Kubernetes网络架构要求集群内的任意两个Pod之间可以在无需NAT的前提下进行通信。在集群中一共有四种Pod间通信的场景:Pod内容器之间相互通信、同一个节点内多个Pod之间相互通信、不同节点上的多个Pod之间相互通信以及Pod和Service之间的通信。其中,Pod和Service之间的通信过程分析请移步到《K8s network之五:Kubernetes集群Pod和Service之间通信的实现原理》,本文会着重分析多容器Pod内、同一节点上的Pod之间以及不同节点上的Pod之间的通信过程。出于篇幅考虑,相关的yaml配置不会在文章中出现,特殊情况除外,相关的yaml配置可以参考Kubernetes官方文档。
2. K8s network之二:Kubernetes的域名解析、服务发现和外部访问
5.K8s network之五:Kubernetes集群Pod和Service之间通信的实现原理
Pod内容器之间通信过程
在kubernetes集群中,每个Pod会被分配一个IP地址。同一个Pod内的多个业务容器会共享这个IP地址对外通信,同时,这些容器之间也可以直接通过localhost:端口号的方式进行通信。为了实现Pod内容器之间的通信,Kubernetes利用pause容器和Docker的container模式网络这两个工具来达成目的。
Docker在创建业务容器的时候可以通过命令参数—network=container:NAME_or_ID来创建一个container模式的网络结构。在这种场景下,新创建的业务容器会加入NAME_or_ID指定的容器的网络命名空间中,与指定的容器共享同一个网络栈、对外使用同一个IP地址或者MAC地址进行通信、相互之间也可以直接使用localhost:端口的形式完成通信。如果业务容器执行了重启动作并再次以—network=container:NAME_or_ID完成创建操作,就可以实现重启前后拥有相同的IP地址信息。除非NAME_or_ID指定的容器被重启,否则当前Pod会始终拥有一个固定的IP地址,Pod内的业务容器亦是如此。Kubernetes的Pod内网络实现就是借鉴了Docker的这种模式来实现Pod内多个容器之间的相互通信的。
接下来我们回顾下在Kubernetes集群中一个Pod是如何产生的,大致流程可参考图2所示:
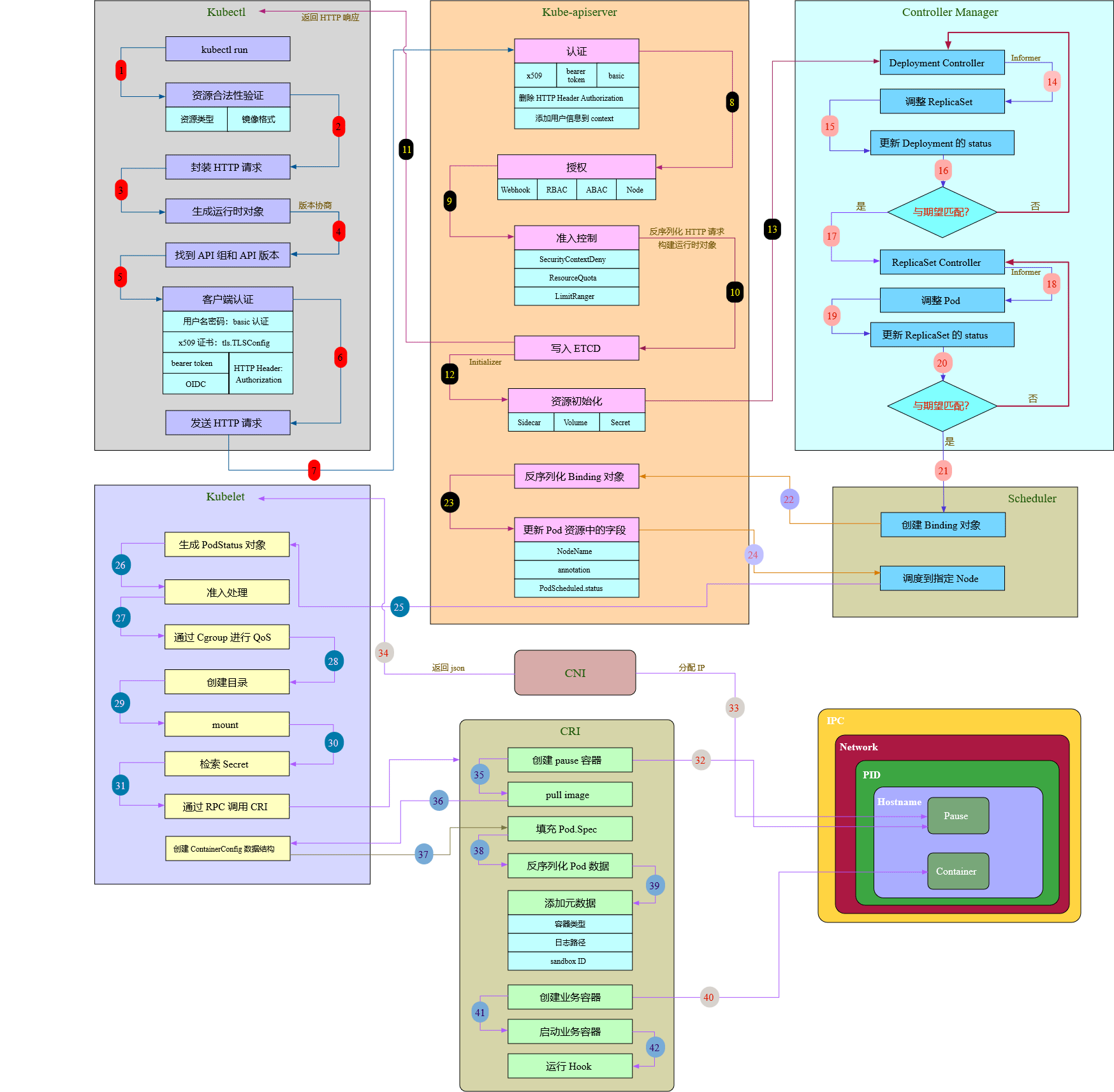
图 - 2 Pod创建流程[1]
现在我们把目光放在CRI这里,在Pod创建的校验、准备工作都做好之后会通知CRI来执行Pod的创建逻辑。由图2可知,pause容器将会是Pod中第一个被创建的容器,pause容器是一个非业务相关的、功能十分简单的特殊容器。我们知道,Pod是一个或一组容器的集合,基于Linux的namespace和cgroups,为容器提供了隔离的环境。每个Pod中都会有一个pause容器,Ian Lewis在他的文章《The Almighty Pause Container》[2]中指出pause容器在多容器Pod中起到了一个类似于”父容器“的作用,在某些文章中,它也被称为infra container,它承担了两个重要的职责:
pause容器是Pod中Linux命名空间共享的基石
在Linux中,子进程会继承其父进程的命名空间。当然,你也可以通过unshare工具来创建一个拥有新的、独立的命名空间的进程。如果一个进程A处于运行状态,那么就可以将别的进程加入到A的命名空间中,这样就形成了一个Pod。Linux中通过系统调用setns就可以实现将一个进程加入到一个已经存在的命名空间的功能。Pod中的多个容器之间会共享命名空间,Docker的出现够使得Pod中的多个容器之间共享命名空间更容易一些:
首先,通过docker启动一个pause容器。我们都知道容器的隔离是通过Linux内核的namespace命名空间机制来实现的,只要一个进程一直存在,它就会一直拥有一个命名空间。所以当pause容器就绪后,我们就得到了一个网络命名空间。我们可以在这个网络命名空间中加入新的容器来构建一个关联紧密的容器组。接着,我们可以继续启动新的容器,需要注意的是,在这个过程中我们始终将新启动的容器加入到pause容器的命名空间中。当上述这个过程完成后,一个Pod就形成了,这个Pod内的多个容器之间会共享同一个网络命名空间,而这个命名空间是属于pause容器的。这些容器之间可以直接通过localhost和端口来相互访问。
当Pod内PID命名空间共享开启后,pause容器的地位等同于PID为1的进程,同时还负责Pod中僵死进程的回收工作
Linux中处于一个PID命名空间下的所有进程会形成一个树形结构,除了PID=1的”init“进程之外,每个进程都会有一个父进程。每个进程可以通过系统调用folk和exec来创建一个新的进程,而调用folk和exec的进程就会成为新创建进程的父进程。每个进程在操作系统的进程表中都会有一个记录,这条记录包含了对应的进程当前的状态和返回码等诸多信息。当一个进程结束其生命周期后,如果它的父进程没有通过系统调用wait获取返回码释放子进程的资源,那么这个进程就会变成僵死进程(zombie processes)。僵死进程不再运行,但是进程表中的记录仍然存在,除非父进程完成了子进程的回收工作。一般情况下,僵死进程的存在时间会非常短,但是世事无绝对,又或者如果僵死进程的数量太大,还是会浪费相当可观的系统资源的。僵尸进程一般由其父进程完成回收工作,但是如果父进程在子进程结束之前就已经结束运行的话,那么操作系统就会指派PID=1的”init“进程成为子进程新的父进程,由”init“进程调用wait获取子进程的返回码并完成子进程的资源回收和善后工作。
在Docker中,每个容器都有其自己的PID命名空间,同时又可以将一个容器A加入到另一个容器B的命名空间中。此时,B就承担了”init“进程的职责,而诸如A等被加入到B的命名空间的容器就是”init“进程的“子进程”。假设一个Pod中没有pause容器只有业务容器,那么第一个创建的容器就需要承担起”init“进程的责任—维护命名空间、回收僵死进程等。但是业务容器可能并没有这样的能力来完成这些任务。所以kubernetes在Pod创建过程中会第一个将pause容器创建出来,整个Pod的网络命名空间就是pause容器的命名空间,pause容器会肩负起”init“进程(PID=1)的职责,同时完成僵死进程的回收工作。这就是为什么Pod中会有一个pause容器的原因。
”init“进程和僵死进程的概念只有在Pod内PID命名空间共享开启后才有意义,如果PID命名空间未共享,鉴于Pod中的每个容器都以PID=1的”init“进程来启动,所以它需要自己处理僵死进程。尽管应用通常不会大量产生子进程,所以一般情况下不会有什么问题,但是僵死进程耗尽内存资源确实是一个容易忽视的问题。此外,开启PID命名空间共享也能够保证在同一个Pod的多个容器之间相互发送信号来进行通信,所以Kubernetes集群默认开启PID命名空间共享真的是非常有益的。
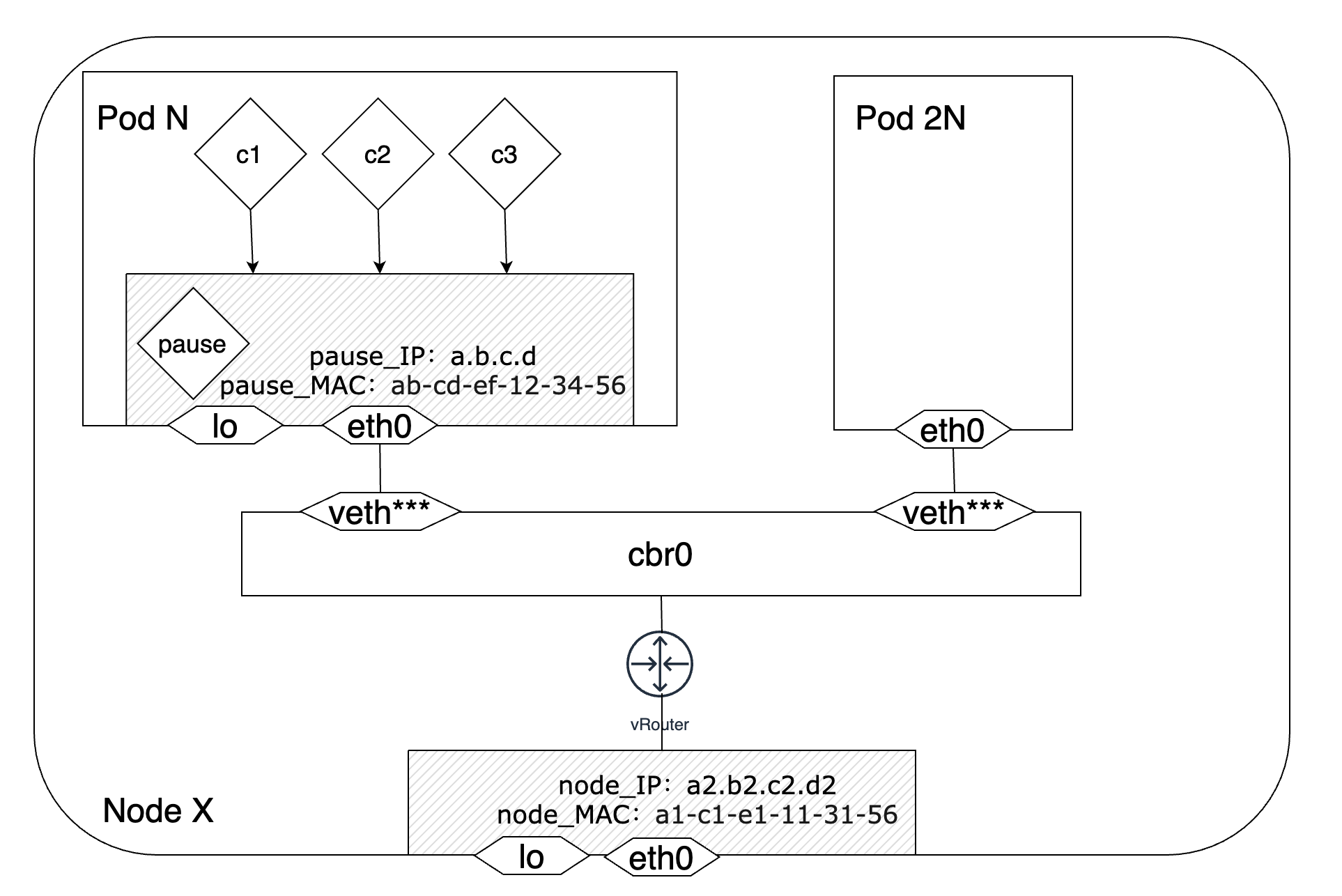
继续关注图2,前面提到,业务容器的创建用的是docker的container模式网络,而pause容器的创建用的是docker的none模式网络。CRI只负责给pause容器生成一个network namespace,CNI会完成pause容器的网络配置,包括但不限于网络接口、IP地址、MAC地址等。CNI插件会先调用IPAM插件完成IP地址的申请和分配工作,之后由CNI插件完成pause容器的网络接口eth0的创建和配置工作,由IPAM得到的IP地址也会配置这个eth0接口上。最后,会通过veth-pair将这个Pod接入所在节点的网络,此时,这个Pod就成功地创建并可以和其他Pod相互通信了。veth-pair都是成对出现的,一端在pause容器的网络namespace中,另一端在所在节点的cbr0网桥上。在图2中我们看到Pod端并没有对应的veth***,而是一个eth0接口。它其实就是veth对的另一端,Kubernetes把Pod的eth0通过veth-pair连接到所在节点的网桥上,成为该节点网桥上的一个”从属设备“,实质上就是该网桥的一个端口,此时这个”从属设备“或者说端口(也就是这个Pod)只剩下了收发数据包的能力,其他诸如数据包转发、丢弃等功能均由网桥来负责实现。
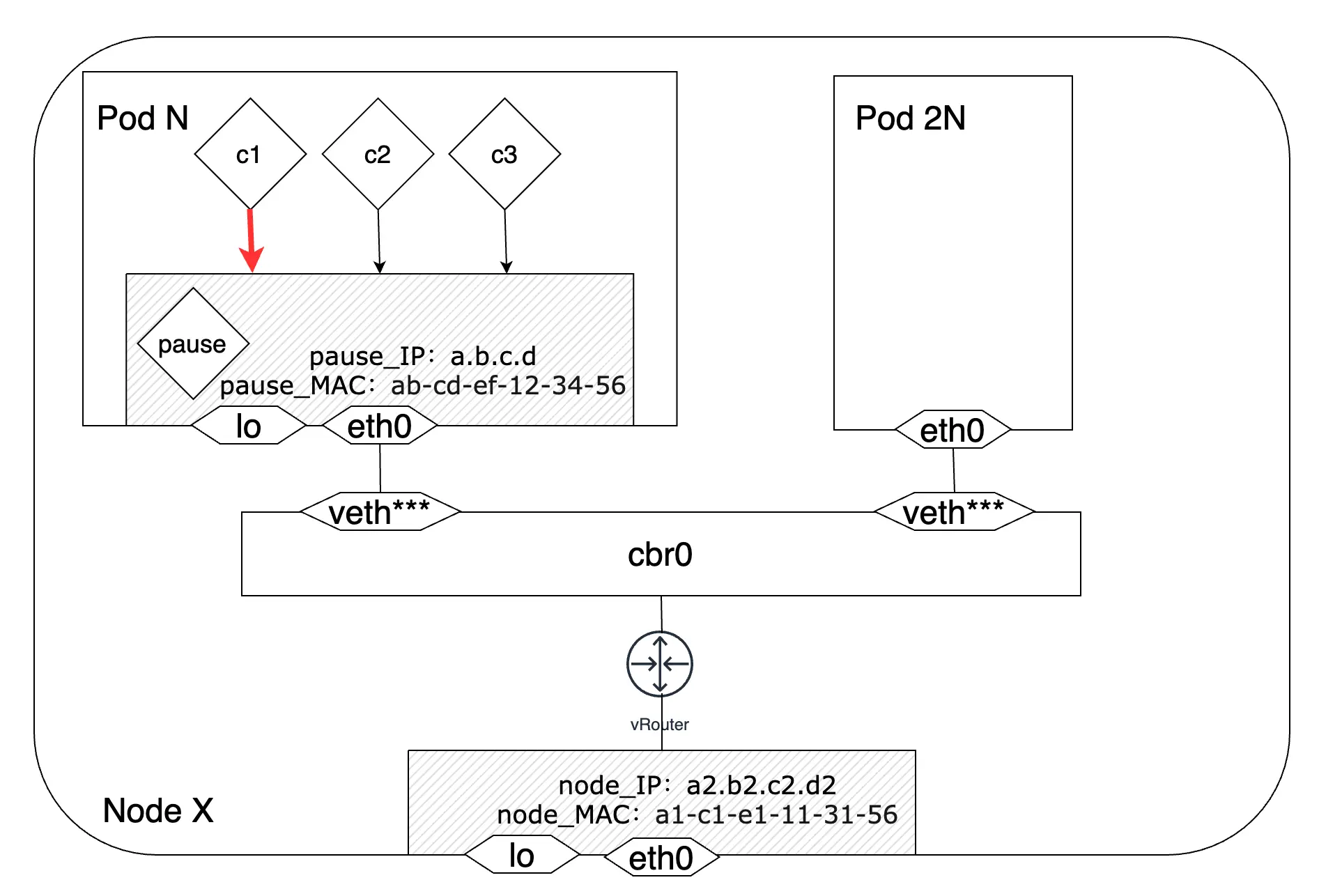
因为同一个Pod内的多个容器之间共享pause容器的网络命名空间进而可以通过localhost:端口的形式相互访问,所以它们之间相互通信的流量并不会经过eth0接口。
同一个Node内多个Pod之间通信过程
Docker组建单主机容器网络时默认采用的是桥接网络结构,当Docker进程开启后,Docker会在宿主机上创建一个docker0的linux虚拟网桥,这是一个二层设备,它会学习每个端口连接的网络设备的MAC地址信息并通过MAC地址将数据包转发到正确的目的设备上。宿主机上的容器通过veth-pair连接到这个网桥上,并且以网桥作为容器的默认网关来实现与宿主机外实例的通信。
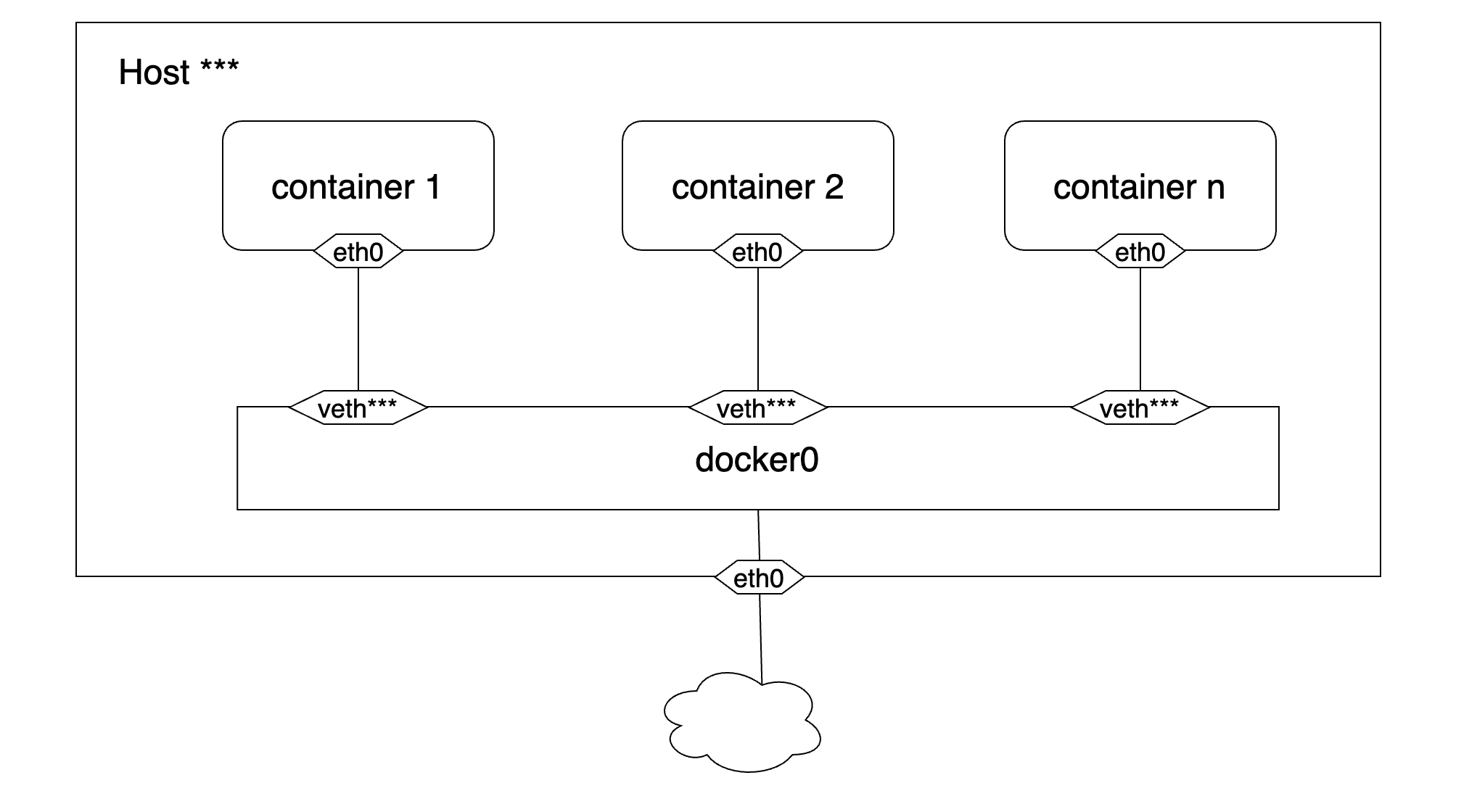
Kubernetes在组建节点内网络时同样采用了docker的桥接网络结构。每个节点有一个根网络命名空间(root network namespace),负责该节点的对外通信,Linux内核提供的路由功能记录了节点eth0接口和网桥cbr0的IP地址信息。因为节点的eth0和网桥cbr0通常不在一个网段,所以这两个节点的通信就通过Linux内核提供的路由功能来实现。除了Docker里采用的是docker0网桥而Kubernetes改成了cbr0网桥之外,这两者的网络结构基本相似。
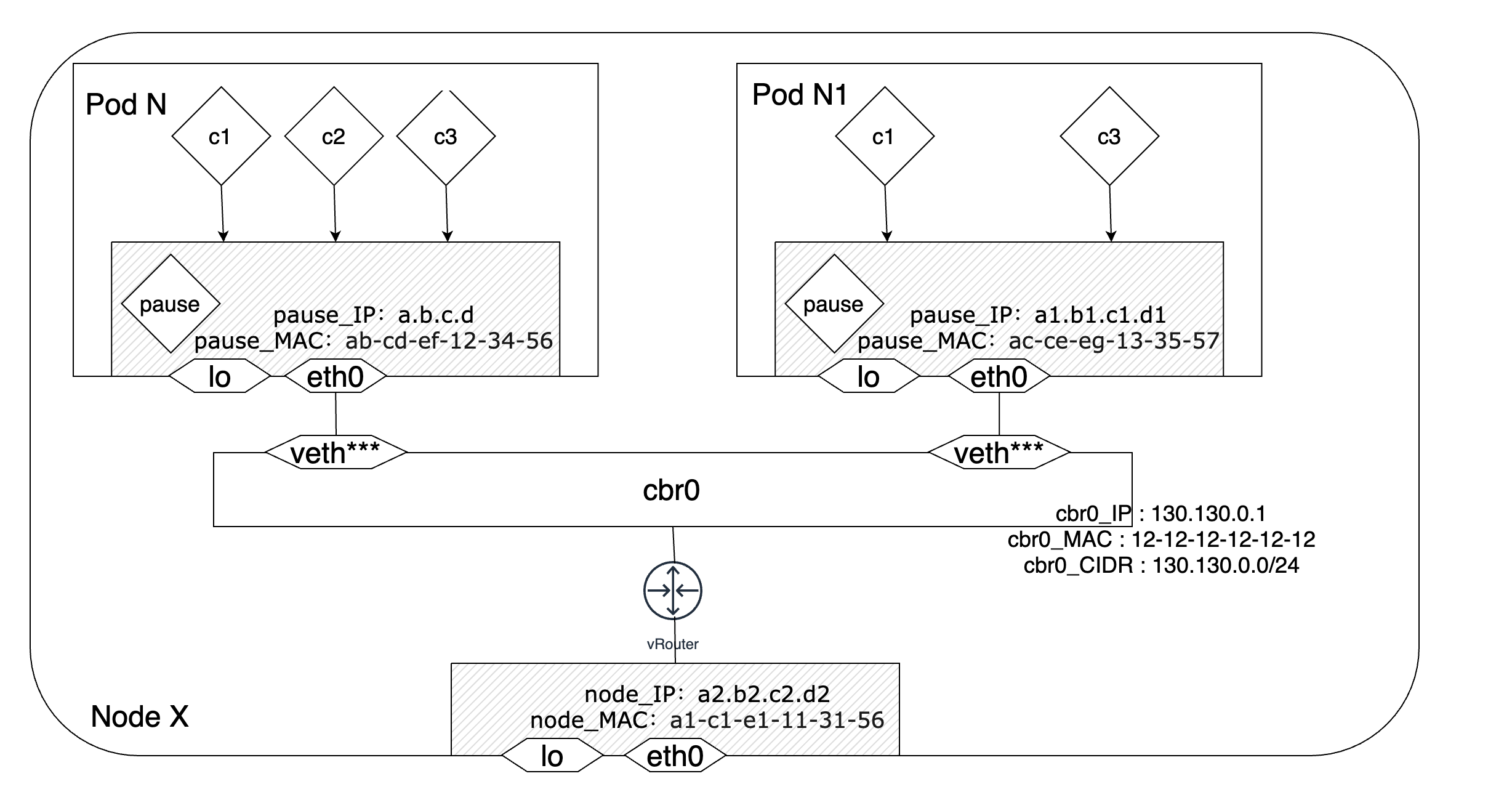
cbr0网桥是一个由Linux内核构建出来的虚拟的二层网络设备,它将两个及以上的网段连接在一起,扩大了网络的规模。网桥维护了一张转发表,这张表包含了每个端口的信息、该端口映射的MAC地址、IP地址和MAC地址映射关系等信息。借助于这张转发表,网桥就可以根据收到的报文中包含的源/目的地址信息将其转发到对应的端口上。节点内的每个Pod在创建时会从所在节点的IP地址集合中得到一个IP地址,并通过veth-pair将自己和cbr0网桥连接起来。同时,cbr0网桥也是每个Pod的默认网关。这样,节点内的诸多Pod和cbr0网桥就构成了一个网段相同的局域网,cbr0通过ARP报文学习连接在其上面的每个设备(Pod)的MAC地址信息,并将接收到的报文依据其指明的目的MAC地址转发到对应的设备上,实现Pod间的相互通信。换句话说,同一个节点里的Pod之间的通信不会经过vRouter,更不会经过节点的eth0接口。如果Pod要和节点外的实体通信,那么就会将报文通过通过vRouter和eth0转发到集群外完成通信过程。
当目的Pod和源Pod不在同一个网段中时,cbr0网桥就以网关的身份将数据包转发到Linux内核,并根据iptables的路由规则将其转发合适的路径上。具体过程可浏览不同节点之间多个Pod的通信过程。
不同Node节点之间多个Pod的通信过程
直接路由方案
实际的生产系统集群通常是由多个节点构成的,那么如何将这多个节点连接起来形成一个完整的相互联通的网络就成为首要问题。最简单的解决方案就是直接采用直接路由的方案,也就是在每个节点上配置集群中其他节点的地址信息,通过IP转发的方式实现跨节点Pod的通信,基本的网络架构模式如图8所示:
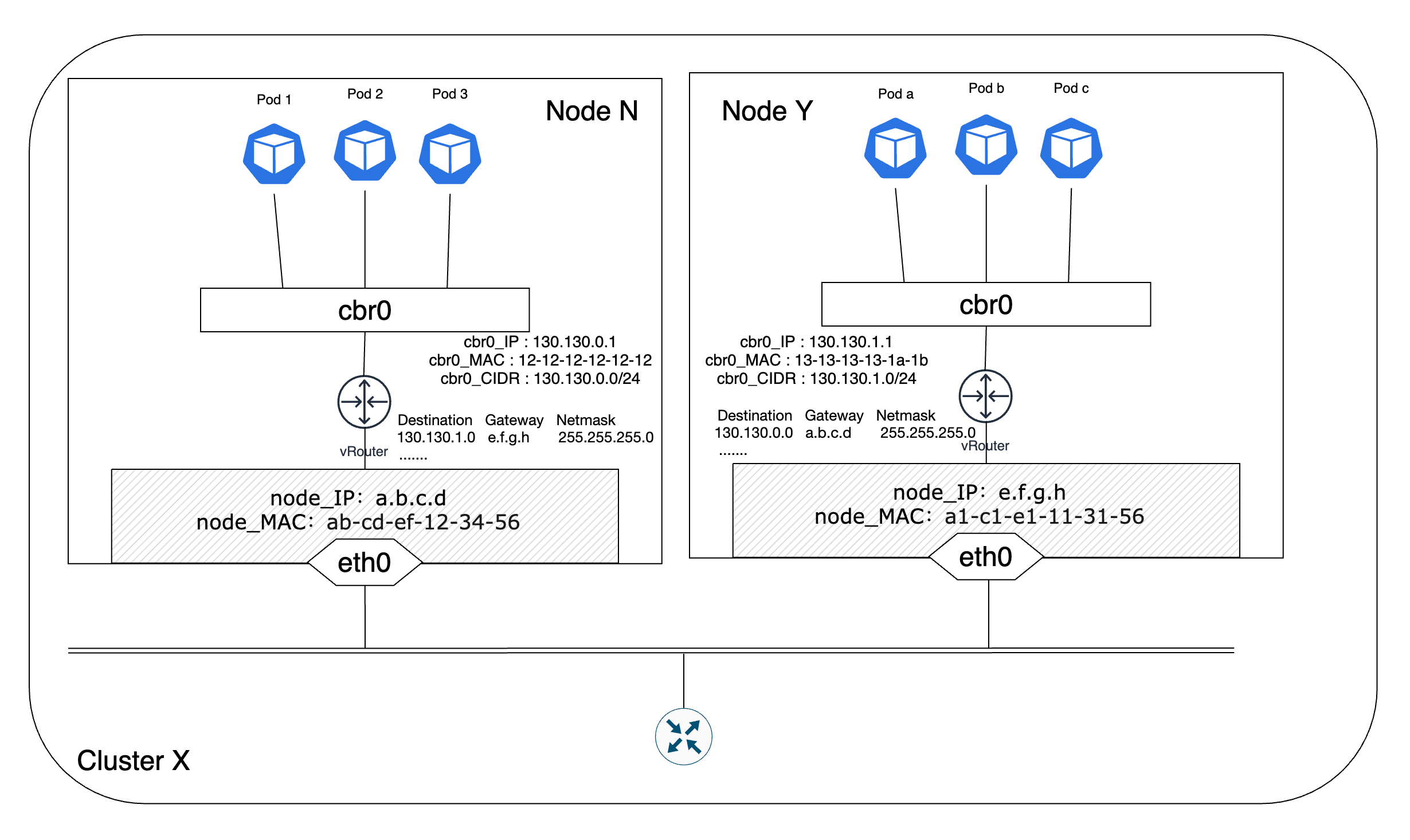
节点N中的某个Pod 1想与节点Y中的Pod b通信,那么Pod 1就会发起一个请求并传给节点N的cbr0网桥,网桥发现目的地址不在其所辖的网段,于是就将请求转发给了vRouter,vRouter通过查询路由表知道目的地址所在的网段,就将请求的目的MAC地址修改为节点Y的eth0端口的MAC地址。节点Y收到请求后发现目的MAC地址指向自身,继续将请求通过节点Y上的vRouter转发给cbr0网桥,网桥根据目的IP地址查找对应的MAC地址,之后将请求转发到对应的端口上,这样节点Y上的Pod b就收到了来自Pod 1的请求,并且Pod b看到的源IP和目的IP分别为Pod 1的IP地址和自己的IP地址。
【Note】:在图-8及之前的配图中有一个vRouter图例,它代表的是Linux内核提供的路由功能,借助于iptables/netfilter等工具,Linux就具备了路由器的路由转发能力。同时,节点的eth0接口可以看成是Linux这个“路由器”的一个端口。
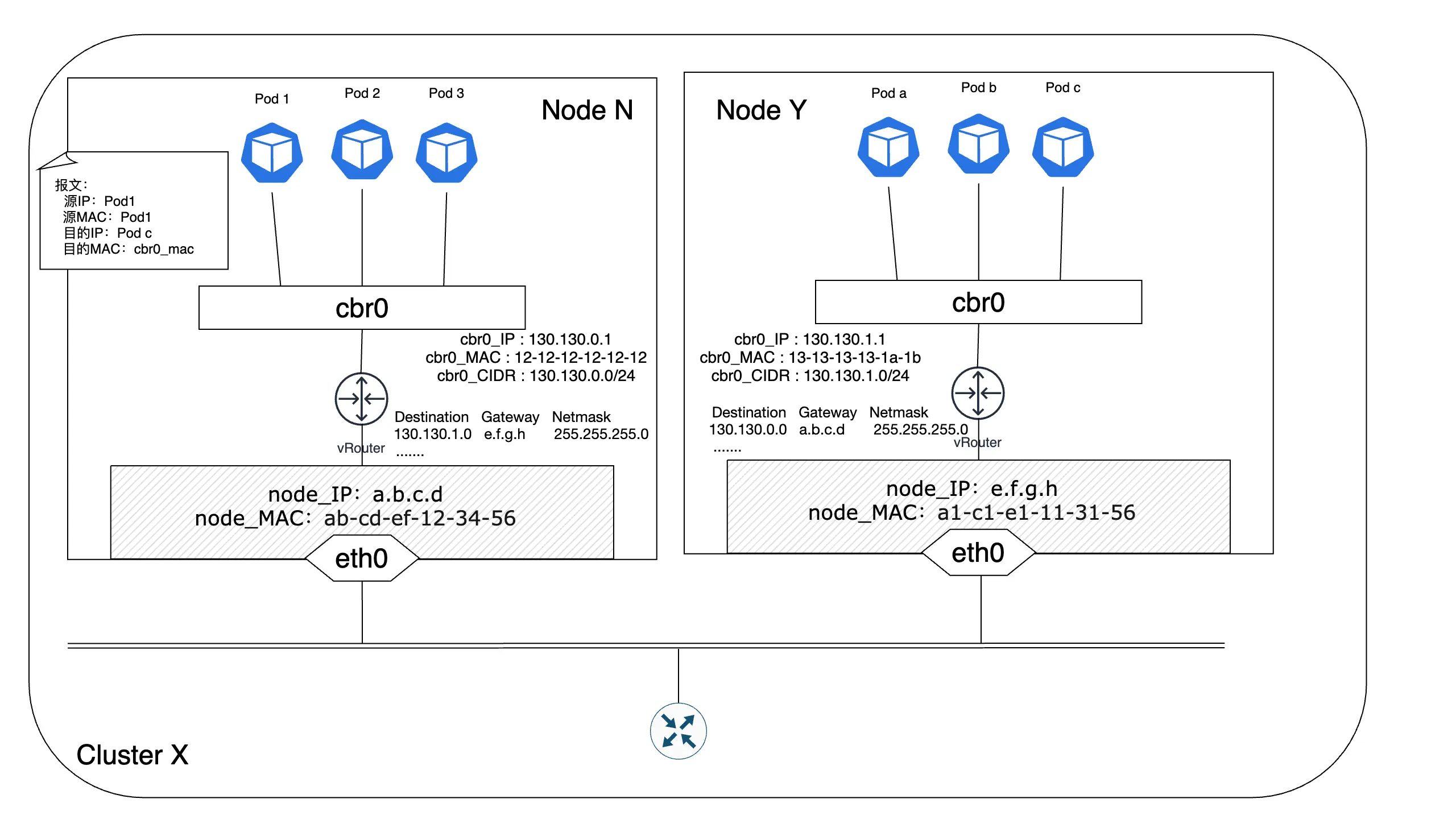
直接路由方案虽然相对来说简单一些,但同时也有一些问题。在集群中的每个节点都需要配置非自身节点的路由信息来与其他节点通信,如果集群中节点的数量非常大,那么这个配置过程将会非常繁琐。如果向集群中加入新的节点,或者剔除因故无法继续工作的节点,同样需要更新集群中所有其他节点的路由信息,大大增加了集群网络管理的复杂性、成本和出错概率。还有,如果集群中节点规模非常大的话,有可能会造成路由表规模的膨胀,尽管有一些机制来应对路由表规模膨胀所带来的性能下降问题,但这依旧是一个不容忽视的问题。当然,你也可以借助BGP、RIP、OSPF等动态路由协议来完成集群节点之间的路由发现,一定程度上可以降低集群节点路由配置的成本。
Overlay网络方案
除了上述提到的路由方案,其实还有一种更主流的跨主机网络构建方案—Overlay网络架构。在《K8s network之一:K8s网络模型与网络策略》中,我们已经对Overlay网络进行了一个简单的介绍。一些流行的CNI插件诸如Flannel、Weave等都提供了基于Overlay网络的跨主机组网实现方案。Overlay可以在无需变更现有底层物理网络配置的前提下,通过网络协议和报文封装等方式来构建一个可以运行在物理网络上的逻辑网络。鉴于此,Overlay可以更灵活地针对业务需求的变化和迭代来构建满足要求的网络环境。
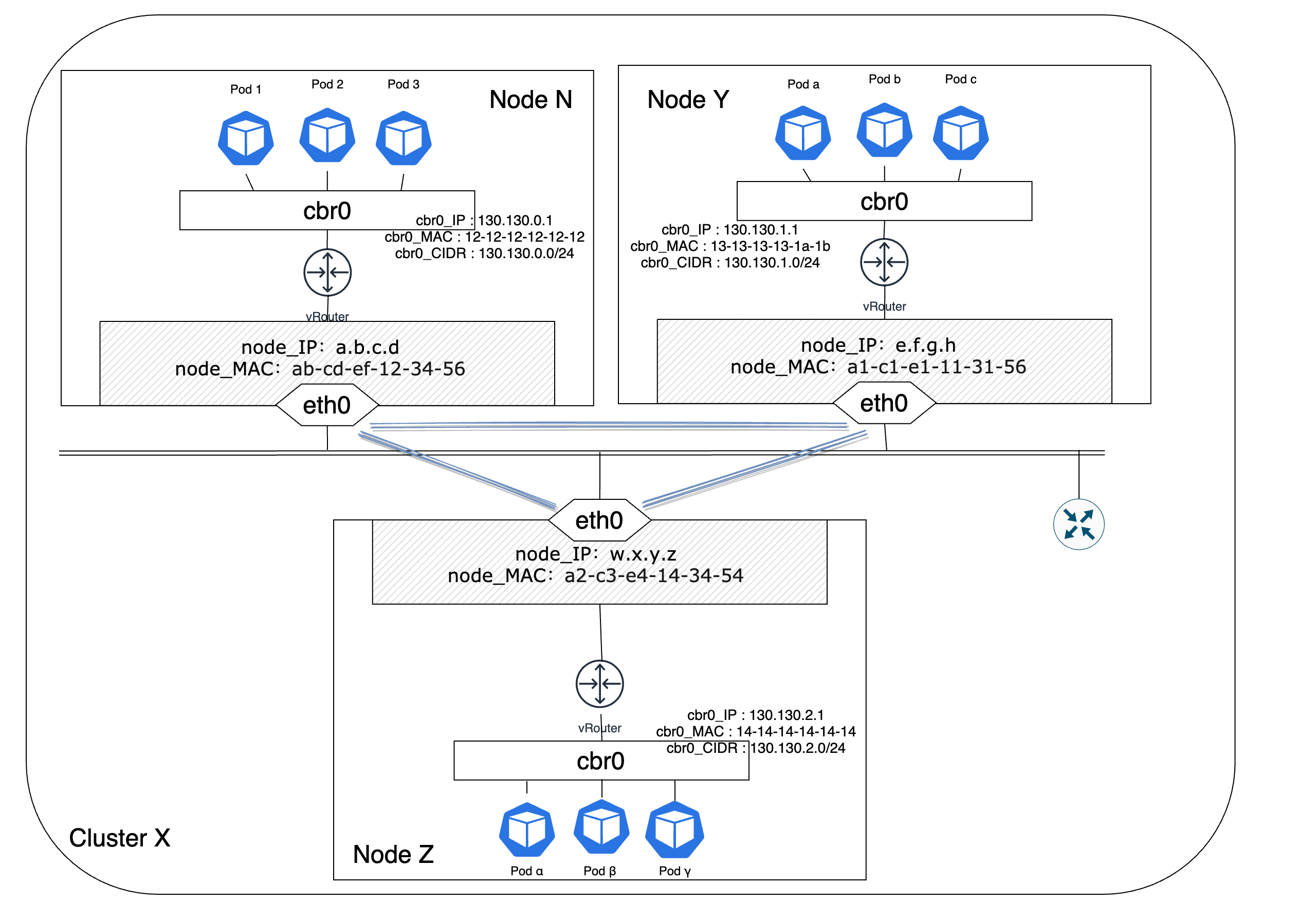
图 - 10 Pod跨节点通信Overlay网络架构
在Overlay网络架构下,CNI插件会在各个节点Node之间建立可通信的虚拟隧道,报文在发出节点之前会在VTEP设备上被封装成规定的格式并在隧道中传递,在目的节点收到报文后同样会在VTEP设备上对报文进行解封装并发送给目的Pod。接下来会以最常见的Flannel插件为例来了解Overlay网络下Pod之间是如何完成跨节点通信的。Flannel是由CoreOS公司为Kubernetes设计的一个开源的虚拟网络方案实现产品。flanneld代理是Flannel运行在每个节点上的一个守护进程,它负责为每个节点分配一个互不重叠的IP子网范围,节点上创建Pod所需的IP地址均来自于此。在flannel的运行环境中,etcd会负责维护网段和节点的映射关系,flanneld在运行过程中会与etcd通信,从中获取IP子网范围,也正是因为所有的flanneld都是从etcd中获取IP子网,所以保证了每个节点的IP子网可以互不重叠。在拿到IP地址范围后,通过配置Docker的启动参数—bip(bridge network IP)的值为获得IP地址范围来配置所在节点的IP地址池。同时,flanneld还兼有更新节点的路由信息以及和其他节点交换、同步路由信息的功能。Flannel为了实现集群网络的互联互通,实现了如下的两个基础目标:
- 集群中的每个节点都有一个IP地址子网,且任意两个节点间的子网范围互不重叠
- 集群中的节点之间建立一个逻辑的Overlay网络,数据包在这个网络上传递
Flannel在较早些版本中是使用的UDP模式来构建Overlay网络的,出于性能等因素的考虑,在后来的版本中采用了更高效的VXLAN来实现Overlay网络。Flannel通过配置文件来决定采用何种backend模式来完成网络构建,如果—kube-subnet-mgr的值为true,那么Flannel就会从/etc/kube-flannel/net-conf.json读取配置,否则就会从etcd读取(默认从配置文件/coreos.com/network/config读取,可以借助参数—etcd-prefix覆盖之)。配置文件的构成如下所示:
1 | { |
- Network:以CIDR格式规定了整个Flannel网络的IPv4网络范围。这个参数也是唯一一个必填的参数
- SubnetLen:分配给每个节点的子网大小,默认是24(也就是“A.B.C.D/24”)。如果Network字段IP网络的网络号位数大于24,那么SubnetLen会比Network字段IP网络的网络号位数大一。比如,如果Network字段配置的是“10.0.0.0/26”,那么subnetLen就是27
- SubnetMin:子网划分和分配可用的起始子网范围,默认为Network字段IP网络的第一个子网(也就是网络号最小的子网)
- SubnetMax:子网划分和分配可用的最后一个子网范围,默认为Network字段IP网络的最后一个子网(也就是网络号最大的子网)
- Backend:指定采用VXLAN、UDP、host-gw哪种模式完成网络构建。默认是UDP。Flannel除了这三种模式外,还有一些处于开发和试验中的模型,各个模式的介绍及其需要填充的参数可参考Flannel的官方文档[3]
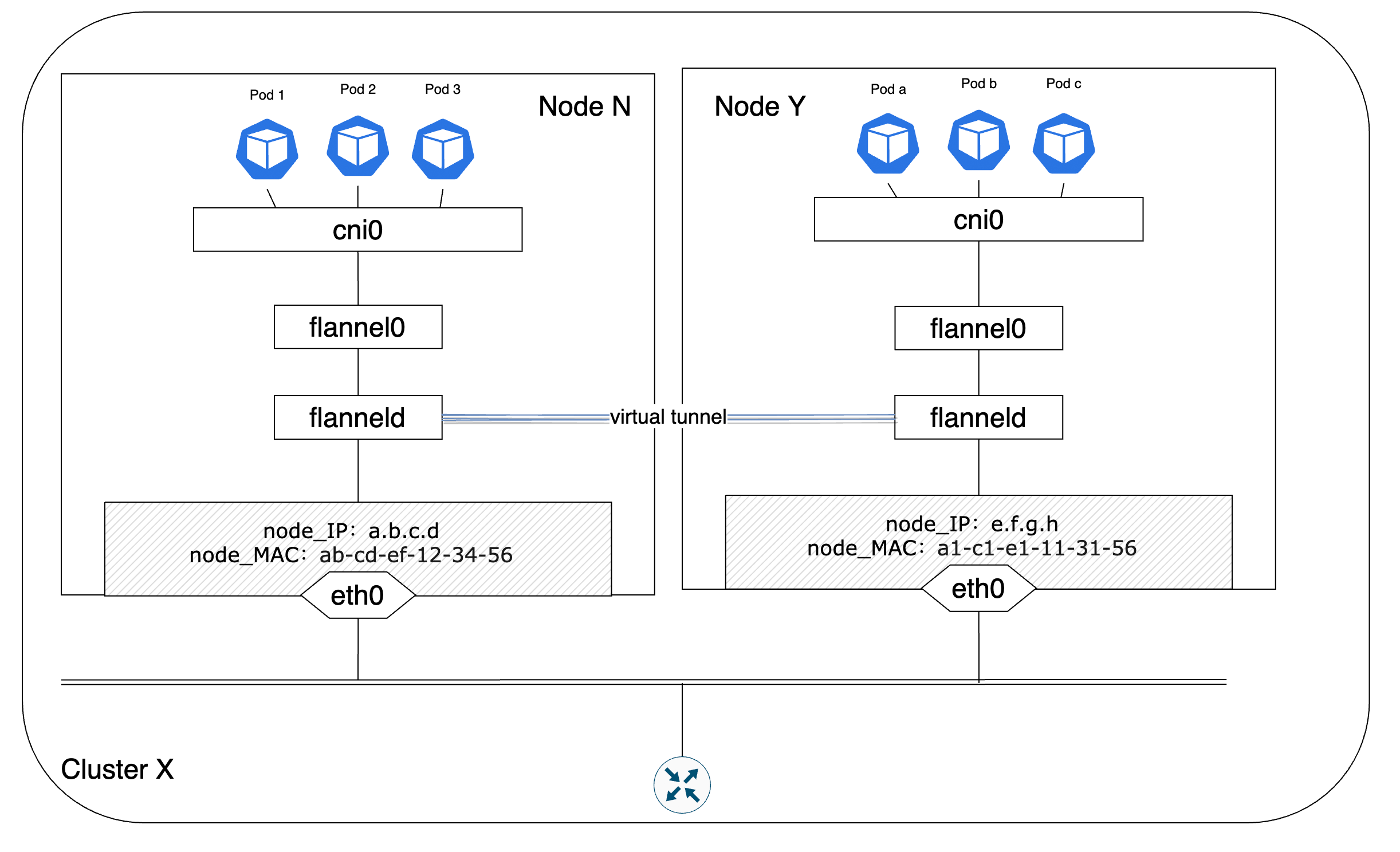
【Note】在早期的Flannel版本中网桥标识是docker0,在后来的版本迭代中才变成了cni0。但无论如何,两者指代的都是同一个组件—Linux虚拟网桥
在图11中有一个flannel0图例,flannel0是由flanneld进程生成的一个tun设备,tun是Linux内核实现的一种虚拟的三层网络设备,因此能够提供和硬件设备类似的IP数据包的处理能力。利用tun设备,可以实现用户空间和内核空间之间的数据传输。根据流量的流向,flannel0提供了不同的对数据的操作能力:
- 当IP数据包被写入到flannel0接口时,数据包会被直接发送给内核最后传递到cni0网桥上,cni0会根据数据包的目的地址信息将该数据包转发到对应Pod上
- 当IP数据包进入内核且根据路由表的匹配结果表明该数据包需要被转发给flannel0时,内核会将该数据包直接发送给创建flannel0的flanneld进程处理
为了避免引起歧义,写入到flannel0接口指的是数据包由flanneld进程解封并发送给flannel0设备,相应地,数据包进入内核指的是数据包由cni0网桥被转发给flannel0设备。
在UDP模式下,Pod 1如果想与跨节点的Pod c通信,那么首先会向Pod 1的默认网关cni0网桥发送数据包。cni0在确定目的地址不在cni0所辖网段后就会将数据包转发给flannel0设备。flannel0在收到数据包后就会由flanneld进程根据当前节点上维护的路由表条目信息对数据包进行UDP封装。除了原始的IP数据包外,封装后的数据包还包括目的地址用来监听Flannel请求的端口号,以及封装包的源和目的地址。其中,Pod 1所在节点的节点IP和节点MAC地址是封装包的源IP和MAC地址,Pod c所在节点的节点IP和MAC地址是封装包的目的IP和MAC地址。flanneld将数据包封装后就会通过节点的eth0接口将数据包发送到网络上。当目的节点在监听Flannel请求的端口上收到了封装数据包后会验证目的IP和目的MAC与自身节点的匹配情况。如果确定自身是数据包的目的地后,会将数据包解封装后发送给节点的flannel0设备,flannel0继续将数据包转发给cni0网桥,由网桥将数据包发送给目的Pod。
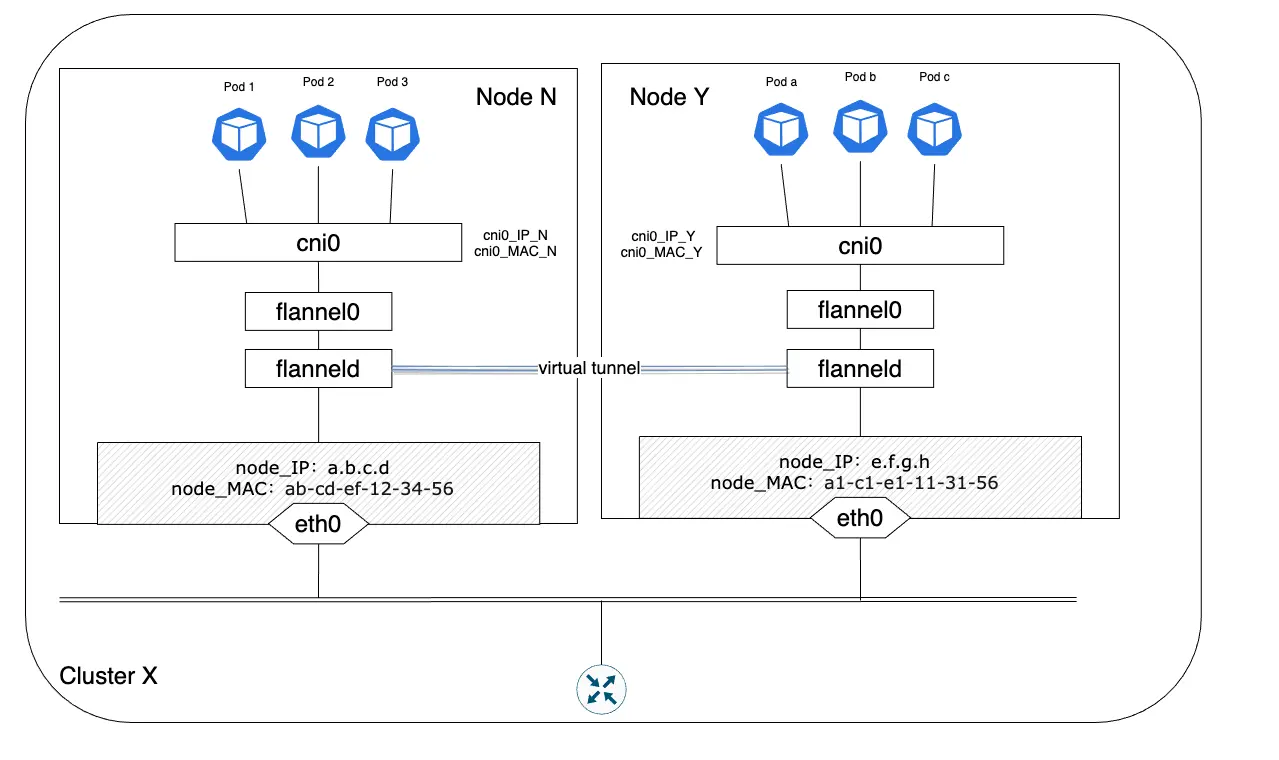
UDP模式下数据包需要通过源节点上的用户空间 -> 内核空间以及目的节点上的内核空间 ->用户空间两次转换,所以实际过程中通信效率会稍微有点差强人意。鉴于UDP模式的性能并不理想,后续的Flannel版本开始尝试用VXLAN来实现Overlay网络的构建,将flanneld封装/解封装的过程交由Linux内核处理,以此通过避免UDP模式里的两次转换来提高性能。
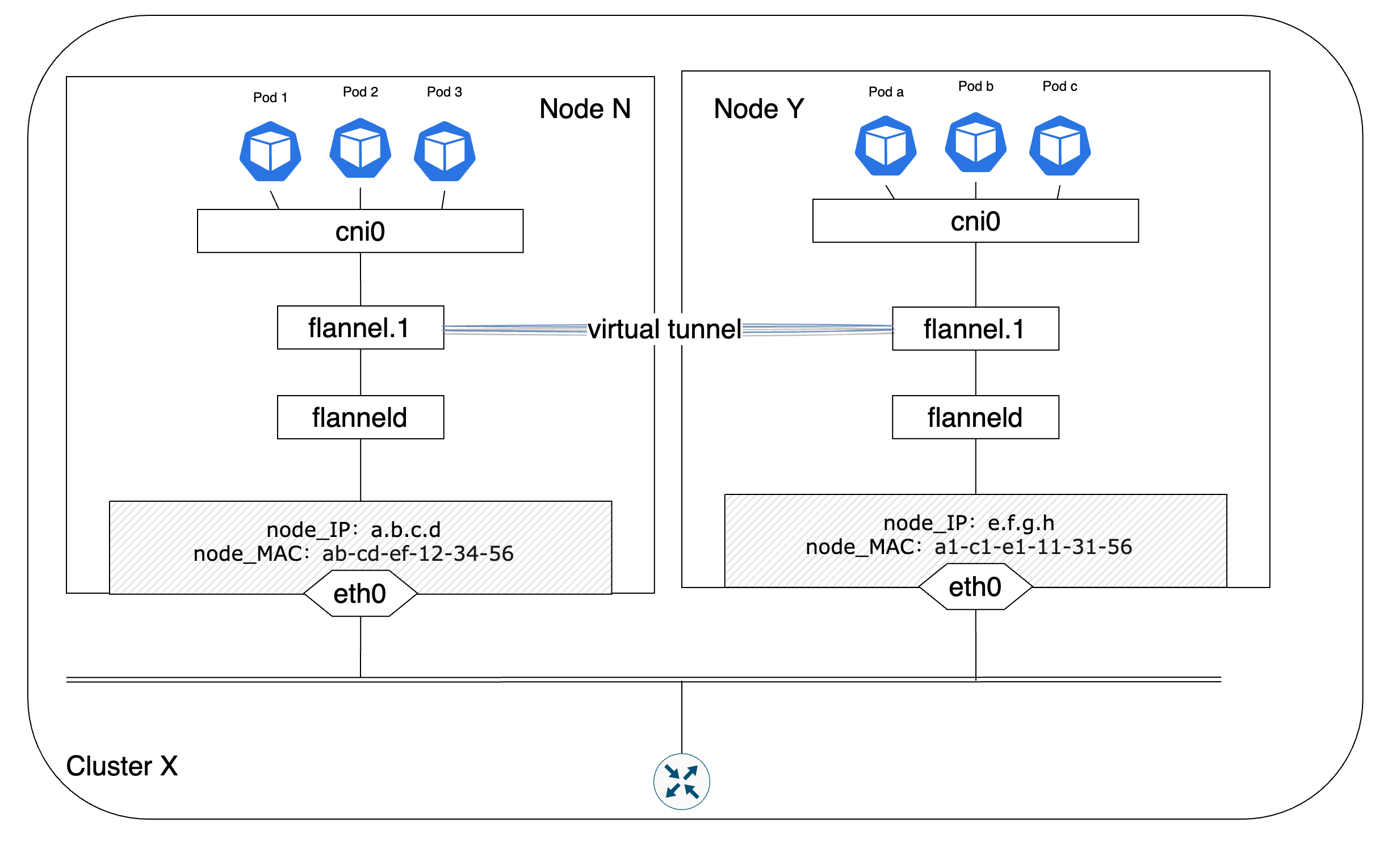
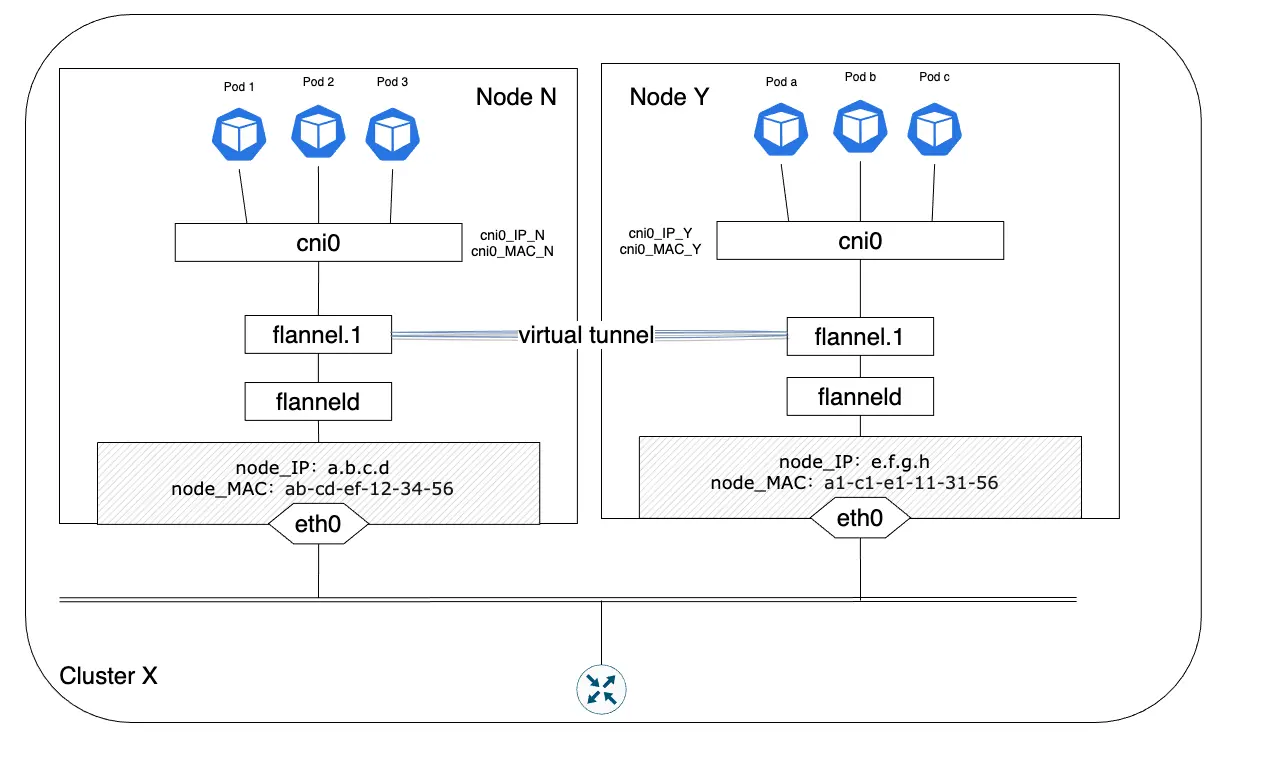
上图中”flannel.1“代表了VXLAN中的一个VTEP设备,命名格式是”flannel.<vni>“,vni默认从1开始编号。数据包的封装/解封装均由VTEP设备flannel.1完成,flanneld不再参与这个过程,而是负责VTEP设备的维护工作。在flanneld启动过程中会先保证VTEP设备flannel.1存在,如果flannel.1存在的话就跳过这个过程。之后flanneld会持续的和etcd保持联系,获取其他节点VTEP设备地址信息的变动情况并更新所在节点的ARP表、FDB(Forwarding database)表、iptables等,以及将自己所在节点的IP地址变化情况发送给etcd。经过flanneld的同步和更新操作,每个节点上的flannel.1都能知道其他节点的IP/MAC信息并发起通信。
在实际工作过程中,Pod1首先将IP数据包发送给cni0网桥,cni0网桥在确定目的Pod不在当前所处子网后会将IP数据包转发给VTEP设备flannel.1,flannel.1会向flanneld请求目的Pod所在节点的地址信息,然后封装VXLAN数据包。VXLAN默认工作在VTEP设备的4789端口上。flannel.1在完成数据包封装后通过节点的eth0接口把数据包发送到网络上,当目的节点接收到数据包后会发给flannel.1设备,由flannel.1完成数据包的解封装,之后检查目的MAC是不是flannel.1设备自身的MAC地址,确认后继续将数据包转发给cni0网桥,由cni0网桥将数据包发送给目的Pod。
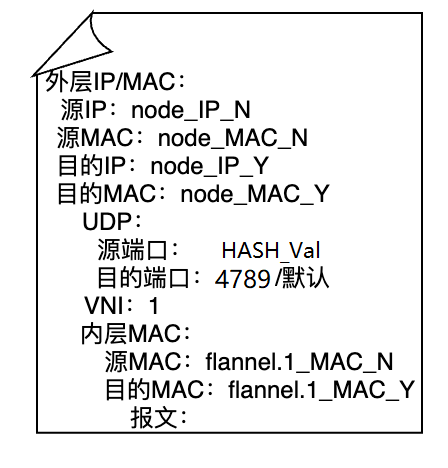
VXLAN的数据包格式如图-15所示,最外层的IP和MAC地址代表物理网络上联通通信的两端,在图-14中代表的是节点N和Y的eth0接口的IP和MAC地址。接着是UDP封装及VTEP设备上监听VXLAN请求的端口,目的端口默认是4789,源端口是由内层以太网帧头部计算出来的一个散列值,端口范围为49152-65535[4]。VNI表明了各个节点上的VTEP设备都在VNI为1的网络段中建立隧道构建逻辑网络。内层MAC地址指的是VXLAN隧道两端的VTEP的MAC地址,也就是节点N和Y上的flannel.1的MAC地址,最后的报文部分是Pod实际发出的报文内容。
在Flannel的VXLAN模式中,节点之间的VTEP设备MAC地址学习并不像标准的VXLAN网络那样是通过ARP协议来进行的,每个节点上的flanneld会将本地的flannel.1的IP和MAC信息同步给etcd,由各个节点的flanneld进程协作完成VTEP设备IP/MAC地址的更新和同步工作。
Flannel还提供了host-gw模式的backend来支持前面提到的直接路由模式,这么做可以一定程度上提升性能。通过在各个节点上添加到其他节点的路由信息,使得跨主机之间的Pod的IP数据包可以借助于节点的二层网络进行传递和转发。优点是省去隧道建立和封包/解封包造成的性能损耗,缺点是host-gw要求集群各个节点之间要做到二层互通,因为host-gw不具备跨网通信能力。也就是说,在数据包转发过程中的下一跳MAC地址无法指向另一个网络中的某个节点的地址。所以当遇到这个问题时,可以考虑采用Flannel的VXLAN的backend提供的DirectRouting模式。当Pod之间通信处在同一个网络时,那么就直接在二层网络完成通信操作,只有当通信的Pod不在同一个网段时,才会建立隧道实现跨网通信。
Pod和集群外实体通信
Pod除了可以和集群内的其他Pod进行通信,和Service通信外,还可以直接被集群外部的实体访问到。Kubernetes提供了两种方式将单独的Pod暴露在集群外:hostPort和hostNetwork。
hostPort
hostPort需要指定在Pod上,这样就会开启hostPort模式。当Pod进入hostPort模式后,集群外就可以通过hostIP:hostPort的方式访问到这个Pod上。这里的hostIP指的是Pod所在节点的节点IP。hostPort的配置如下:
1 | apiVersion: v1 |
hostNetwork
和hostPort一样,hostNetwork也需要配置在Pod上。当一个Pod配置了hostNetwork: true后,它可以看到自己所在节点上所有网卡的信息,可以监听流经所在节点的所有网络流量,就和其他运行在所在节点上的程序和进程一样。hostNetwork的配置如下所示:
1 | apiVersion: v1 |
如前所说,hostNetwork使得Pod有机会监听所在节点的所有网络通信。Flannel就是通过这种方式在集群节点上建立Overlay网络来实现跨节点通信的。
不论是hostPort还是hostNetwork,这两种暴露Pod的方式都有一个问题,那就是每次Pod被重启后其IP地址都会是一个新的IP地址,而且如果没有特殊配置,那么Pod每次重启后有可能会被调度到不同的节点上,因此需要通过其他方式来获取新的IP地址以及Pod所在节点(如有必要的话)来完成访问。如果是hostNetwork,由于两个应用无法占用同一个端口,所以同一个节点上无法部署两个使用同一个端口的Pod。
集群网络的构建过程
最后,我们会以Flannel为例、通过kubeadm的方式启动Kubernetes集群,简要总结下一个完整的Kubernetes集群网络是如何构建的:
- 通过kubeadm初始化集群,指定CNI插件为Flannel,并在Flannel的配置文件中通过Network等参数配置集群的CIDR信息
- Flannel配置的集群CIDR信息会保存在etcd中
- 当新的节点上线并尝试加入集群网络时,节点上的flanneld进程会向etcd申请本节点的Pod CIDR和其他完成通信所必须的地址信息,这些信息会被写在节点的subnet.env中。节点加入集群成功,准备好接受Master节点上scheduler的Pod调度。关于节点的规模大小,标准情况下每个节点最大仅容许同时运行110个Pod。因此每个节点的CIDR块大小约等于节点最大Pod数量的两倍,即每个节点拥有256个IP地址(“/24”)。这么做是为了减少在节点上创建、删除Pod时IP重复使用的概率,同时避免由于IP地址耗尽带来的Pod创建失败的问题
- 当节点接收到新的Pod创建请求时,节点上的CRI为Pod创建一个网络命名空间,之后CRI调用CNI完成网络的创建工作
- CNI首先会调用bridge插件检查本节点上是否存在cbr0网桥,如果没有就创建。然后bridge插件会创建一个veth-pair,veth-pair的一端插入为Pod创建的网络命名空间中,另一端接入到cbr0网桥。换言之,节点上的cni0网桥是在创建节点上的第一个应用Pod时创建的。
- CNI然后调用IPAM插件完成IP地址的申请和分配工作。IPAM会向CNI返回Pod的IP地址信息和网关IP(cbr0网桥为默认的Pod网关)
- CNI会将申请到的IP地址配置到Pod的网络命名空间中,此时Pod就拥有了集群中唯一的IP地址。如果cbr0是当前请求中新创建的,那么bridge插件会将网关地址配置到cbr0网桥上
- 所有已经申请过的IP地址信息会存储到本地的/cni/network/cni0文件中
涉及基础知识点
fork和exec的定义和区别
我们知道,进程是处于运行状态的程序的一个实例,程序运行在进程的上下文中。fork和exec都可以用来执行程序。fork会在新的子进程中运行运行相同的程序,新的子进程是父进程的一个复制品。fork函数调用一次返回两次,一次返回是在父进程中,返回的是子进程的PID,一次返回是在子进程中,返回0。
exec在当前进程的上下文中加载并运行一个新的程序,新的程序具有相同的PID,同时也继承了调用exec时当前进程已经打开的文件描述符列表。
参考文献
- 1.云原生实验室. Kubectl 创建 Pod 背后到底发生了什么?." N.p., 21 June 2019. Web. 23 Apr. 2021.
- 2.Lewis, Ian. "The Almighty Pause Container." Ian Lewis. N.p., 10 Oct. 2017. Web. 23 Apr. 2021.
- 3.Denham, Tom, et al. "Backends." GitHub. N.p., 29 Mar. 2017. Web. 1 May 2021.
- 4.Cotton, Michelle, et al. "Internet Assigned Numbers Authority (IANA) Procedures for the Management of the Service Name and Transport Protocol Port Number Registry." RFC 6335(2011):1-33. RFC Editor. Web. 14 May 2021.
- 5.Kubernetes contributors. "Create an External Load Balancer." Kubernetes. N.p., 15 Sept. 2020. Web. 14 May 2021.
- 6.Calico contributors. "About Kubernetes Services." docs.projectcalico.org. N.p., n.d. Web. 8 May 2021.
- 7.Kubernetes contributors. "Service." Kubernetes. N.p., 5 May 2018. Web. 8 May 2021.
- 8.Hannaford, Jamie. "What Happens When ... Kubernetes Edition!" GitHub. N.p., 25 Sept. 2017. Web. 23 Apr. 2021.
- 9.Bryant, Randal E., and David O’Hallaron. 深入理解计算机系统. Trans. 贺莲. 3rd ed. 北京: 机械工业出版社, 2016. Print.
- 10.Lewis, Ian. "What Are Kubernetes Pods Anyway?" Ian Lewis. N.p., 25 Aug. 2017. Web. 23 Apr. 2021.
- 11.Lewis, Ian. "Container Runtimes Part 4: Kubernetes Container Runtimes & CRI." Ian Lewis. N.p., 26 Jan. 2019. Web. 23 Apr. 2021.
- 12.Lewis, Ian. "Container Runtimes Part 1: An Introduction to Container Runtimes." Ian Lewis. N.p., 6 Dec. 2017. Web. 23 Apr. 2021.
- 13.Betz, Mark. "Understanding Kubernetes Networking: Pods." medium.com. N.p., 27 Oct. 2017. Web. 23 Apr. 2021.
- 14.意琦行. "Docker系列(四)---容器网络." 指月小筑. N.p., 27 Feb. 2021. Web. 29 Apr. 2021.
- 15.Denham, Tom, et al. "Configuration." GitHub. N.p., 29 Mar. 2017. Web. 1 May 2021.
- 16.Sookocheff, Kevin. "A Guide to the Kubernetes Networking Model." Kevin Sookocheff. N.p., 11 July 2018. Web. 1 May 2021.
- 17.Larsen, Michael Vittrup. "Debugging Kubernetes Networking." eficode.com. N.p., 7 Jan. 2019. Web. 1 May 2021.
- 18.Yingting, Huang. "Flannel Networking Demystify." msazure.club. N.p., 1 June 2018. Web. 8 May 2021.
- 19.Xiao, Han. "Kubernetes: Flannel Networking." Han’s blog. N.p., 17 Oct. 2017. Web. 8 May 2021.
- 20.RancherLabs. "在 Kubernetes 环境中,容器间如何进行网络通信." InfoQ. N.p., 23 June 2020. Web. 8 May 2021.
- 21.shida_csdn. "Kubeadm 集群初始化参数 Pod-Network-Cidr 有什么作用?." CSDN. N.p., 16 Feb. 2020. Web. 8 May 2021.
- 22.Nathani, Ronak. "How a Kubernetes Pod Gets an IP Address." Ronak Nathani. N.p., 21 Aug. 2020. Web. 9 May 2021.