Kubernetes集群内Pod之间默认可以无障碍的进行通信,但是通常情况下Pod是不稳定的,无法确定Pod会在何时因为何种原因被重启。当Pod重启后,其会得到一个新的IP地址。而且,如无特别指明,Pod有可能会在不同的节点之间被调度。当提供相同服务的Pod有多个时,就需要一个统一的对外地址来接收服务请求,并将请求以负载均衡的方式分发到Pod上。Kubernetes Service就是在这种背景下被引入的,Service是一种为一组提供相同服务的Pod提供单一不变的、简单透明的接入访问点的资源对象。Service的IP地址和端口在其整个生命周期不会改变,客户端可以通过服务IP:服务Port的方式发起服务请求,也可以直接访问服务名,由Kubernetes集群提供的DNS解析服务将请求分发到Service背后的Pod上。出于篇幅考虑,相关的yaml配置不会在文章中出现,特殊情况除外,相关的yaml配置可以参考Kubernetes官方文档。
2. K8s network之二:Kubernetes的域名解析、服务发现和外部访问
4.K8s network之四:Kubernetes集群通信的实现原理
Pod和Service之间的通信过程
前面我们大概了解了Kubernetes集群中同一Pod内各个容器之间以及Pod之间相互通信的过程,Pod之间可以直接通过IP地址在无需NAT的前提下完成通信过程,至于如何得知对方IP,可以采用某种方式将IP固定下来,或者写入配置项等等手段。但是Pod的生存周期通常来说是短暂的,有可能会因为各种原因被重启,而Pod的设计原理又使得当Pod在重启前后会得到不一致的IP地址,而且,在Pod启动前会通过CNI插件完成Pod的IP地址分配和配置工作,所以调用方也不可能在Pod启动前提前知道Pod的IP地址信息。就调用方而言,它其实并不关心提供服务的Pod有多少个,分布在哪里,IP地址信息是什么等,它只关心自己能通过何种方式访问Pod提供的服务。Service就是在这种背景下产生的,它把一系列提供相同服务的Pod聚合在一起,形成一个抽象的网络服务。Service一方面会根据一定的规则汇总提供服务的Pod信息集合,另一方面又向调用方提供了一个简单且统一的方式供其访问Pod提供的服务。
前面提到,Service是一种抽象的逻辑资源,实际上并没有对应的物理实体存在。每个Service都有一个全局唯一的IP地址,称为Cluster IP。同样,这个IP地址也是一个逻辑地址,实际上并不存在,尝试通过Ping程序向Cluster IP发送ICMP报文也会一直失败。每个Service都关联了数量不定的endpoints集合,每个endpoint代表了提供Service所声明的服务的一个Pod实例。在实际的Kubernetes集群中,每个节点上都有一个kube-proxy进程,kube-proxy会监听发送到Service上的请求,并根据endpoints列表集合采用指定的负载均衡算法对请求执行了DNAT(Destination Network Address Translation,请求到达Service之前目的地址是Service的Cluster IP和端口,DNAT之后目的地址是Pod的IP和端口)操作之后将请求转发到某个选中的Pod上,由Pod完成对请求的处理和响应。由于请求在转发过程中参与了DNAT的过程,DNAT前后地址信息的变化会被保存在Linux的连接追踪表(connection tracking table,即conntrack)中,当监听到请求的响应报文时,会根据conntrack中的记录执行DNAT的逆操作,也就是响应报文的源地址会从Pod的IP和端口号恢复为Service的Cluster IP和端口,这样请求发起的客户端就会认为自己是和Service直接通信的,实际转发过程对客户端而言是透明的。
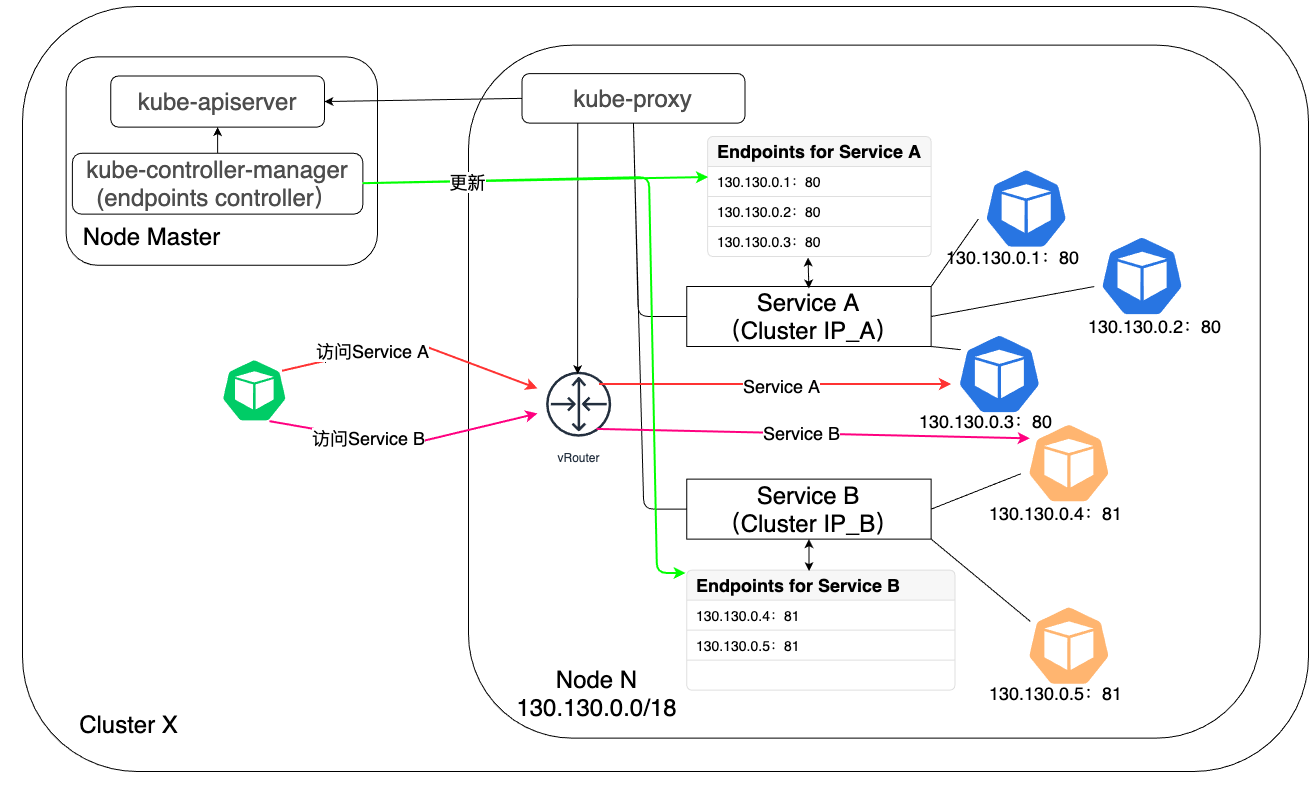
江湖上有一种说法:“Service会来监听Pod的变化,然后来更新Pod的IP地址“。这种说法严格来说并不是特别准确,实际上Service只是承担了服务声明的一个角色,对外发出公告:如果诸位想使用服务A,那么只需要找我就好了,我的Cluster IP是X.X.X.X。Service和实际提供Service声明的服务的Pod之间的映射关系是由endpoints对象来维护的。Endpoints控制器会从master节点上的kube-apiserver进程监控Pod的变更情况,之后会同步更新对应Service的endpoints列表。我们知道,Service和其对应的endpoints对象是同名的,所以控制器不仅仅关注于Pod的变更,还会关注Service的变更情况并同步更新endpoint:
- 如果发现对应的Service被删,那么被删Service对应的endpoints对象同样会被删除
- 如果Service被创建或者修改,那么基于该Service对应的Pod集合创建或更新Service对应的endpoints对象
当Service和Pod之间的映射关系建立后,kube-proxy就开始在集群中发挥其作用:kube-proxy会从kube-apiserver监控Service和endpoints资源的变化情况,并将Service和Endpoints的变化同步到节点的iptables表中,当一个到达节点的请求的目的地址命中了iptables表中某个Service对应的Cluster IP和端口时,内核会通过一系列iptables规则以指定的负载均衡算法从后端Pod中选择一个,通过DNAT技术修改请求的目的地址为命中Pod的IP地址和端口后将请求发送到选中的Pod上。kube-proxy提供了三种模型供用户进行选择来完成Service到后端Pod的转发工作—用户代理、iptables代理和ipvs代理。
用户代理模型(User space proxy mode)
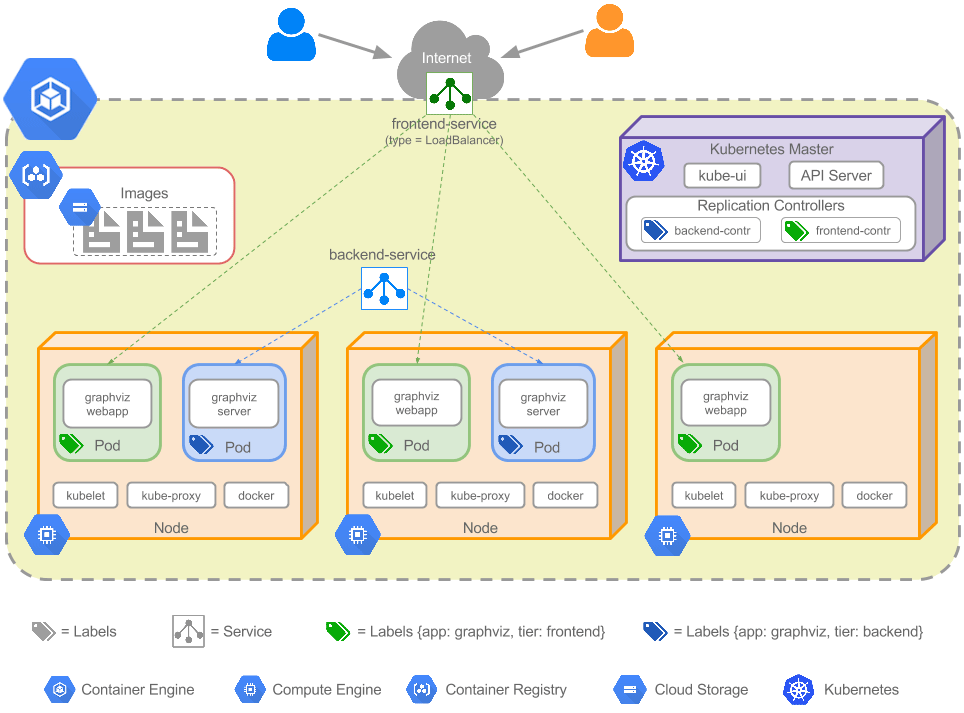
用户代理模型的历史非常短,在Kubernetes的v1.2版本中就被iptables模型取代成为新的默认选项。在用户代理模型中,kube-proxy真正意义上承担了代理的角色,由kube-proxy负责将请求流量转发给Service后端的Pod上。当kube-proxy在工作节点上启动后,就会监听kube-apiserver上Service和endpoints资源的变化情况,之后会针对每个service(每个协议、Service IP、Service端口)在节点上随机创建一个监听端口(这个端口实质上是一个Socket套接字),并在iptables中配置规则,这些规则会将目的地址是Service的IP:端口的请求转发给运行在用户空间的kube-proxy进程,kube-proxy接着会决定将请求转发给哪个Pod。当响应到达时,依旧是先通过kube-proxy,然后再转发给请求方。

图 - 3 Kubernetes 用户代理模式下Service实现架构[3]
由于一次请求需要在用户空间和内核空间来回转移,造成用户空间模型的整体效率并不高。于是Kubernetes在v1.2版本中用性能更好的iptables来实现Service的功能。
iptables代理模型
iptables从Kubernetes v1.2版本开始称为kube-proxy的默认模式,直到在v1.12版本中被IPVS取代而成为新的kube-proxy默认工作模式。在该模式中,kube-proxy修改了iptables中的filter和nat表,同时又对iptables的链进行了扩充,自定义了KUBE-SERVICES,KUBE-SVC-<HASH>,KUBE-SEP-<HASH>,KUBE-NODEPORTS,KUBE-FW-<HASH>,KUBE-XLB-<HASH>,KUBE-POSTROUTING,KUBE-MARK-MASQ和KUBE-MARK-DROP九个链条,通过在KUBE-SERVICES链中加入每个Service的ClusterIP和端口的匹配规则来完成流量的匹配和重定向工作。Kubernetes自定义的链条与iptables原生链条的调用关系如图4所示:
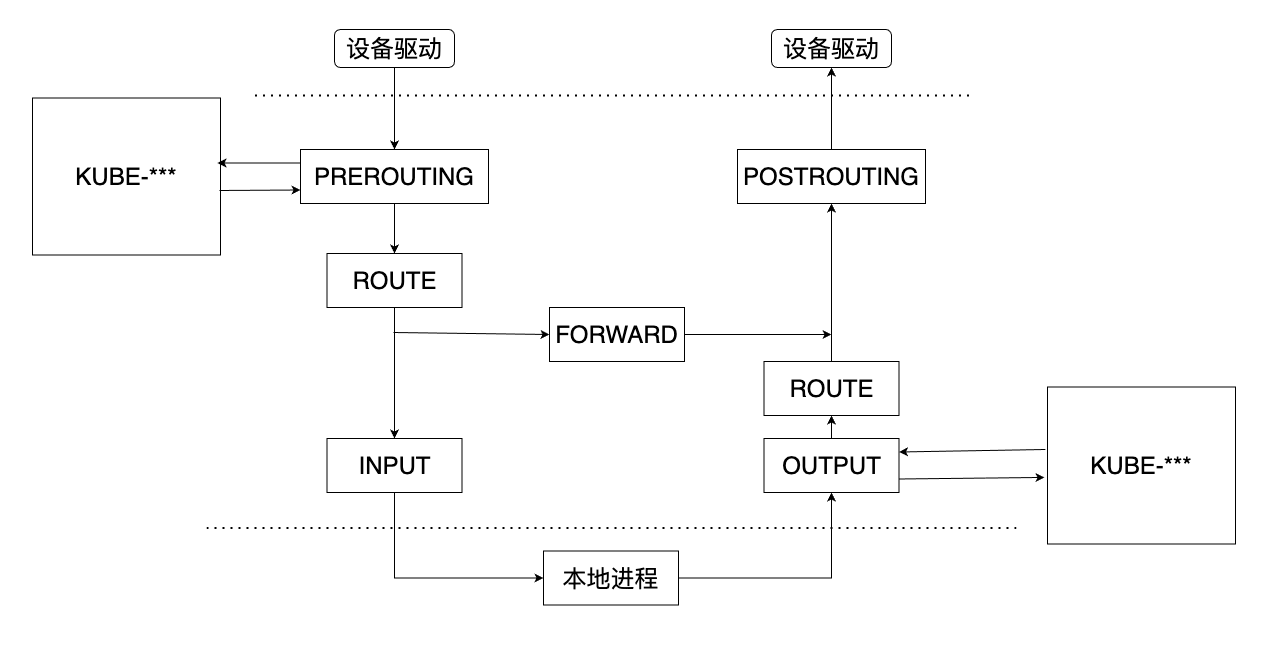
与用户空间代理模型不同的是,iptables代理模型中kube-proxy仅负责监听Service、endpoints等资源的变化,并将这种变化同步到iptables中的规则表中,不再参与请求的转发和负载均衡工作。这些工作均由iptables来完成,所以请求会一直在内核空间中传递,不必再被转入用户空间的kube-proxy进程中。

图 - 5 Kubernetes iptables代理模型下Service实现架构[4]
我们知道,Kubernetes的Service最普遍的应用是以Cluster IP的形式实现在Kubernetes集群内的服务调用,除此之外,Service还可以以NodePort、LoadBalancer、external IP形式将服务暴露到集群外部供外部实体访问和调用服务。这几种方式在iptables中的实现过程会稍有不同,接下来会对其进行简要分析。Kubernetes会按照Cluster IP、externalIP、 LoadBalancer和NodePort的顺序对外暴露服务,所以我们也会按照这个顺序进行学习。
Cluster IP
当集群内Pod访问Service的Cluster IP时,报文会通过iptables的OUTPUT链进入Kubernetes的自定义链。假设当前集群中有一个Service A,同时有三个后端Pod用来提供服务Service A,kube-proxy采用随机负载均衡算法来选择Pod,针对Cluster IP的处理流程如下图所示:
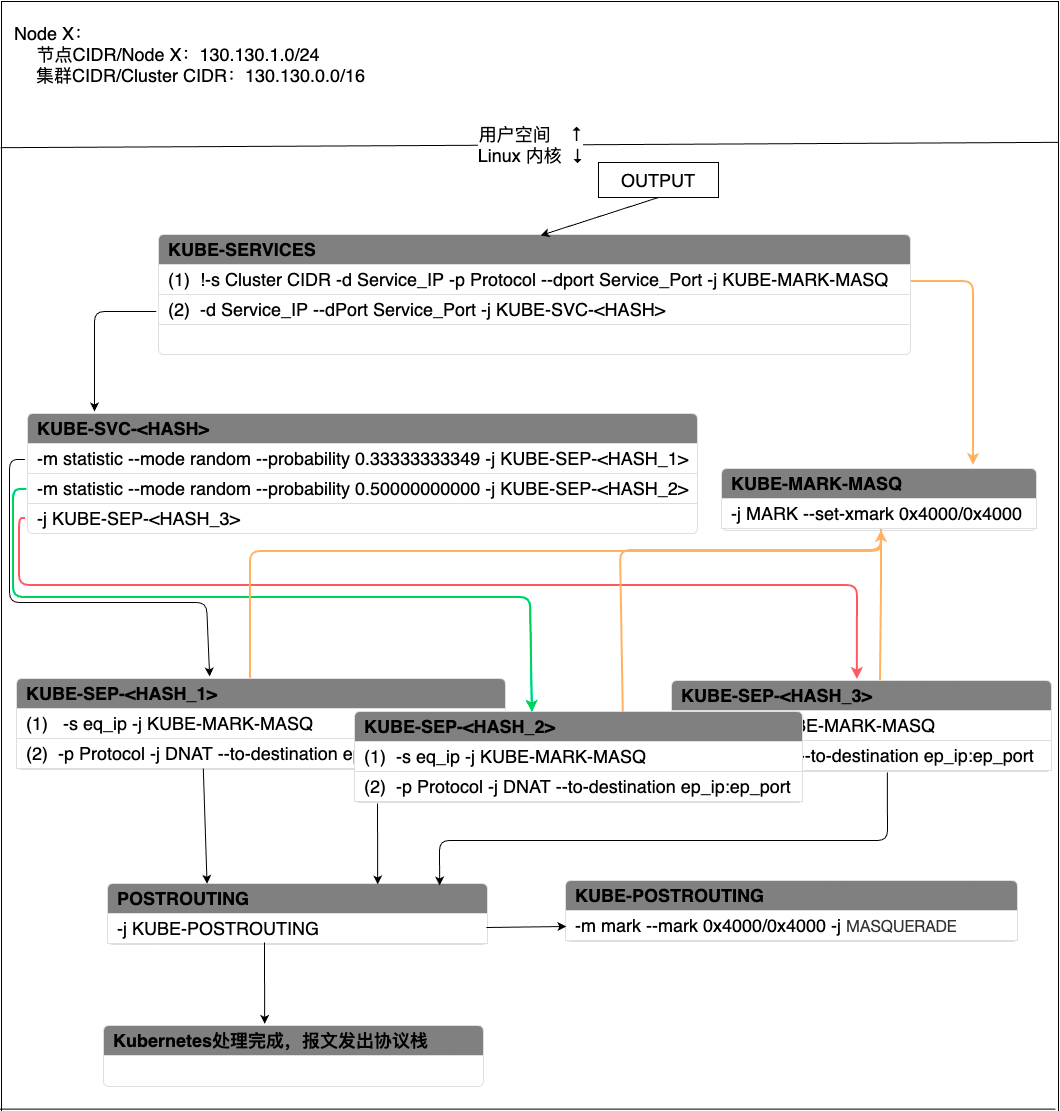
图 - 6 Service在Cluster IP模式下报文处理过程
【Note】:某些链条的名字中含有<HASH>字样,这是运用SHA256算法对“namespace + name + portname+协议名”生成哈希值,然后通过base32对该哈希值编码,最后取编码值的前16位的值[2]。
报文会首先进入KUBE-SERVICES链条。KUBE-SERVICE针对每个Service会产生两条匹配规则,规则(1)表示如果报文的源地址不是集群内IP地址,同时,报文匹配了请求Service的协议和端口,那么就跳转到(-j)KUBE-MARK-MASQ链条,在报文中加入一个特殊的防火墙标识,打上这个标识的报文会在POSTROUTING阶段执行SNAT(Source Network Address Translation)。如果确实命中了规则(1),那么在打完标记后会继续检查规则(2),规则(2)会将报文带入下一个链条—KUBE-SVC-<HASH>。
KUBE-SVC-<HASH>包含了当前提供Service的后端Pod、负载均衡模式等消息。kube-proxy默认采用的随机负载算法,因此在这种算法下会为每个Pod分配一个命中概率。在图-6中,三个Pod被命中的概率都是三分之一。当选中一个Pod后,就会跳转到和Pod相对应的KUBE-SEP-<HASH>上。
每个KUBE-SEP-<HASH>和一个Pod相对应,且每个KUBE-SEP-<HASH>均有两条规则。规则(2)表示对请求做DNAT,将请求的目的地址由原来的ClusterIP:Port转换成Pod_IP:Port。这样就将Pod访问Service变成了Pod和Pod之间的访问。规则(1)的目的是为了应对Hairpinning 发夹问题而设计的:Service A的后端Pod中有可能会有某个Pod访问Service A,然后经过iptables时又恰好选中了自己作为服务的提供方。换句话说,Pod要为自己发出去的服务请求做出响应。在Kubernetes中这样会造成访问失败,如果当出现这种场景时就跳转到KUBE-MARK-MASQ链条执行SNAT,将请求的源地址由Pod自身变成节点的node IP,这样就又变成了正常的服务请求和响应模式。如图7所示,左边是没有做SNAT的场景,Pod A收到了一个自己发出的服务请求,请求的源和目的地址都是自己,当发送响应给自己时会导致失败。右边是借助SNAT解决Hairpinning问题的场景,Pod A访问自己所属服务的请求到达Linux内核时会通过SNAT将源地址由Pod A的IP变成节点的Node IP。当Pod A发送响应报文时,报文先发送给Node IP,然后在Linux内核中再次进行NAT,将源IP由Pod A的IP改成Service的IP,目的IP由Node节点的IP改为Pod A的IP,这样就可以正常工作了。
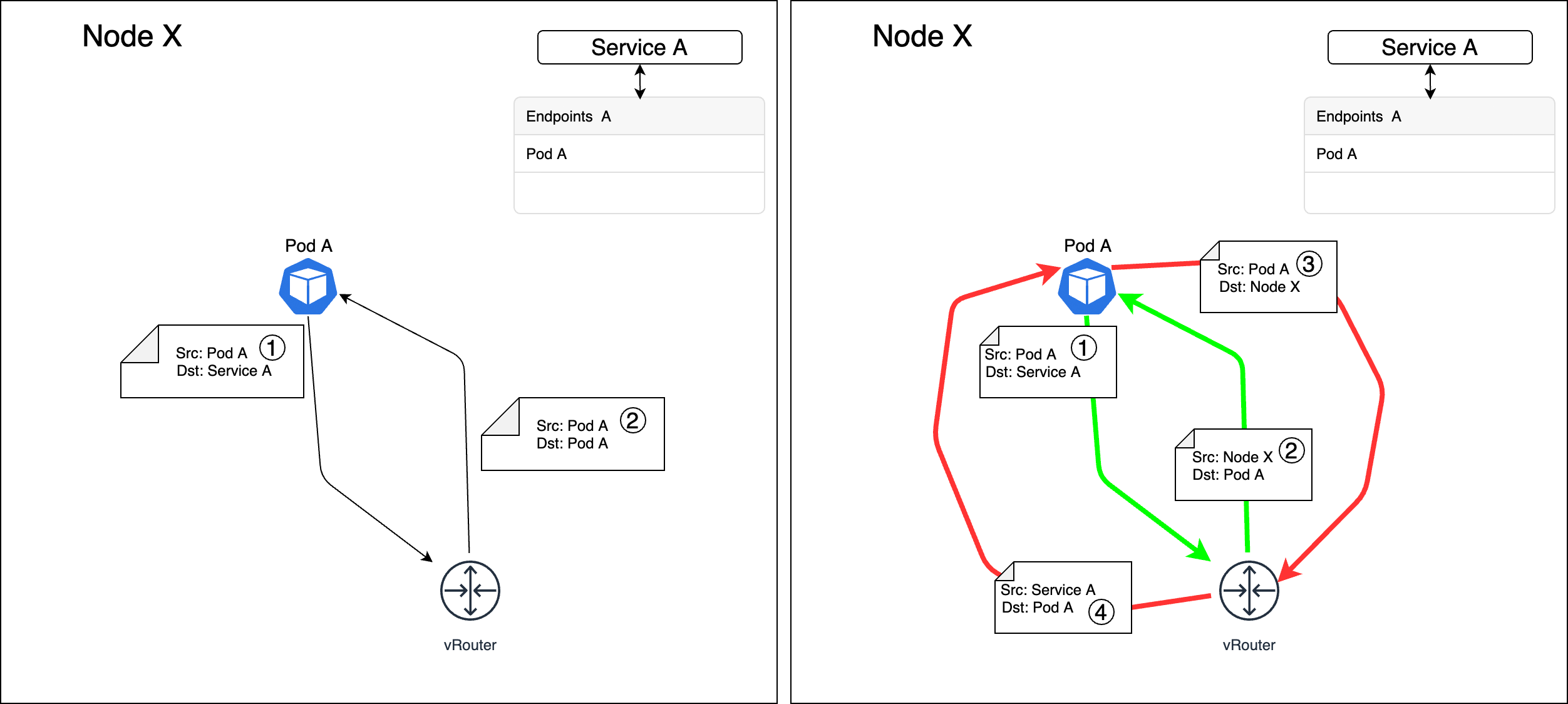
图 - 7 Hairpinning问题及其解决方法执行完DNAT后,会跳转到POSTROUTING链条。POSTROUTING会无条件跳转到KUBE-POSTROUTING链条,这个链条会检查报文是否有跳转到KUBE-MARK-MASQ链条被打上防火墙标识,如果有的话就会执行SNAT,将报文的源地址变为节点的node IP。
最后由POSTROUTING将报文发出协议栈。
external IP
当Service可以通过external IP暴露在集群外部供外部实体调用时,报文会通过PREROUTING进入Kubernetes的自定义链条。假设当前集群中有一个Service A,同时有三个后端Pod用来提供服务Service A,kube-proxy采用随机负载均衡算法来选择Pod,针对external IP的处理流程如下图所示:
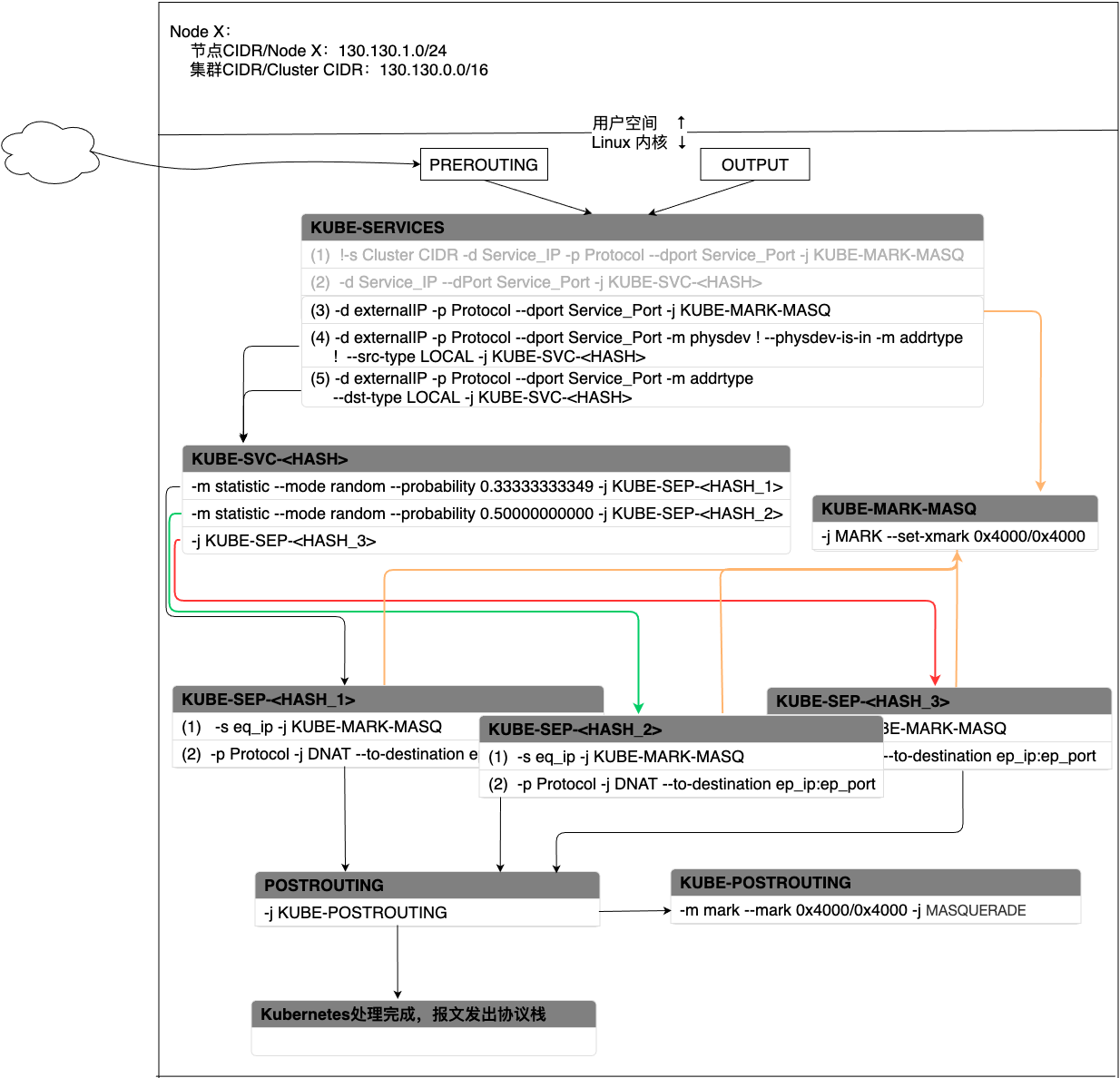
图 - 8 Service在external IP模式下报文处理过程
报文依旧会首先进入KUBE-SERVICE,每个external IP记录会在KUBE-SERVICE中产生三条记录。报文首先会命中规则(3),也就是说如果报文的目的地址是external IP,协议和端口也都命中了,那么就跳转到KUBE-MARK-MASQ打标签,最后会做SNAT。紧接着会检查匹配规则(4),如果当前报文的目的地址是Service的external IP,端口和协议都匹配了,且报文不是bridge接口进来的,且源地址不在本机上,那么就跳转到KUBE-SVC-<HASH>上。最后检查匹配规则规则(5),如果当前报文的目的地址是Service的external IP,端口和协议也匹配了,且目的地址是在本机上,那么就跳转到KUBE-SVC-<HASH>上。
规则(4)需要报文不是从bridge接口进来的,说明报文肯定不是来自本机上的Pod,源地址不在本机地址范围,说明报文来自集群外。因为Kubernetes集群内的每个节点上都会有由集群中所有Service的信息构建的iptables规则,所以如果是Pod发出的流量的源地址一定是LOCAL类型的。(5)中,因为external IP关联了本机网卡上的一个接口,因此也算作本机的LOCAL地址,所以匹配了external IP也就匹配了—dst-type LOCAL。这两条规则相互补充,就限制了流量只能来自外部,且只能从external IP接口流入Kubernetes集群。所以这两条规则都会跳转到KUBE-SVC-<HASH>规则中。
后面的过程就和Cluster IP模式下的工作流程类似了,故这里不再予以赘述。
LoadBalancer
Service可以接入外部的负载均衡器来实现节点级别的负载均衡功能。在Service的配置中有一个externalTrafficPolicy参数,这个参数有两个值可供选择:Local和Cluster。如果参数设置为Local,那么当流量被外部负载均衡器命中到某个节点上时,流量将只会在该命中节点上被处理,不会通过该节点转发到集群内的其他节点上。如果该节点上没有提供服务的Pod,那么当前请求会被丢弃。如果参数设置为Cluster,那么当流量被外部负载均衡器命中到某个节点上时,该请求可能只是路过该节点,最终会被转发到其他节点上处理。这个参数默认为Cluster。iptables规则处理这两个参数选项的处理过程会稍有不同。
针对LoadBalancer类型的Service,KUBE-SERVICE中会生成一条用于命中这种类型的规则,这条规则会将流量转发给规则KUBE-FW-<HASH>。KUBE-FW-<HASH>会根据externalTrafficPolicy将流量传递给KUBE-SVC-<HASH>或者KUBE-XLB-<HASH>或者KUBE-MARK-DROP。
当externalTrafficPolicy=cluster时,流量匹配过程如图9所示:
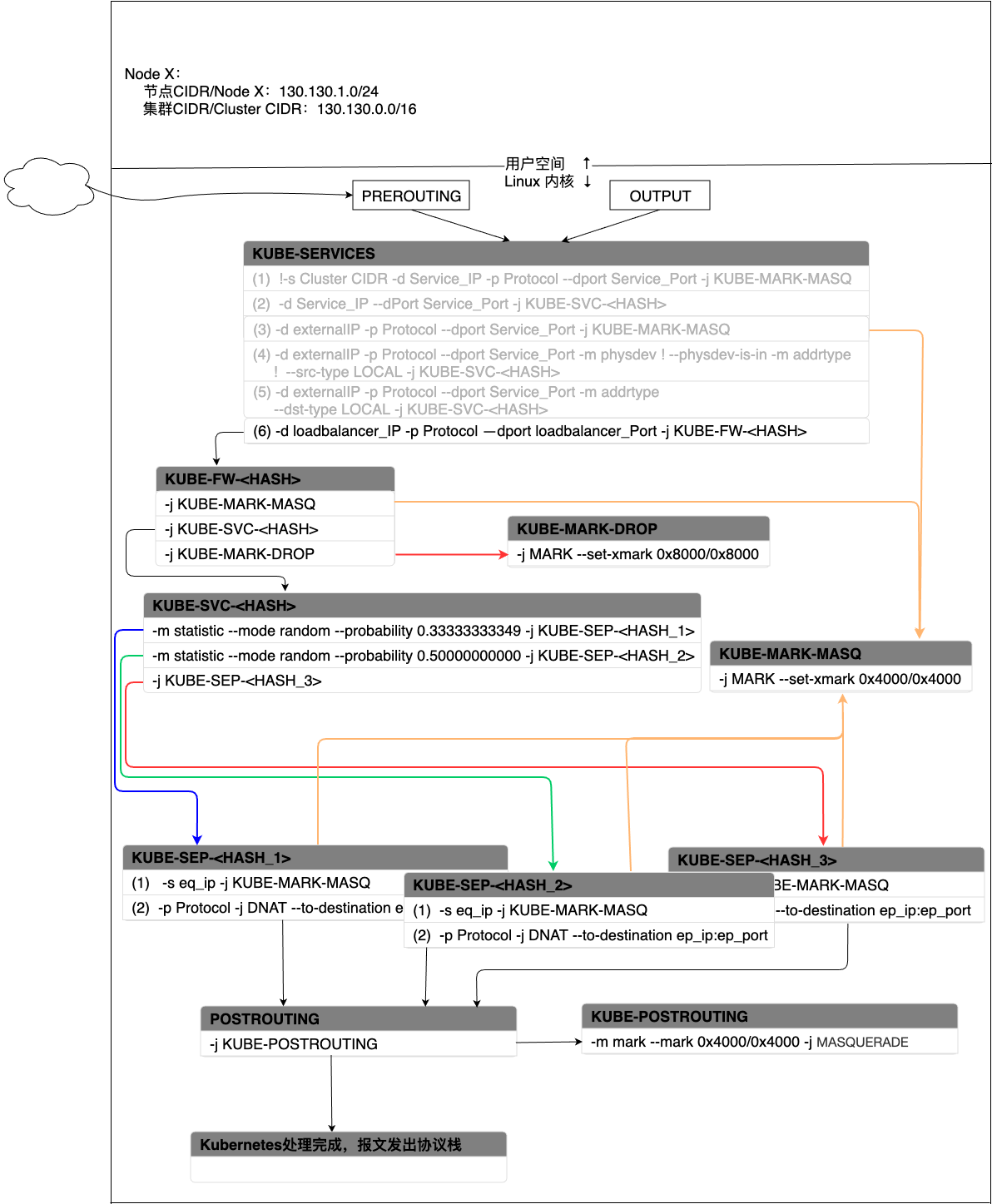
图 - 9 Service在LoadBalancer模式下(Cluster)报文处理过程
- 如果流量的目的地址为负载均衡的IP地址,协议、端口也都命中,那么就跳转到KUBE-FW-<HASH>。
- 当流量进入KUBE-FW-<HASH>后,会首先跳到KUBE-MARK-MASQ打上特殊标记用来做SNAT。之后会跳转到KUBE-SVC-<HASH>按照Cluster IP类型的服务进行处理。如果当前无对应的KUBE-SVC-<HASH>,那么就跳转到KUBE-MARK-DROP废弃该报文。
- 当流量进入到KUBE-SVC-<HASH>后,按照Cluster IP的过程完成流量转发过程。
当externalTrafficPolicy=Local时,会通过KUBE-XLB-<HASH>将流量转发到Pod上。此时KUBE-XLB-<HASH>中只会有当前节点上部署的提供特定Service的Pod规则信息,如果当前节点没有满足条件的Pod,会生成KUBE-MARK-DROP规则将流量丢弃。流量匹配过程如图所示:
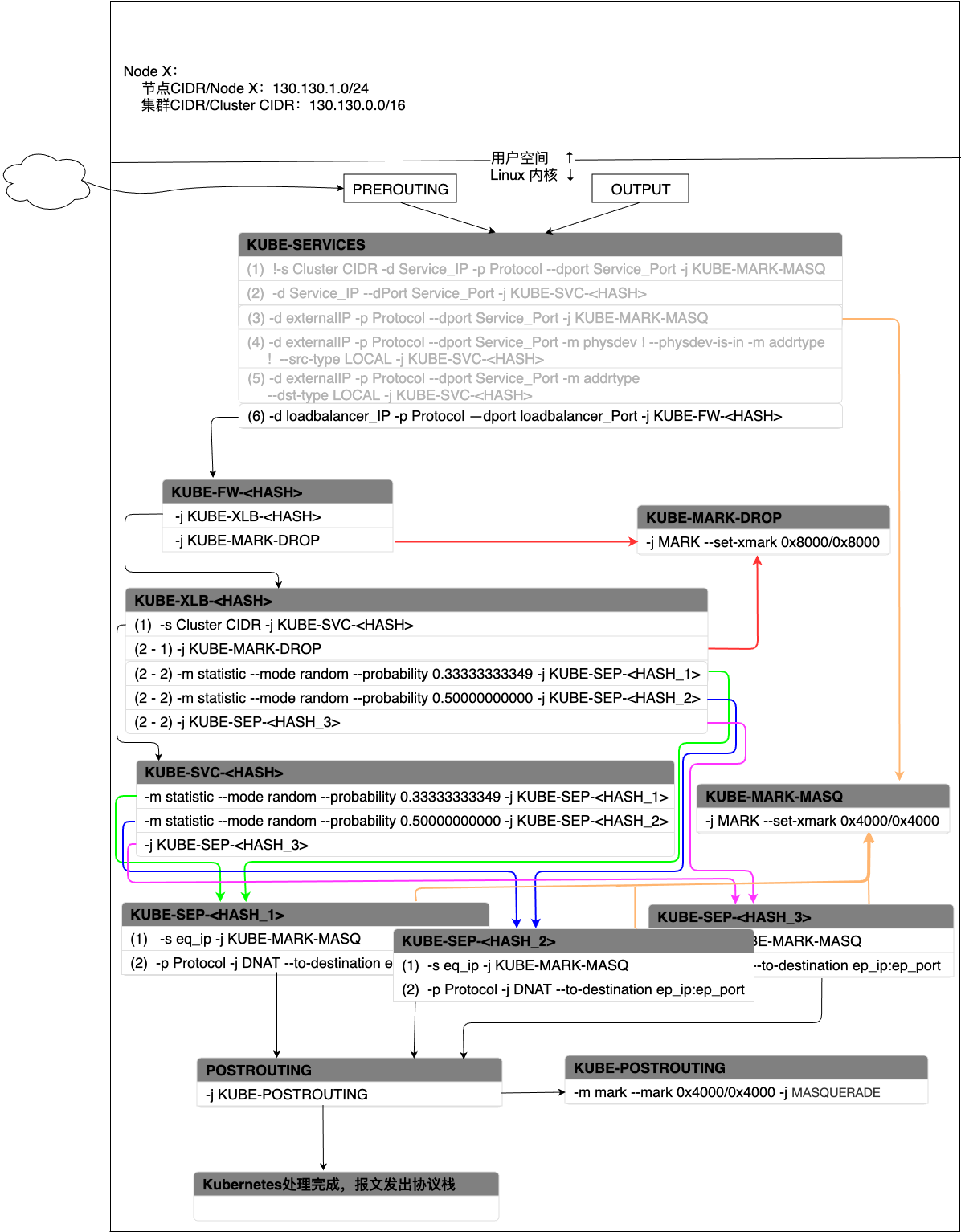
图 - 10 Service在LoadBalancer模式下(Local)报文处理过程
- 第一步同样是由KUBE-SERVICE中匹配LoadBalancer的规则将流量转入到KUBE-FW-<HASH>。这里的KUBE-FW-<HASH>和externalTrafficPolicy=Cluster下的KUBE-FW-<HASH>有一些不同之处:这里的KUBE-FW-<HASH>只有两条规则,第一条规则会将流量转到KUBE-XLB-<HASH>,当找不到KUBE-XLB-<HASH>时就将流量转入KUBE-MARK-DROP丢弃。
- 当流量被转入到KUBE-XLB-<HASH>后,首先尝试匹配规则(1)。如果流量的源地址是集群内地址,那么按照Cluster IP模式进行处理,会将流量直接转入到KUBE-SVC-<HASH>处理。如果流量当前所在节点没有部署任何和该负载均衡服务相关的Pod,那么就通过规则(2-1)丢弃该流量。否则,根据规则(2-2)选中一个Pod,将流量转发到Pod完成服务请求和响应。需要注意的是,规则(2-1)和(2-2)在同一个服务中是互斥的,二者不会同时存在。
NodePort
Service的NodePort是KUBE-SERVICE中最后尝试被匹配的规则。换句话说,匹配NodePort的规则被放在了KUBE-SERVICE规则表中的最后位置。同样,针对externalTrafficPolicy参数的不同设置,NodePort模式下iptables的处理过程也稍有差异。
当externalTrafficPolicy=Cluster时,流量匹配过程如图11所示:
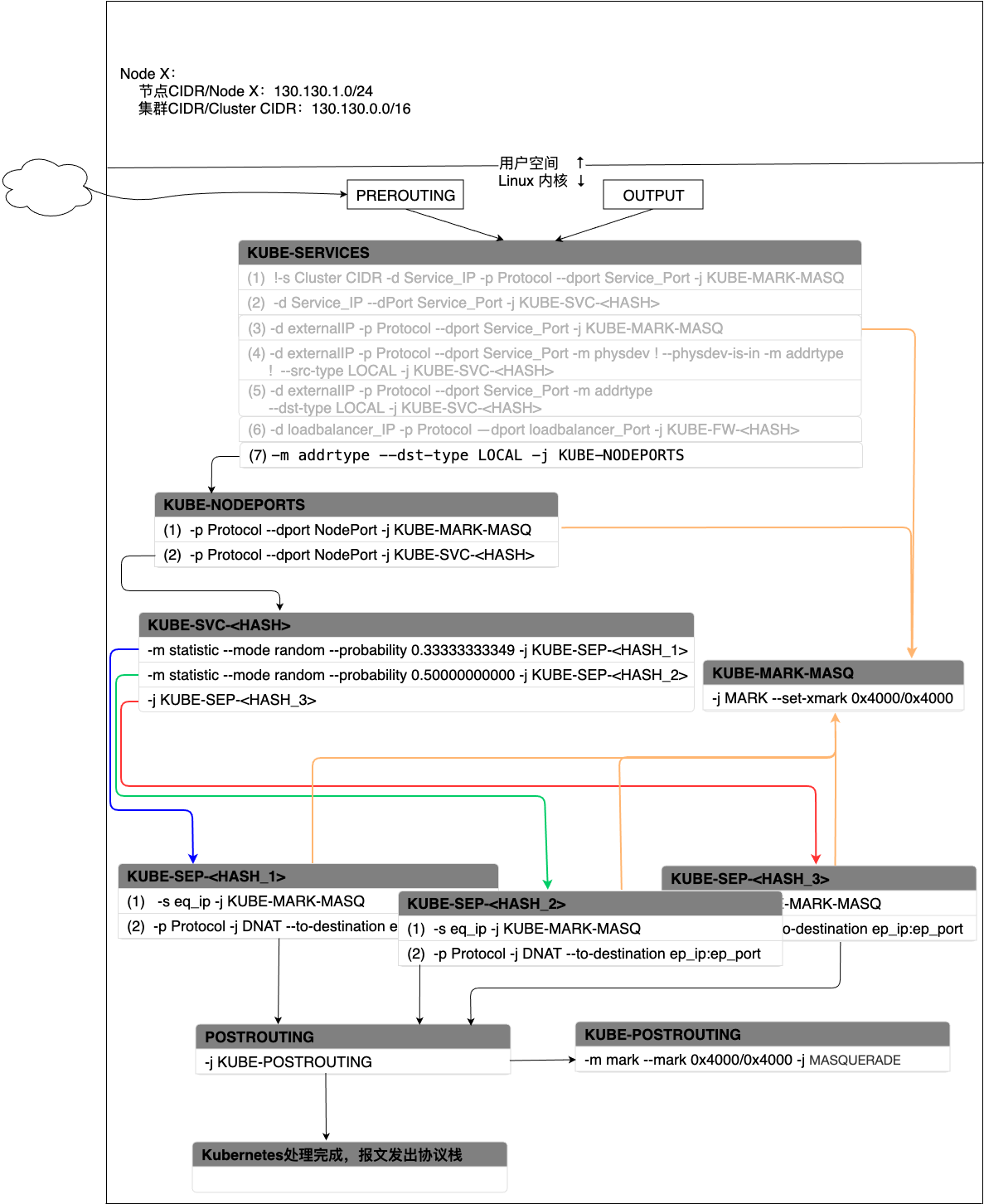
图 - 11 Service在NodePort模式下(Cluster)报文处理过程
- 如果流量是通过NodePort流入集群,且目的地址是当前节点上地址范围内的地址,那么就命中了KUBE-SERVICE的规则(7),流量被转入到KUBE-NODEPORTS。
- 当流量进入KUBE-NODEPORTS中后,首先跳转到KUBE-MARK-MASQ,为该报文打上执行SNAT的标记。之后会将流量转入到KUBE-SVC-<HASH>。
- 之后就按照Cluster IP模式进行流量转发、处理和响应。
当externalTrafficPolicy=Local时,,会通过KUBE-XLB-<HASH>将流量转发到Pod上。此时KUBE-XLB-<HASH>中只会有当前节点上部署的提供特定Service的Pod规则信息,如果当前节点没有满足条件的Pod,会生成KUBE-MARK-DROP规则将流量丢弃。流量匹配过程如图12所示:
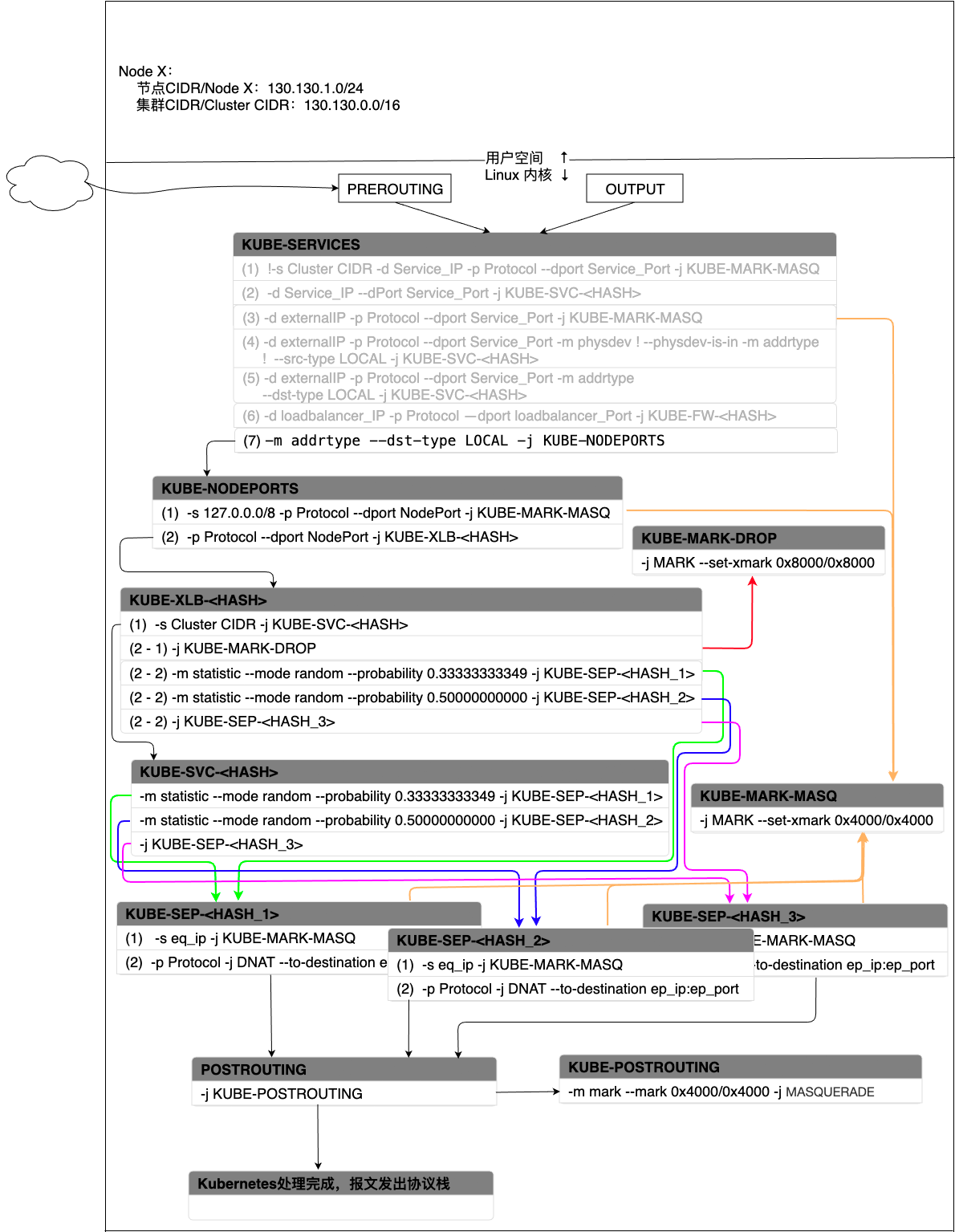
图 - 12 Service在NodePort模式下(Local)报文处理过程
流量同样由KUBE-SERVICE中规则(7)被转入到KUBE-NODEPORTS。
KUBE-NODEPORTS中规则(2)会将流量转入KUBE-XLB-<HASH>,最终会被转发到本节点上的某个Pod。规则(1)用来解决localhost martian source(martian packet)问题。
martian packet指的是那些因为源或目的IP地址归属于由IANA(Internet Assigned Numbers Authority)所规定的保留用作特殊用途的IP地址集合而无法被路由器转发处理,或者被发送到了和源/目的IP地址不属于同一个网段的报文。在Linux内核环境下,martian packet指的是那些在某个特定网络接口上被内核接收但实际上应该被另一个网络接口所接收的报文。martian packet意为来自火星的报文,也就是不属于“地球”的报文。martian packet产生的原因很多,常见的可能原因如下:
- 用于拒绝服务攻击(DoS)的IP地址欺骗
- 网络设备故障或者域名的错误配置
规则(1)对martian packet尝试做一次SNAT,使得martian packet可以再次可以被Linux内核路由到正确的目的地址上。
在iptables模型中,Service的服务发现和负载均衡全都在内核中的iptables完成,因此消除了流量在用户空间和内核空间来回复制切换所带来的的性能损耗,相较于用户代理模式会更加高效。但是iptables依然存在不足:
iptables规则错综复杂,对于问题排障而言会有较大成本
iptables随着规则的扩增会导致性能迅速下降。iptables的实现是一种链表实现,其时间复杂度是O(n),当Service和Service背后的Pod数量上涨时,iptables的处理耗时也会一同增加。这使得iptables成为集群大规模扩展的一个瓶颈,尽管在Kubernetes的v1.6版后集群已经可以支持5000节点的网络了。假设在一个5000节点的集群中有2000个Service,每个Service平均由10Pod提供对应的服务,那么每个节点上的iptables会有20000条规则,这就已经使得内核的压力非常大了[5]。
iptables的设计初衷是用来为主机防火墙服务的。尽管其可以实现负载均衡的功能,但这并不是iptables的长处。事实上,iptables能提供的负载均衡策略十分有限。
iptables模式中,如果选中了Service背后的某个特定Pod,而这个Pod恰好无法正常的处理请求。那么当前整个请求会处于失败状态,iptables不会尝试重新将该请求转发到其他正常Pod上。所以这是和用户空间代理模式相比之下的一个弱势。为了解决这个问题,需要用readiness探针对Pod进行监测,保证iptables中的规则中映射的都是正常工作的Pod。
鉴于上述的一些原因,Kubernetes在v1.12开始用更优秀的ipvs来取代iptables实现Kubernetes的Service。
IPVS(IP virtual server)代理模型
IPVS自v1.8版本开始被引入Kubernetes,在v1.11版本中升级为GA版本,从Kubernetes v1.12开始取代iptables成为kube-proxy的默认工作模式。
IPVS在Linux内核实现了传输层的负载均衡功能,因此也被称为L4交换机。运行在宿主机上的IPVS就像一个运行在集群入口处的负载均衡器,它负责将通过TCP/UDP协议发出的服务请求定向到真实的服务器上,同时将真实服务器上的服务以虚拟服务的形式暴露在单个IP地址上(即负载均衡器的IP地址)。IPVS和iptables虽然都是基于netfilter实现的,但是二者的目的和专长并不一致:iptables致力于为防火墙提供服务而IPVS则专注于高性能的负载均衡实现。IPVS由于使用了更高效的数据结构—Hash表,为更大规模集群扩展提供了更好的支持,此外,IPVS还实现了比iptables更丰富、复杂的的负载均衡算法。IPVS提供了三种负载均衡模式—DR、IPIP和NAT。
DR(Direct Routing)
DR模式是IPVS应用最广泛的模式,它直接工作在L2层,在MAC地址上执行负载均衡决策。当服务端发送响应流量给请求方时,流量会直接由服务端发送给请求方而不再经过IPVS。

当流量到达IPVS时,IPVS只修改流量的MAC地址,将源MAC由IPVS前一跳设备的MAC修改为IPVS负载均衡设备的MAC,将目的MAC由负载均衡设备的MAC修改为后端Server的MAC。到达后端的流量的IP地址在从请求方到服务端的过程中不会发生变化(在不考虑NAT的场景下)。当后端server发送响应流量时,流量将直接从后端server发送请求方,而不再经过IPVS负载均衡器。由于DR模式下IP地址不会变化,因此IPVS负载均衡设备和后端server都需要配置Service的IP(也就是VIP, Virtual IP),但是只有负载均衡设备会向整个网络通告VIP,后端server不会对外声明自己拥有VIP,这样就避免了IP地址冲突的发生,所有请求VIP对应的服务的流量也都只会通过负载均衡设备转发给后端server。
这种模式下,负载均衡设备只负责入流量的转发和管控,而不管出流量。因此负担更轻,能更高效的专注于负载均衡功能。但是这种模式不支持端口映射功能,此外,这个模式需要负载均衡设备和后端server都在一个网段中。因此,这种模式并不适合Kubernetes中Service的应用要求。
IPIP
IPIP(也称tunnel或者tun)和DR模式有点类似,负载均衡设备都只负责入站流量的转发和管控,出站流量由后端server直接发送给请求方。但是进入负载均衡设备的流量并不是通过修改MAC地址的方式被转发到后端server的,而是通过IP隧道的方式来实现的。换句话说,用一个源IP和目的IP分别为负载均衡设备的IP和后端server的IP报文将请求方发出的IP报文转发给后端server,由后端server完成请求处理和响应。

这种模式支持良好的可扩展性,而且负载均衡设备和后端server也无需一定要处在一个网段中。但是这种模式同样有缺点,和DR模式一样,IPIP模式同样不支持端口映射。而且,IP报文的MTU是有限制的,也就是说实际的请求方发出的IP报文的MTU不能太大,否则会导致负载均衡设备和后端server之间的报文大小超出MTU限制而产生问题。当然,你可以调节MTU的大小,但是这需要你拥有负载均衡设备和后端server所在网络的控制能力才能完成MUT的调节。所以,这个模式也无法胜任Kubernetes中Service的要求。
NAT
NAT模式是IPVS中最简单的模式。负载均衡设备会监听到达设备上的请求,当有流量到达负载均衡设备时,会将目的IP由负载均衡设备的IP改为后端server的IP,并将流量转发给后端server上。当请求响应由后端server发出后,响应报文同样需要被发送到负载均衡设备上,再由负载均衡设备执行源IP地址转换,将源IP地址由后端server的IP替换为负载均衡设备的IP,最后由负载均衡设备将流量转发给请求方。Kubernetes的Service正是使用NAT模式来实现其功能。

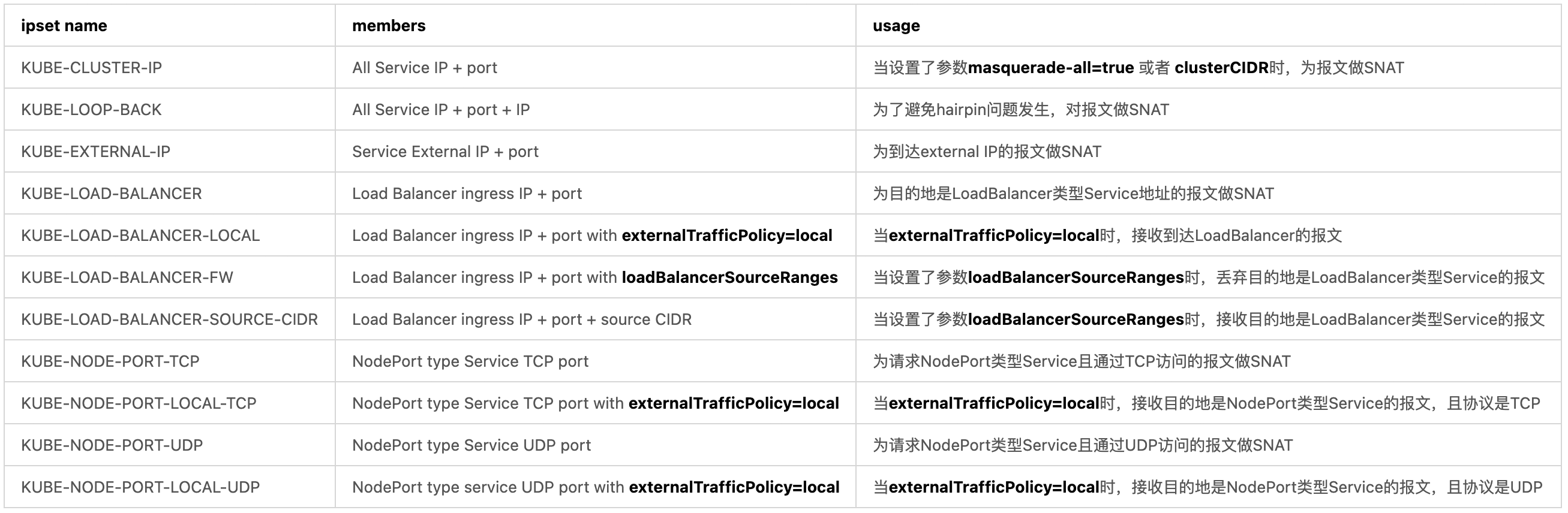
通过使用IPVS,kube-proxy对iptables的使用进行了进一步的优化:kube-proxy不再直接使用iptables生成规则链条,而是使用ipset来完成该功能。ipset引入了带索引的数据结构,当规则激增时,ipset可以以O(1)时间复杂度很高效地完成查找和匹配。换言之,可以将ipset简单理解为一个IP地址的集合,集合的内容可以是IP地址、IP网段、端口等,iptables可以对ipset进行操作,这样做可以大大减少iptables规则的数量以提高负载均衡的性能。IPVS维护的ipset集合如表1所示:

以Cluster IP类型的Service为例,我们会简单了解下IPVS是如何完成报文的负载均衡和转发工作的。当Cluster IP类型的Service被创建后,IPVS会做如下的三件事:
- 确保节点上会存在一个dummy的网络接口,默认为kube-ipvs0
- 将Service的Cluster IP绑定到kube-ipvs0接口上
- 为每个Cluster IP地址分别创建一个IPVS虚拟服务器
IPVS模式之所以要创建一个dummy的kube-ipvs0网络接口,是因为IPVS的hook是挂在INPUT链条上来处理DNAT的,因此需要通过PREROUTING而不是OUTPUT将流量导入到INPUT链条上,这样才能被IPVS接收并进行相应处理。假设当前集群中有服务nginx-service,且其Cluster IP和后端Pod地址信息如下所示:
1 | # kubectl describe svc nginx-service |
当上述三件事都完成后,就会看到kube-ipvs0接口的信息如下所示:
1 | # ip addr |
第3 ~ 6行表明有一个kube-ipvs0网络接口,这个接口的地址是10.102.128.4,也就是服务nginx-service的Cluster IP。第12 ~ 14行表明发送到10.102.128.4:3080的报文会以轮询方式(rr)被转发到nginx-service的两个地址为10.244.0.235:8080和10.244.1.237:8080的Pod上。
如果有多个服务,那么kube-ipvs0会响应的展示已有服务的所有Cluster IP信息。同样,端口转发部分也会显示Cluster IP和后端Pod之间的端口映射关系:
1 | $ ip addr show kube-ipvs0 |
当所有的组件都就绪后,就可以接收报文了。报文到达集群进入节点后,会经过如下的流程:
由于报文通过kube-ipvs0接口进入内核,所以报文会通过PREROUTING链条。PREROUTING中的规则格式如下所示:
1
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
紧接着,报文会进入到KUBE-SERVICE,在KUBE-SERVICE中会尝试匹配KUBE-CLUSTER-IP。KUBE-SERVICE中的规则格式如下所示:
1
2
3-A KUBE-SERVICES ! -s Cluster_CIDR -m comment --comment "Kubernetes service cluster ip + port for masquerade purpose" -m set --match-set KUBE-CLUSTER-IP dst,dst -j KUBE-MARK-MASQ
-A KUBE-SERVICES -m set --match-set KUBE-CLUSTER-IP dst,dst -j ACCEPT如果流量的源地址不在集群内,且匹配了KUBE-CLUSTER-IP,那么就跳到KUBE-MARK-MASQ打上标签做SNAT。紧接着第二条规则会尝试匹配-m set —match-set KUBE-CLUSTER-IP dst,dst规则:尝试匹配ipset集合KUBE-CLUSTER-IP,第一个dst表示请求的目的地址是否能匹配上Cluster IP,第二个dst表示请求的目的Port作为是否能匹配上Kubernetes中Service的端口。如果匹配成功,那么流量会继续向后传递并处理。
KUBE-CLUSTER-IP是个ipset,内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13# ipset list | grep -A 20 KUBE-CLUSTER-IP
Name: KUBE-CLUSTER-IP
Type: hash:ip,port
Revision: 5
Header: family inet hashsize 1024 maxelem 65536
Size in memory: 352
References: 2
Members:
Service_1_Cluster_IP,Service_1_Protocol:Service_1_Port
Service_2_Cluster_IP,Service_2_Protocol:Service_2_Port
Service_3_Cluster_IP,Service_3_Protocol:Service_3_Port
Service_N_Cluster_IP,Service_N_Protocol:Service_N_Port
Service_X_Cluster_IP,Service_X_Protocol:Service_X_Port集合中最重要的部分就是Members了,这里列出了当前集群中Service的Cluster IP、访问协议和端口信息。
当流量进入INPUT后,流量的DNAT处理在INPUT链条中完成。执行DNAT所依赖的IPVS规则如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.102.128.4:3080 rr
-> 10.244.0.235:8080 Masq 1 0 0
-> 10.244.1.237:8080 Masq 1 0 0
TCP Cluster_IP_2:port rr
-> Pod_21_IP:Pod_21_Port Masq 1 0 0
-> Pod_22_IP:Pod_22_Port Masq 1 0 0
TCP Cluster_IP_N:Port rr
-> Pod_N1_IP:Pod_N1_Port Masq 1 0 0
-> Pod_N2_IP:Pod_N1_Port Masq 1 0 0
当DNAT完成后,流量会流入POSTROUTING。
当流量进入POSTROUTING后,和iptables模式类似,流量无条件被传入到KUBE-POSTROUTING中。在KUBE-POSTROUTING中会根据流量是否带有特殊的0x4000/0x4000标记来决定是否需要对流量做SNAT。
1
-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING
1
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
最后将报文发出协议栈,完成后续的流量转发过程。整个的过程如图17所示:
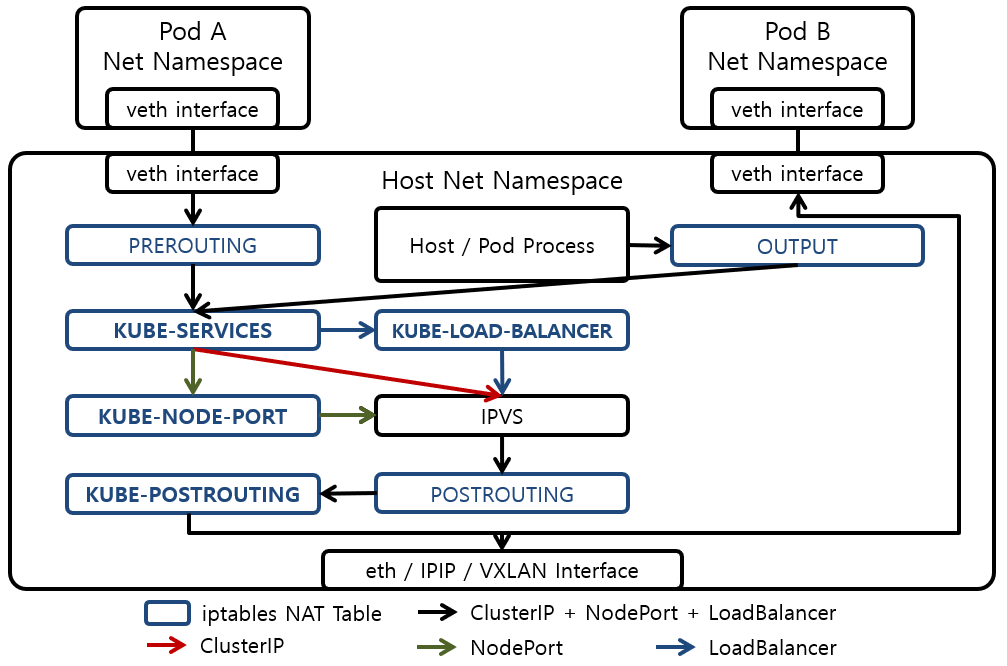
图 - 17 Kubernetes IPVS代理模型报文处理过程[8]
IPVS凭借更优秀的数据结构和整体设计,获得了比iptables更好的性能,使得集群可以更好的进行大规模扩展。在Calico的文章《Comparing kube-proxy modes: iptables or IPVS?》中,作者从服务响应耗时和CPU消耗两个方面对iptables和IPVS两个模型进行了比较。从服务响应耗时角度看,当Service的数量不多时,两个模型的响应耗时差距并不大,这个差异只有当Service数量规模以数千计或万计时,IPVS的性能会远优于iptables。如果将keepalive纳入考虑范围,那么由keepalive支持的服务请求和响应由于节省了每次请求需要执行的TCP连接过程,所以性能也会优于没有keepalive支持的场景。由于测试中服务提供的是静态内容,而实际上服务的响应数据都是动态生成的,响应时间会随着数据规模、算法复杂度等因素有可能会比本测试中耗时更高,这样kube-proxy发挥作用的耗时在整体耗时中的占比会相应的下降。
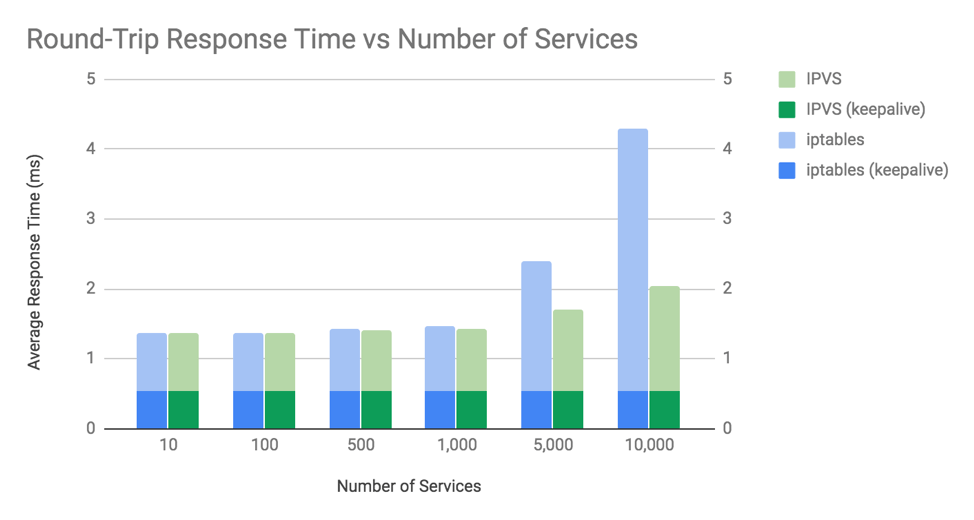
另一方面,作者在禁用keepalive的前提下测试了IPVS和iptables在不同规模Service场景下对CPU的需求情况。和响应耗时类似,只有当Service的规模以万计时,IPVS的性能优势才会更好的展现出来。而且,iptables使用CPU的增速远高于IPVS。这里有两个地方需要注意一下,首先,kube-proxy默认会以30秒的间隔刷新内核规则,所以你会看到IPVS的CPU占用也会有所增长即使IPVS的时间复杂度为O(1)。如果内核的版本比较老旧的话,对iptables的刷新速度会更慢。其次,测试是在禁用keepalive的前提下进行的,当Service的规模非常大时,内核需要遍历整个iptables来建立到后端Pod的连接,而iptables的时间复杂度为O(n),所以iptables的CPU占用比IPVS更高。如果开启keepalive,那么iptables的CPU占用的下降速度会比IPVS更显著。
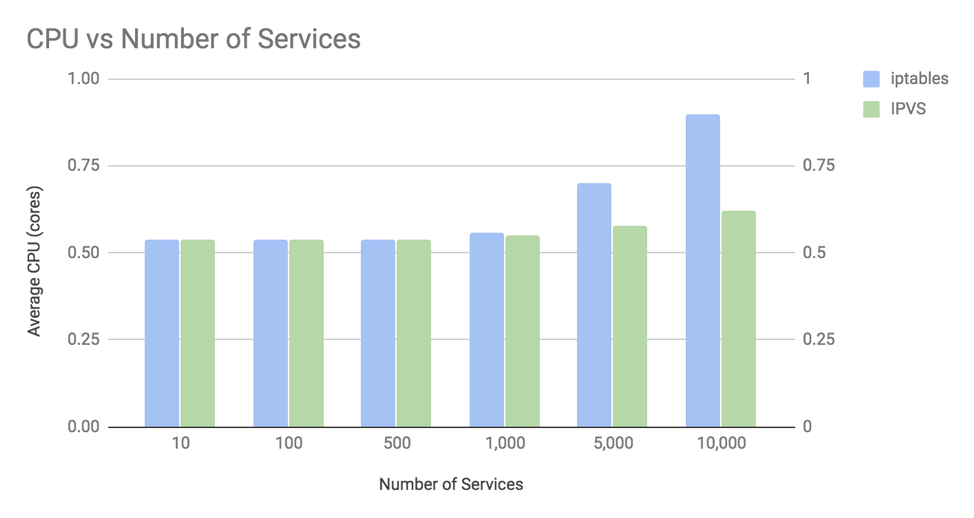
作者最后给出了一些提高性能的建议:如果集群规模非常大,那么IPVS会是更好的选择。此外,尽可能在新版本的Linux内核上运行Kubernetes集群和kube-proxy,如无特殊限制,保证keepalive处于开启状态。还有,相较于iptables只提供了轮询和会话亲和(SessionAffinity)两种负载均衡实现,IPVS则提供了非常丰富的选择:
- 静态调度
- 轮询(RR, Round Robin):按顺序轮流分配到实际服务器。
- 加权轮询(WRR, Weighted Round Robin):根据实际服务器的不同处理能力调度访问请求,使性能更好的服务器处理更多流量。
- 目标地址散列(DH, Destination Hashing):用请求的目标地址计算hash值,从散列表中查找服务器。
- 源地址散列(SH, Source Hashing):用请求的源地址计算hash值,从散列表中查找服务器。
动态反馈调度
最少连接(LC, Least Connections):动态将网络请求调度到已建立的连接数最少的服务器上。
加权最少连接(WLC, Weighted Least Connections):当集群中服务器性能差异较大的情况下使用,具有较高权值的服务器将承受较大比例的活动连接负载。
基于局部性最少连接(LBLC, Locality-Based Least Connections):针对 IP 地址的负载均衡,用于缓存集群系统。根据请求的 IP 地址找出该目标 IP 地址最近的服务器,若该服务器不可用,则用最少连接原则选出一个可用的服务器。
带复制的基于局部性最少连接(LBLCR, Locality-Based Least Connections with Replication):针对 IP 地址的负载均衡,根据请求的目标 IP 地址找出与之对应的服务器组,按最小连接原则选出一台服务器。若该服务器超载,就在集群中按最小连接原则选出一台服务器,添加到服务器组中。
最短延迟调度(SED, Shortest Expected Delay ):基于WLC进行了优化,只在当前处于活动状态的服务器集合中进行调度。根据公式
$ result = (c_i + 1)/u_i $
计算每个服务器的最终权重结果,其中$c_i$表示当前服务器 i 的连接数,$u_i$表示当前服务器 i 的权重。取结果最小的服务器来接收请求。
永不排队/最少队列调度(NQ, Never Queue)
IPVS尽管非常优秀,但是IPVS仍然有一些不足之处。Linux内核原生的IPVS不具备执行SNAT的能力,也就是说Kubernetes中Service如果有需要做SNAT的场景,那么单靠IPVS是无法实现其功能的。这种情况下,IPVS会退化成iptables模式完成Service的工作。IPVS退化成iptables的场景如下:
- kube-proxy启动时指定参数 ––masquerade-all=true,即集群中所有经过 kube-proxy 的包都做一次SNAT
- kube-proxy启动时指定参数 ––cluster-cidr
- 如果需要运行LoadBalancer类型的service
- 如果需要运行NodePort类型的service
- 如果Service配置了externalIP对外暴露服务
近年来新出现的BPF(Berkeley Packet Filter) 拥有比IPVS更好的能力和性能,在社区中已经出现了一些考虑用BPF取代IPVS的讨论。
涉及基础知识点
SNAT和MASQUERAD的区别
SNAT是指在数据包从网卡发送出去的时候,把数据包中的源地址部分替换为指定的IP,这样,接收方就认为数据包的来源是被替换的那个指定IP的主机。
MASQUERADE是SNAT的一个特例。MASQUERADE是用发送数据的网卡上的IP来替换源IP,因此,对于那些IP不固定的场合,比如通过DHCP分配IP的情况下,就得用MASQUERADE。
参考文献
- 1.Dawelbeit, Omer. "Getting Started with Kubernetes on Google Container Engine." IT with Passion. N.p., 2 Jan. 2016. Web. 1 May 2021.
- 2.Zhiguo, Li. "Kube-Proxy源码分析." rootdeep. N.p., 25 Dec. 2018. Web. 14 May 2021.
- 3.Kubernetes contributors. "User space proxy mode." Kubernetes. N.p., 15 Sept. 2020. Web. 14 May 2021.
- 4.Kubernetes contributors. "iptables proxy mode." Kubernetes. N.p., 15 Sept. 2020. Web. 14 May 2021.
- 5.Jun Du,Haibin Xie, and Wei Liang. "IPVS-Based In-Cluster Load Balancing Deep Dive." Kubernetes. N.p., 9 July 2018. Web. 8 May 2021.
- 6.Janos . "IPVS: The Linux Load Balancer (Deep Dive)." Have you Debugged.IT?. N.p., 8 Oct. 2020. Web. 8 May 2021.
- 7.Kubernetes contributors. "IPVS proxy mode." Kubernetes. N.p., 15 Sept. 2020. Web. 14 May 2021.
- 8.Ssup2 . "Kubernetes Service Proxy." Ssup2 Blog. N.p., 6 May 2019. Web. 9 May 2021.
- 9.Pollitt, Alex. "Comparing Kube-Proxy Modes: Iptables or IPVS?" Tigera. N.p., 18 Apr. 2019. Web. 9 May 2021.
- 10.setevoy. "Kubernetes: Service, Load Balancing, Kube-Proxy, and Iptables." rtfm.co.ua. N.p., 11 Jan. 2020. Web. 8 May 2021.
- 11.田飞雨. "Kube-Proxy Iptables 模式源码分析." 书栈网. N.p., 8 Mar. 2020. Web. 8 May 2021.
- 12.Calico contributors. "About Kubernetes Services." docs.projectcalico.org. N.p., n.d. Web. 8 May 2021.
- 13.Graf, Thomas. "Diagram of Kubernetes / Kube-Proxy Iptables Rules Architecture." GitHub. N.p., 8 Feb. 2018. Web. 8 May 2021.
- 14.Kubernetes contributors. "Service." Kubernetes. N.p., 5 May 2018. Web. 8 May 2021.
- 15.cloudvtech. "Kubernetes系列之一:Kubernetes如何利用iptables对外暴露service." CSDN. N.p., 31 Mar. 2018. Web. 8 May 2021.
- 16.Yingting, Huang. "Kubernetes Services and Iptables." msazure.club. N.p., 5 Feb. 2019. Web. 8 May 2021.
- 17.Serena . "Deep Dive Kube-Proxy with Iptables Mode." Serena Blog. N.p., 26 Mar. 2020. Web. 8 May 2021.
- 18.Tianyi, Gu. "LVS负载均衡学习笔记." TianyiGu’s Blog. N.p., 27 May 2018. Web. 9 May 2021.
- 19.MornigSpace. “Kubernetes Network-ExternalIP and NodePort." Qinggen Xiaozhu. Np, 9 May 2021. Web. 23 May 2021.
- 20.Wikipedia contributors. "Martian packet." Wikipedia, The Free Encyclopedia. Wikipedia, The Free Encyclopedia, 24 Jan. 2021. Web. 23 May 2021.
- 21.Baker, Fred, ed. "Requirements for IP version 4 routers." RFC 1812(1995): 1-175. RFC Editor. Web. 23 May 2021.
- 22.Kubernetes contributors. "Fix Nodeport Localhost Martian Source Error." GitHub. N.p., 15 Jan. 2018. Web. 26 May 2021.
- 23.admin. "How to Interpret Linux Martian Source Messages." The Geek Diary. N.p., n.d. Web. 26 May 2021.