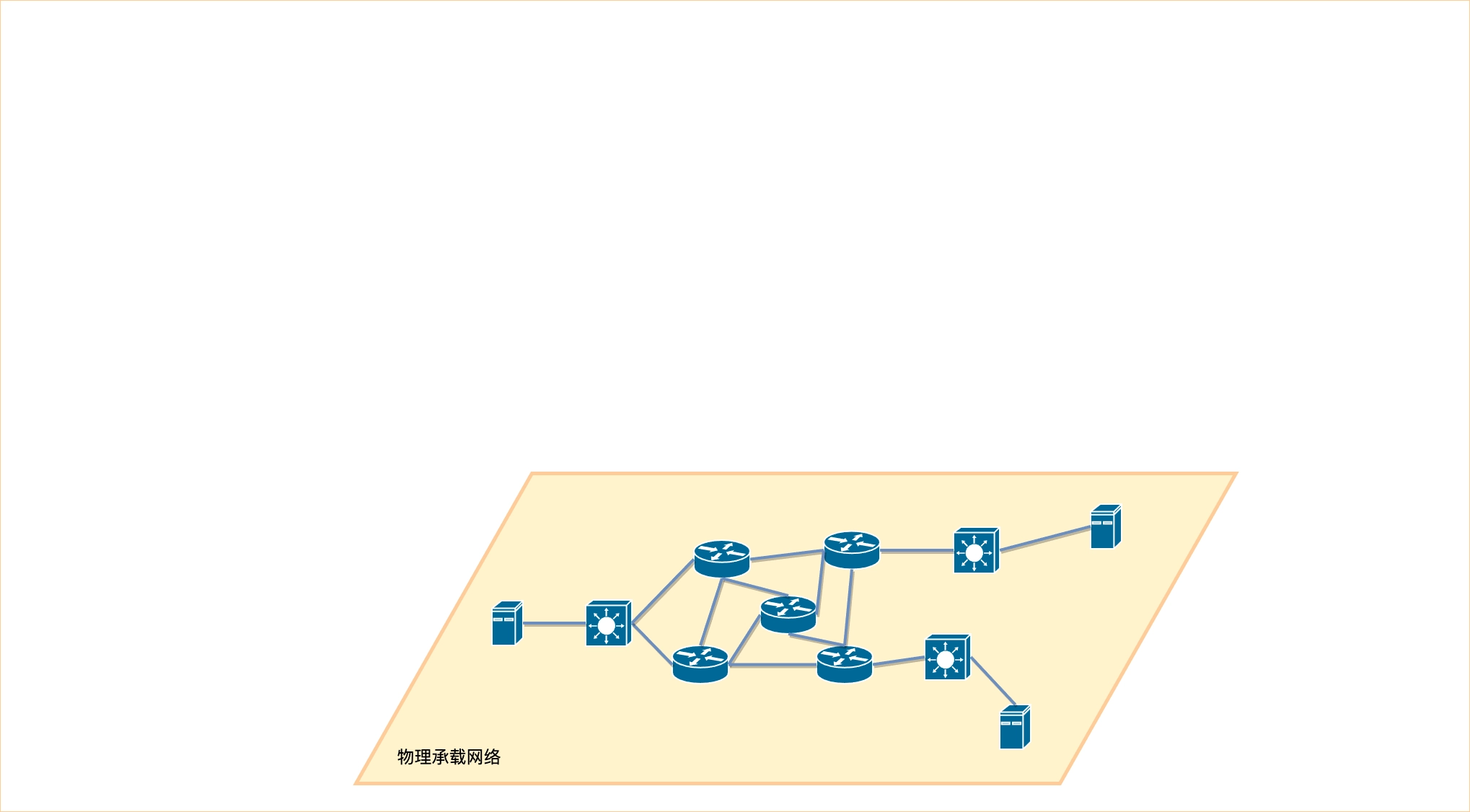
- Underlay 网络:就是传统IT基础设施网络架构,由交换机、路由器、网关等设备主组成,借助以太网协议、路由协议和VLAN协议等诸多协议完成网络通信和维护。此外,它还是Overlay网络的底层支撑网络,为Overlay网络提供数据通信服务。在容器技术中,Underlay网络特指借助驱动程序将宿主机的底层网络接口直接暴露给容器使用的一种网络构建技术,常用的实现方案包括MacVLAN、IP VLAN 和直接路由等。
Overlay借助VXLAN、UDP、IPIP、GRE等隧道协议建立通信隧道,通过隧道协议报文封装边缘设备之间的通信报文(二层的以太网帧或者三层的IP数据包)来构建虚拟网络。隧道转发数据的实质就是将通信设备的通信报文封装成各自边缘设备之间的报文,通过建立在边缘设备之间的网络隧道完成数据传输。这种方案只需要相互通信的边缘设备之间支持隧道协议即可,对底层网络没有任何特殊要求。Overylay网络通常由两个平面构成:控制平面和数据平面。控制平面专注于如下三个职责:
- 服务发现。边缘设备如何感知其他边缘设备的存在,以便建立Overlay隧道
- 地址通告和映射。边缘设备如何交换其学习到的可达信息(包括但不限于Mac、IP以及其他相关地址信息)
- 隧道管理。这里需要SDN控制器的参与,由于SDN控制器了解整个网络的拓扑结构,便可以实现基于控制器的地址学习,提高了可靠性和扩展性
而Overlay的数据平面则提供数据封装功能,并通过底层的物理承载网络实现数据传输。
上述协议中,VXLAN(Virtual Extensible LAN,虚拟可扩展局域网)是目前最流行的构建Overlay网络隧道的协议之一,是由ITEF定义的NVO3(Network Virtualization Over Layer 3)标准技术之一,采用L2 over L4(MAC-in-UDP)的报文封装格式,将二层报文用三层协议进行封装,依托UDP层构建overlay逻辑网络,使逻辑网络与物理网络解耦,满足快速变化的组网需求。VXLAN这类隧道网络的一个特点是对原有的网络架构影响小,不需要对原网络做任何改动,就可在原网络的基础上构建一层新的网络。VXLAN有点类似于VLAN,但是提供了比VLAN更好的灵活性和能力,相较于VLAN最多只能提供4096个网络ID而言,VXLAN可以提供最多16777216个网络ID(即 $2 ^ {24}$)。VXLAN的基本模型如下图所示:
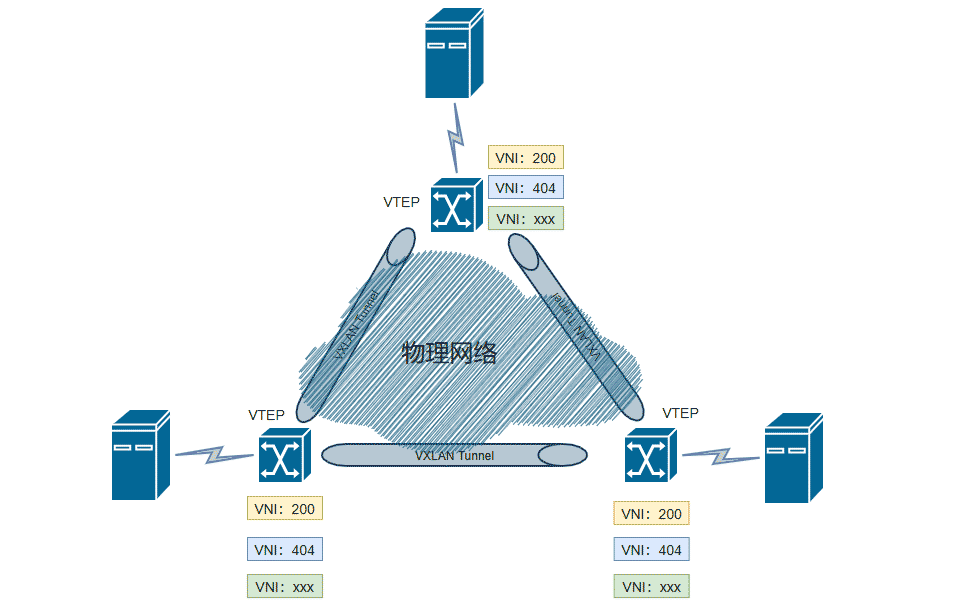
VXLAN主要有如下几个部分/概念组成:
- VTEP(VXLAN Tunnel End Point,VXLAN隧道端点)。VTEP是隧道的端点设备,由VTEP负责建立隧道。VXLAN的相关处理都在VTEP上进行,包括但不限于识别数据帧所属的VXLAN,数据帧的封装/解封装等。每个VTEP提供两个接口,一个接口负责本地主机桥接供能,另一个连接物理核心网络提供隧道建立和VXLAN封装/解封装等服务。
- VNI(VXLAN Network Identifier,VXLAN网络识别号)。用来标识一个二层网络分段,一个VNI代表一个VXLAN网络段,可以分配一个用户/租户使用。不同的VNI之间不能直接通信。VNI的范围最大可达16777216(即 $2 ^ {24}$)。
- VXLAN Tunnel。隧道是一个物理上没有对应实体的逻辑概念,两个VTEP设备之间建立隧道后便可以认为它们在直接通信。VXLAN报文在隧道之间传输。
- BD(Broadcast Domain,广播域)。用来在VXLAN中划分广播域,在同一个广播域中的设备可以直接进行二层通信。同时,一个VNI映射一个BD。
和其他协议一样,VXLAN在工作过程中也需要遵循一定的规范。在RFC 7348 [3]中,给出了VXLAN报文的格式规范:

Inner Ethernet Header和Payload属于原生的二层以太网帧结构。

VXLAN在正式通信之间需要先保证VTEP之间相互了解对方的存在及地址等相关信息。特别是当VTEP之间是首次通信时,由于本地的MAC表中并没有维护对方的MAC地址信息,所以需要通过ARP请求来进行MAC地址的学习。如果两个VTEP处于同一个VNI时,MAC学习过程如下:
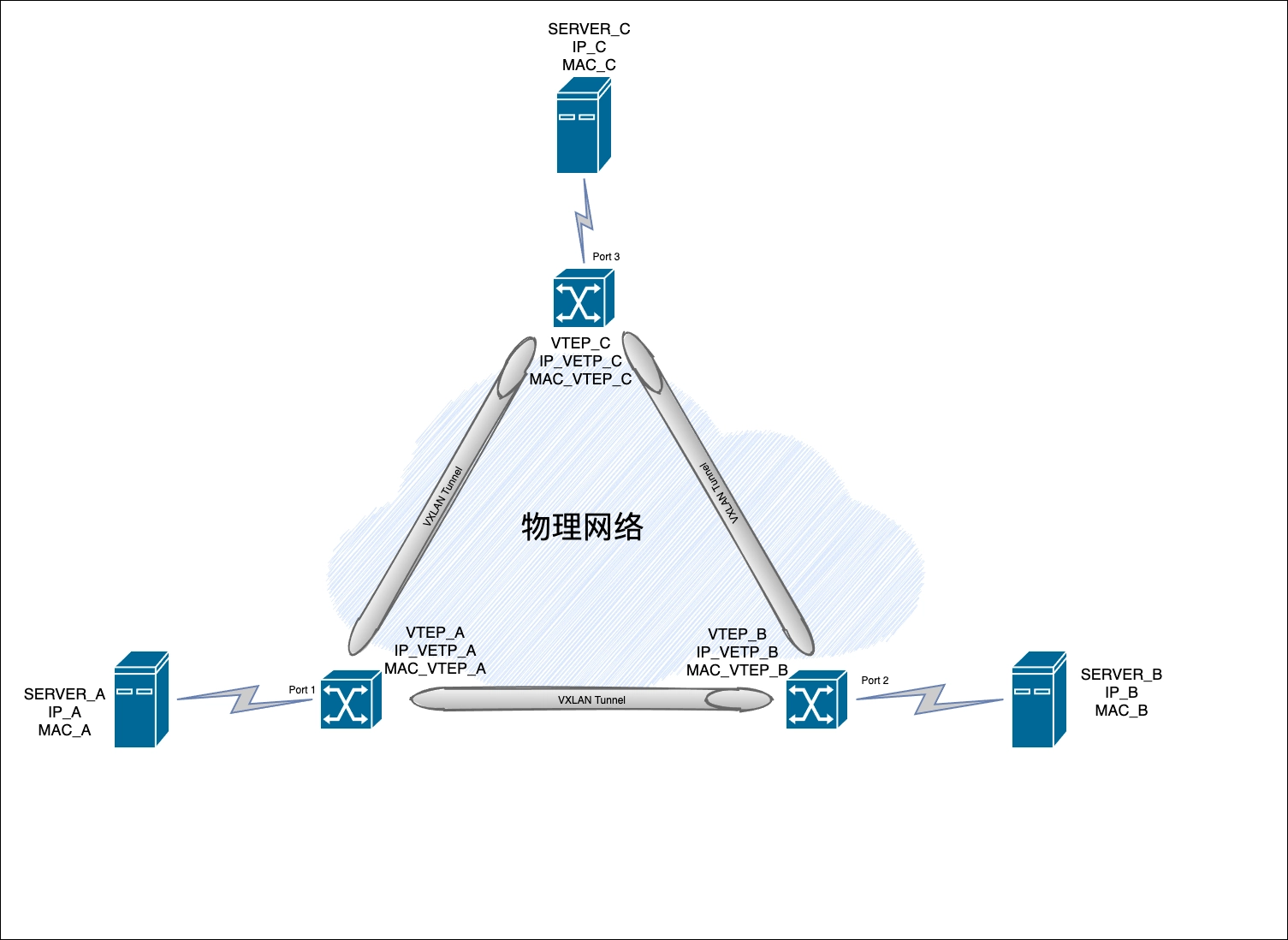
在完成MAC学习后,VTEP设备之间即可根据学习到的MAC地址信息相互通信。
如果两个VTEP不在同一个VNI时,需要借助三层网关设备完成通信操作,具体流程如下:
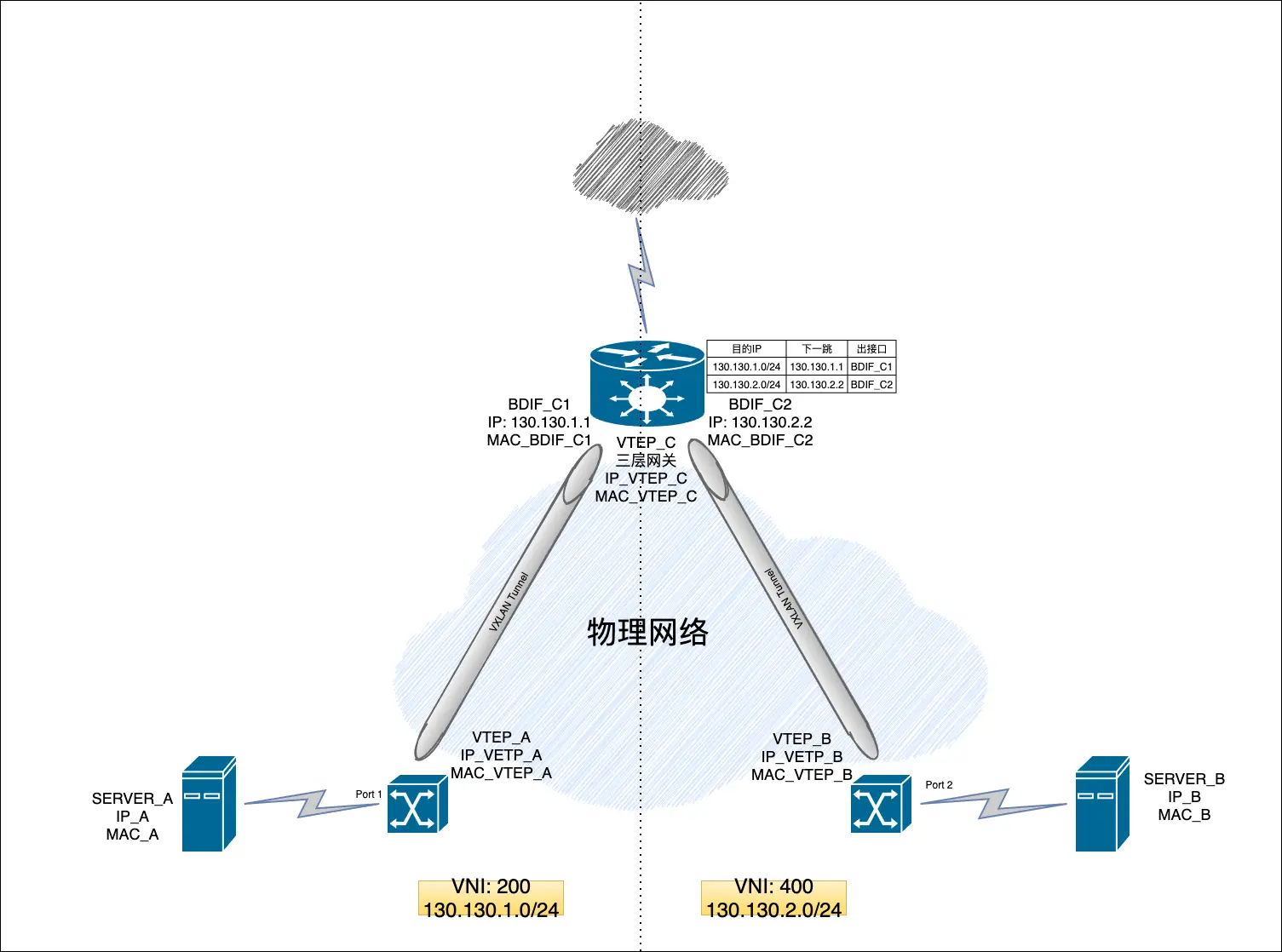
Kubernetes目前支持两种网络插件的实现:
CNI插件:根据CNI规范实现其接口,以与插件提供者进行对接。
kubenet插件:使用bridge和host-local CNI插件实现一个基本的cbr0。
为了在Kubernetes集群中使用网络插件,需要在kubelet服务的启动参数上设置下面两个参数:
- —network-plugin-dir:kubelet启动时扫描网络插件的目录。
- —network-plugin:网络插件名称,对于CNI插件,设置为cni即可,无须关注—network-plugin-dir的路径。对于kubenet插件,设置为kubenet,目前仅实现了一个简单的cbr0 Linux网桥。
在设置—network-plugin=”cni”时,kubelet还需设置下面两个参数。
- —cni-conf-dir:CNI插件的配置文件目录,默认为/etc/cni/net.d。该目录下配置文件的内容需要符合CNI规范。
- —cni-bin-dir:CNI插件的可执行文件目录,默认为/opt/cni/bin。
Kubernetes借助CNI插件体系组合满足需要的网络插件完成网络配置和维护功能。在创建或删除Pod时,Kubelet在默认的—cni-conf-dir目录下查找JSON格式的CNI配置文件,基于该配置文件中各插件的type属性(指明要调用的网络插件的名称)到—cni-bin-dir中查找相关插件的二进制可执行文件,执行它们以完成创建虚拟设备接口到相关的底层网络、为其设置IP地址、路由信息并将其添加到Pod的网络命名空间等操作。
在创建Pod的过程中,当Scheduler选定了一个Node节点来运行新创建的Pod时,该节点上的kubelet收到消息后会完成一个Pod的创建工作,当涉及到网络部分时,它首先会读取刚才我们所说的配置目录中的配置文件,获得将要使用的插件的相关信息。然后进入插件的可执行文件的目录来执行指明的 CNI 插件的二进制文件,由 CNI 插件进入 Pod 的网络空间去配置 Pod 的网络。
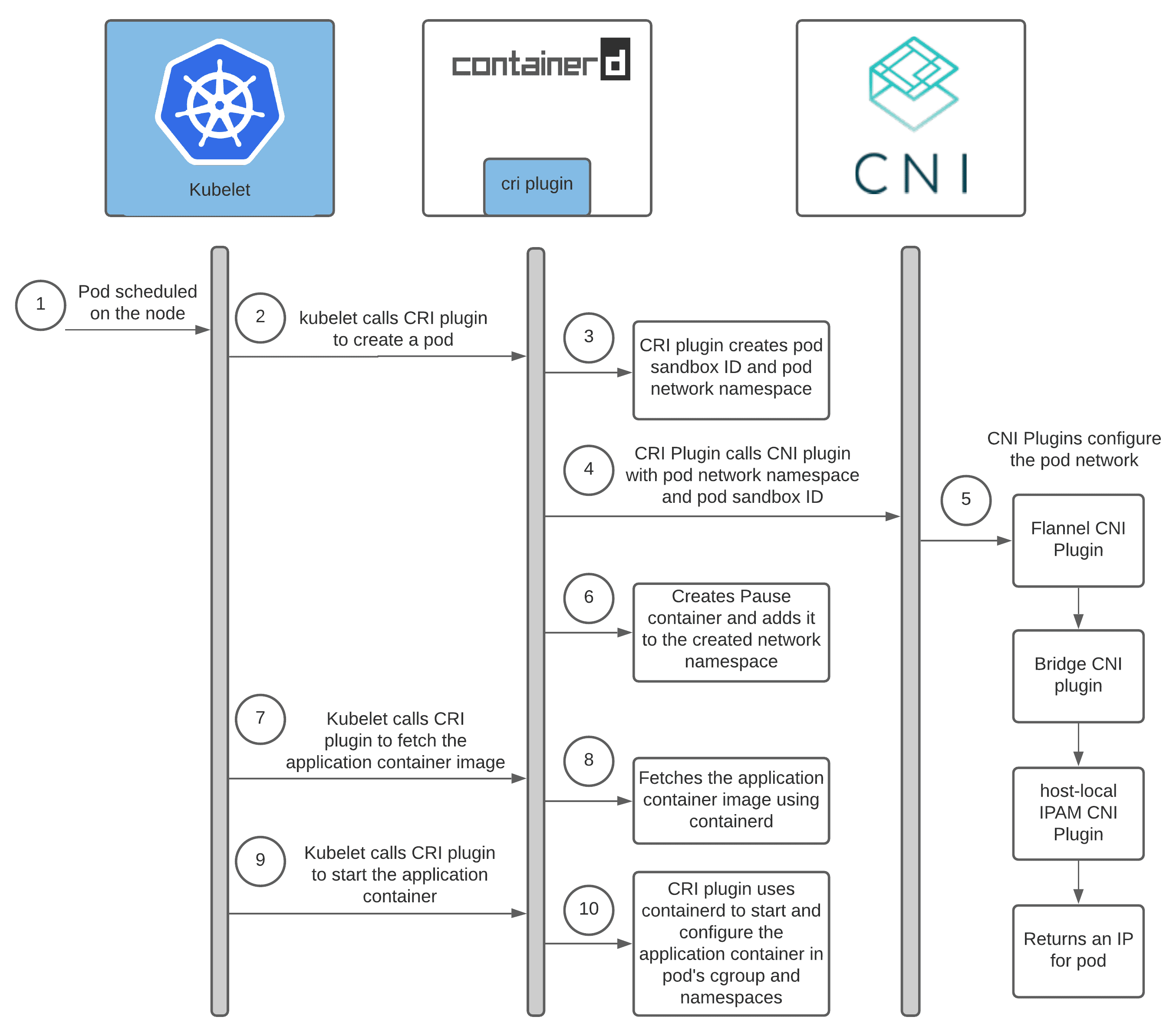
在面对诸多的CNI插件实现时,我们需要结合自身的实际情况和未来期望来选择一个最合适我们自己的产品。在进行评估时可以从如下角度来选择:
应用场景
虚拟化环境
虚拟环境(以OpenStack为例)因实现方案不同可能会对网络产生很多限制,比如不允许L2访问、限制机器可以使用的IP范围等。在这种网络限制比较严格的环境中,Overlay插件是更好的选择。常见的包括但不限于Flannel-vxlan, Calico-ipip, Weave等。
物理机环境
物理机因为是真实的物理环境,对网络的限制相较于虚拟化环境来说会宽松很多。所以除了Overlay之外也可以选择Underlay或者直接路由模式。这种环境下可以考虑Calico-bgp等。
公有云环境
公有云通常会考虑适配容器来提高容器性能,因此会提供一些CNI插件来实现兼容和性能最大化。如果有,选择公有云提供的CNI插件会是更优解。
功能需要
安全相关
尽管Kubernetes原生支持网络策略(Network Policy),但是不是所有的CNI插件都实现了这个功能。所以如果需要网络策略的相关服务,就可以过滤掉那些不支持网络策略的插件了。常见的支持网络策略的插件包括但不限于Calico、Weave等。
是否需要与集群外通信
如果Kubernetes上的应用有对应的非容器化版本,或者说Kubernetes上的应用需要和非云环境下的应用通信,那么就需要考虑集群外通信能力。此时就需要考虑Underlay网络架构而非Overlay网络架构。sriov-cni保证了Pod和虚拟机或者物理机可以在同一层网络,Calico的BGP模式实现了处于不同网段的集群网络和非集群网络(物理机、虚拟机)可以通过BGP路由机制实现相互通信。
是否需要Kubernetes的服务发现和负载均衡能力
Kubernetes的Service机制实现了高效的服务发现和负载均衡机制,但并非所有的CNI插件都能支持这两种能力。
性能考量
Pod的创建性能
Pod的创建性能限制了在诸如业务高峰等场景下需要紧急扩容来应对海量流量以及创建大量Pod的能力。Overlya和直接路由模式只需要通过调用内核接口就可以执行虚拟化操作完成创建Pod所需要的网络组件,所以速度会非常快。相反,Underlay需要创建所需的底层物理网络资源,所以相对来说会慢一些。
Pod的网络性能
由于Overlay网络在相互通信时需要额外的封装/解封装操作,以及由此带来的一些资源开销,所以传输性能会差一些。如果对这些开销敏感,那么就需要考虑Underlay网络或者路由模式。
网络策略
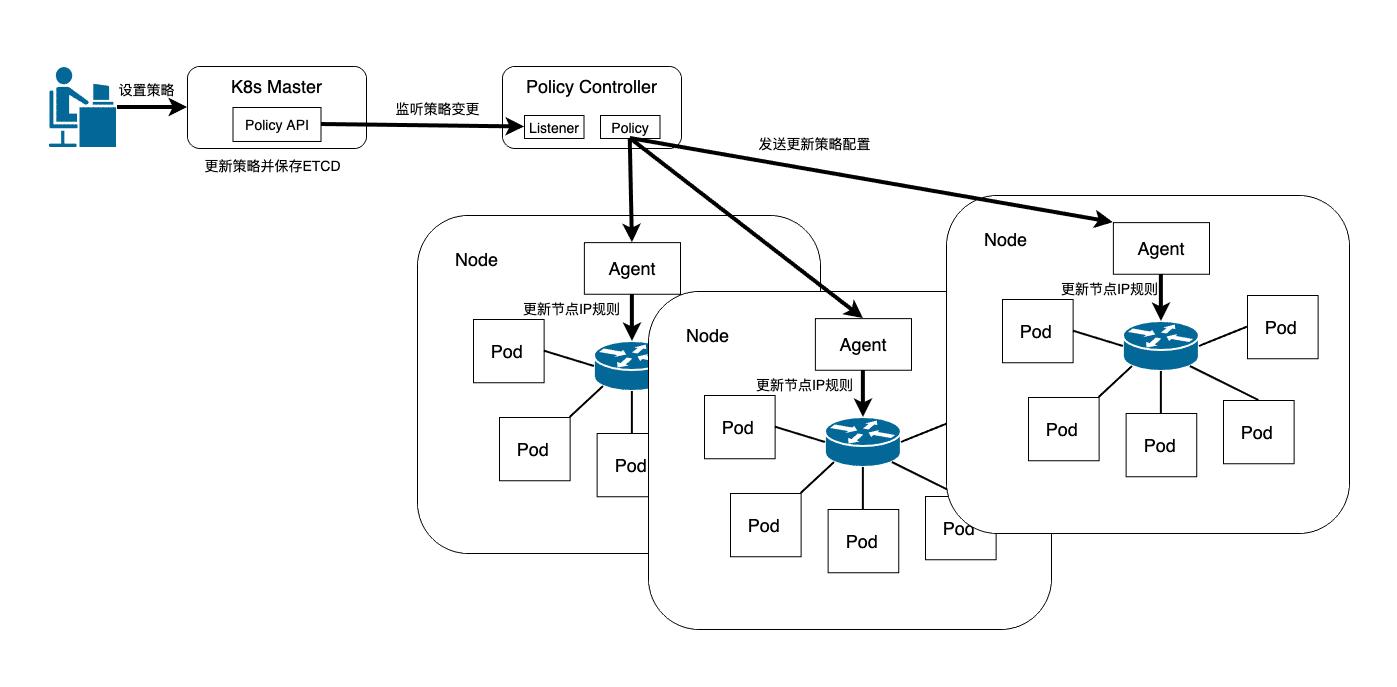
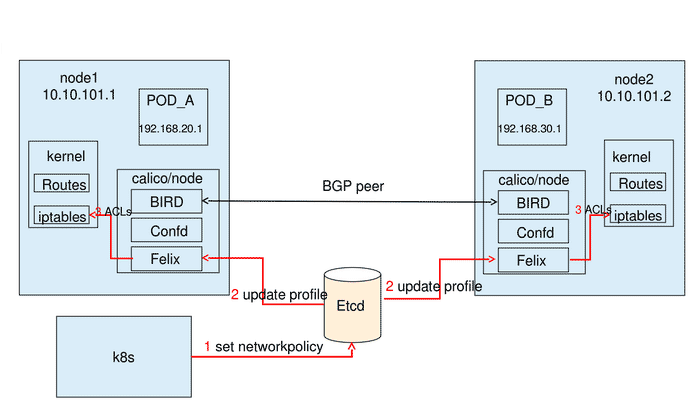
在Kubernetes中,所有的Pod之间默认是允许通信的,但是在实际的生产业务中普遍存在允许满足某些条件的Pod访问的同时拒绝满足另一些条件的Pod的访问,这个时候就需要引入Network Policy(网络策略)来提供Pod访问的准入控制。Kubernetes从v1.3开始引入NetworkPolicy资源对象来定义网络策略,使得Kubernetes可以在IP地址/端口级别(OSI第三/四层)实现更为精细的流量控制,实现租户隔离机制。与此相对应的,还需要有一个Policy Controller(策略控制器)协作完成实际的网络准入控制。需要注意的是,控制器的实现是由第三方网络组件而非Kubernetes完成的,目前Calico、Cilium、Kube-router、Romana、Weave Net等开源项目均支持网络策略的实现。就Kubernetes暴露的API而言,Kubernetes的网络策略实现了如下特性:
- 策略可以是命名空间级别的
- 策略通过标签选择器作用于Pod上
- 策略规则可以基于Pods、命名空间、CIDR进行设置
- 策略规则可以基于协议(TCP/UDP/SCTP)、端口号进行设置(注:SCTP自Kubernetes v1.12后支持)
网络策略规定Pod的流量分为流入流量(Ingress)和流出流量(Egress)两个类型,每个类型的流量有允许通过和禁止通过两个动作。默认情况下(也就是没有设置任何网络策略)Pod之间可以任意互联互通。但是一旦针对某个特定的Pod设置了网络策略,那么只有满足策略声明的流量允许通过。网络策略的基本工作原理如下图所示:
1 | apiVersion: networking.k8s.io/v1 |
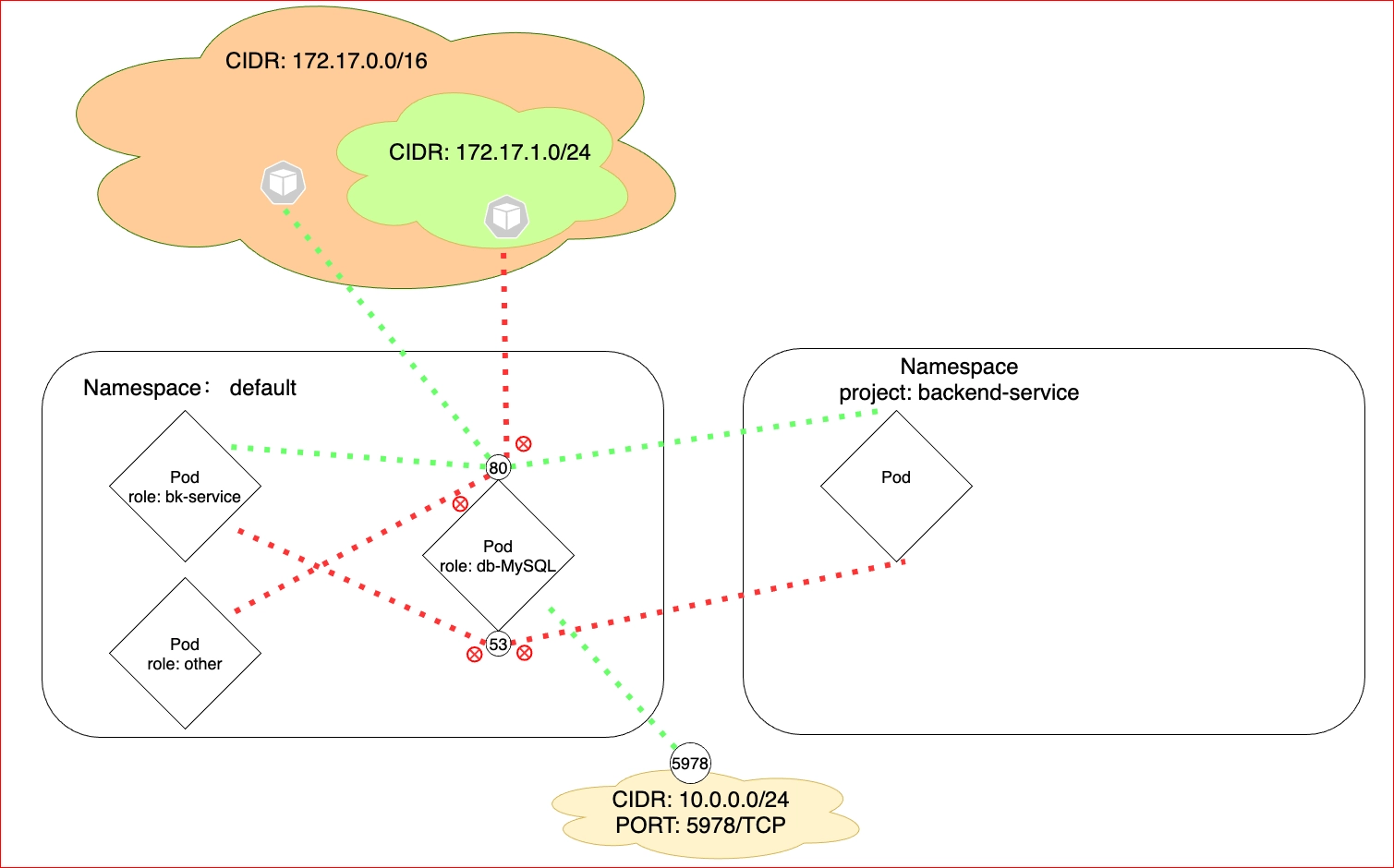
图 - 13 Network Policy 配置实例
关于namespaceSelector和podSelector,需要作一些说明:在入站和出站配置中,namespaceSelector和podSelector可以单独设置,也可以组合配置。如果仅配置podSelector,则表示podSelector指定的Pod与spec部分中指定的Pod处在同一个命名空间;如果两者都有配置,则指的是namespaceSelector指定的命名空间下的符合podSelector规则的Pod会被选中参与策略控制行为。
Kubernetes还提供了命名空间级别的网络策略配置,以方便管理员对整个Namespace进行统一的网络策略设置。默认提供了如下5种类型的控制策略:
默认拒绝所有入站流量
1
2
3
4
5
6
7
8
9---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress创建选择所有Pod但不允许任何进入这些Pod的入站流量的名为default-deny-ingress策略。这样即使Pod没有选择其他策略,也会被隔离。 此策略不会更改默认的出口隔离行为。
默认允许所有入站流量
1
2
3
4
5
6
7
8
9
10
11---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-ingress
spec:
podSelector: {}
ingress:
- {}
policyTypes:
- Ingress创建允许所有流量进入某个名字空间中的所有 Pod的名为allow-all-ingress的策略。
默认拒绝所有出站流量
1
2
3
4
5
6
7
8
9---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-egress
spec:
podSelector: {}
policyTypes:
- Egress创建选择所有Pod但不允许来自这些Pod的任何出站流量的名为default-deny-egress的策略。此策略可以确保即使没有被其他任何策略选择的 Pod 也不会被允许流出流量。 此策略不会更改默认的入站流量隔离行为。
默认允许所有出站流量
1
2
3
4
5
6
7
8
9
10
11---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress
spec:
podSelector: {}
egress:
- {}
policyTypes:
- Egress创建允许所有流量流出某个名字空间中的所有 Pod的名为allow-all-egress的策略。
默认拒绝所有流量(入站和出站)
1
2
3
4
5
6
7
8
9
10---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress创建选择所有Pod但不允许来自这些Pod的任何入站和出站流量的名为default-deny-all的策略。
涉及基础知识点
源地址伪装和端口转发
源地址伪装:NAT设备将经过源主机发出的包转发到指定的接收方,同时将通过的数据包的源地址更改为NAT设备的接口地址。当返回的数据包到达时,会将目的地址修改为源主机的地址并将该数据包转发给源主机。地址伪装可以实现局域网多个地址共享一个公网地址与外界通信。
端口转发:也可以称之为目的地址转换或端口映射。通过端口转发,将指定IP地址及端口的流量转发到相同计算机上的不同端口,或不同计算机上的端口上。一般而言,公司/机构内网的服务器会采用私网地址构建网络,然后通过端口转发将外部用户的请求转发到内网的某个特定位置上,以便让外部能够访问到内网的服务器。
参考文献
- 1.Lee, Calcote. "THE CONTAINER NETWORKING LANDSCAPE: CNI FROM COREOS AND CNM FROM DOCKER." The New Stack. N.p., 16 Sept. 2016. Web. 13 Apr. 2021.
- 2.cni-dev. "Github - Containernetworking/Plugins: Some Reference and Example Networking Plugins, Maintained by the CNI Team." Github. N.p., n.d. Web. 11 Apr. 2021.
- 3.Mahalingam, Mallik, et al. "Virtual eXtensible Local Area Network (VXLAN): A Framework for Overlaying Virtualized Layer 2 Networks over Layer 3 Networks." ITEF RFC 7348, August 2014.
- 4.Nathani, Ronak. "How a Kubernetes Pod Gets an IP Address." Ronak Nathani. N.p., 21 Aug. 2020. Web. 14 Apr. 2021.
- 5.龚正, et al. Kubernetes权威指南:从Docker到Kubernetes实践全接触. 4th ed. 北京: 电子工业出版社, 2019. Print.
- 6.高庆. 'Calico on Kubernetes 从入门到精通." Kubernetes中文社区. N.p., 22 Dec. 2018. Web. 10 Apr. 2021.
- 7.CE资料. “【华为悦读汇】技术发烧友:认识VXLAN.” 华为企业互动社区. N.p., 23 Nov. 2015. Web. 15 Apr. 2021.
- 8.HUAWEI contributors. “Overlay Networking - Huawei DCN Design Guide.” HUAWEI Enterprise. N.p., 14 June 2018. Web. 15 Apr. 2021.
- 9.Luksa, Marko. Kubernetes in Action中文版. Trans. 七牛容器云团队. 1st ed. 北京: 电子工业出版社, 2019. Print.
- 10.杜军. Kubernetes网络权威指南:基础、原理与实践. 1st ed. 北京: 电子工业出版社, 2019. Print.
- 11.闫健勇, et al. Kubernetes权威指南:企业级容器云实战. 1st ed. 北京: 电子工业出版社, 2018. Print.
- 12.马永亮. Kubernetes进阶实战. 2nd ed. 北京: 机械工业出版社, 2019. Print.
- 13.溪恒. "从零开始入门 K8s:理解 CNI 和 CNI 插件." InfoQ. N.p., 26 Mar. 2020. Web. 15 Apr. 2021.
- 14.Kubernetes contributors. "Network Plugins." Kubernetes. N.p., 5 May 2018. Web. 15 Apr. 2021.
- 15.Project Calico contributors. "Component Architecture." Project Calico. N.p., n.d. Web. 15 Apr. 2021.
- 16.Balkan, Ahmet Alp . "Kubernetes Network Policy Recipes." GitHub. N.p., 30 July 2017. Web. 10 Apr. 2021.
- 17.Kubernetes contributors. "High Performance Network Policies in Kubernetes Clusters." Kubernetes. N.p., 26 Sept. 2016. Web. 10 Apr. 2021.
- 18.Kubernetes contributors. "Network Policies." Kubernetes. N.p., 15 July 2018. Web. 13 Apr. 2021.
- 19.Kubernetes contributors. "Why Kubernetes Doesn’t Use Libnetwork." Kubernetes Blog. N.p., 14 Jan. 2016. Web. 14 Apr. 2021.
- 20.马旻. "虚拟叠加网络--数据中心私有云建设的基石." N.p., Apr. 2014. Web. 14 Apr. 2021.
- 21.马旻. "VxLAN技术 探讨和方案选择." N.p., Mar. 2014. Web. 14 Apr. 2021.
- 22.Hedlund, Brad. "Mind Blowing L2-L4 Network Virtualization by Midokura MidoNet." Brad Hedlund. N.p., 6 Oct. 2012. Web. 14 Apr. 2021.
- 23.Hedlund, Brad. "Network Virtualization is like a big virtual chassis." Brad Hedlund. N.p., 12 Oct. 2011. Web. 14 Apr. 2021.
- 24.Wikipedia contributors. "Virtual Extensible LAN." Wikipedia, The Free Encyclopedia. Wikipedia, The Free Encyclopedia, 17 May. 2021. Web. 20 Jun. 2021.
- 25.Spreitzer, Mike, et al. "Container Network Interface (CNI) Specification." GitHub. N.p., 30 May 2015. Web. 14 Apr. 2021.
- 26.乾坤李. "CNI——容器网络是如何打通的." 李乾坤的博客. N.p., 11 Oct. 2018. Web. 14 Apr. 2021.
- 27.Helios. "深入浅出kubernetes中的CNI." GitHub. N.p., 3 Mar. 2020. Web. 14 Apr. 2021.