在《K8s network之一:K8s网络模型与网络策略》中我们大概了解了Kubernetes的IP-Per-Pod模型和CNI接口规范,以及如何配置网络策略来限制出入Pod的流量。本篇会继续了解和学习Kubernetes集群如何向集群外提供服务访问以及服务之间如何相互发现这两个重要问题。出于篇幅考虑,相关的yaml配置不会在文章中出现,特殊情况除外,相关的yaml配置可以参考Kubernetes官方文档。
4.K8s network之四:Kubernetes集群通信的实现原理
5.K8s network之五:Kubernetes集群Pod和Service之间通信的实现原理
集群边界路由器Ingress
Kubernetes集群内部默认通过Service提供服务,通过Kube-proxy实现Service和Pod之间的负载均衡和转发功能。如果需要将服务暴露到集群外部,可以使用类型为NodePort和LoadBalancer的Service来对外提供服务,此外,你也可以使用Ingress来履行类型为NodePort和LoadBalancer的Service所承担的职责,相较于Service而言,使用Ingress暴露服务会更便利、更有优势。
Ingress专注于集群服务的对外暴露、负载均衡、L7转发、基于名称的virtual hosting等职责,它暴露了从集群外部到内部服务之间的HTTP/HTTPS路由,通过一个IP地址就可以暴露多个服务到集群外部,流量路由由在Ingress资源文件中定义的规则决定。需要注意的是,Ingress资源对象仅仅是转发规则的集合,并不负责具体功能的执行,要想真正完成对应的功能,需要Ingress控制器的加入。当使用Ingress进行负载分发时,Ingress 控制器基于Ingress规则会跳过Kube-Proxy直接将客户端请求直接转发到Service所属的某个Pod上。如果Ingress 控制器提供的是对外服务,则其实质就是一个边界路由器。
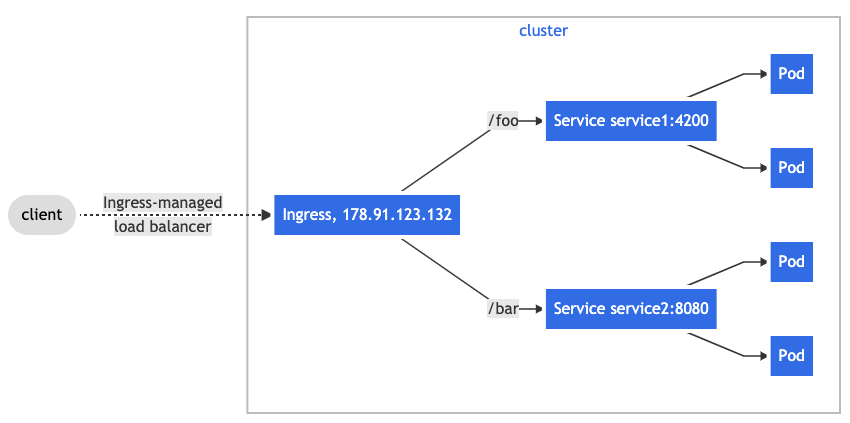
目前Kubernetes官方提供了AWS, GCE, 和ingress-nginx 控制器三种类型供用户根据自己的的实际情况进行选择,也正是因为这个原因,Ingress控制器不会像其他控制器那样随集群自动开启。换句话说,Ingress控制器不是kube-controller-manager的组成部分,它仅仅是Kubernetes集群的一个附件,需要在集群上单独部署。如果这三种实现方案无法满足需要,还有诸多第三方开源产品提供了对Ingress控制器的个性化实现,常见的产品包括但不限于可以配置Azure 应用网关的AKS Application Gateway Ingress Controller、适用于HAProxy的HAProxy Ingress、HAProxy Ingress Controller for Kubernetes、Voyager、适用于Traefik的Traefik Kubernetes Ingress provider、适用于Istio的Istio Ingress、可以配置F5 BIG-IP 虚拟服务的F5 BIG-IP Container Ingress Services for Kubernetes、借助 VMware NSX Advanced Load Balancer提供L4-L7层负载均衡的Avi Kubernetes Operator等,实际上可供用户选择的产品还是非常丰富的。
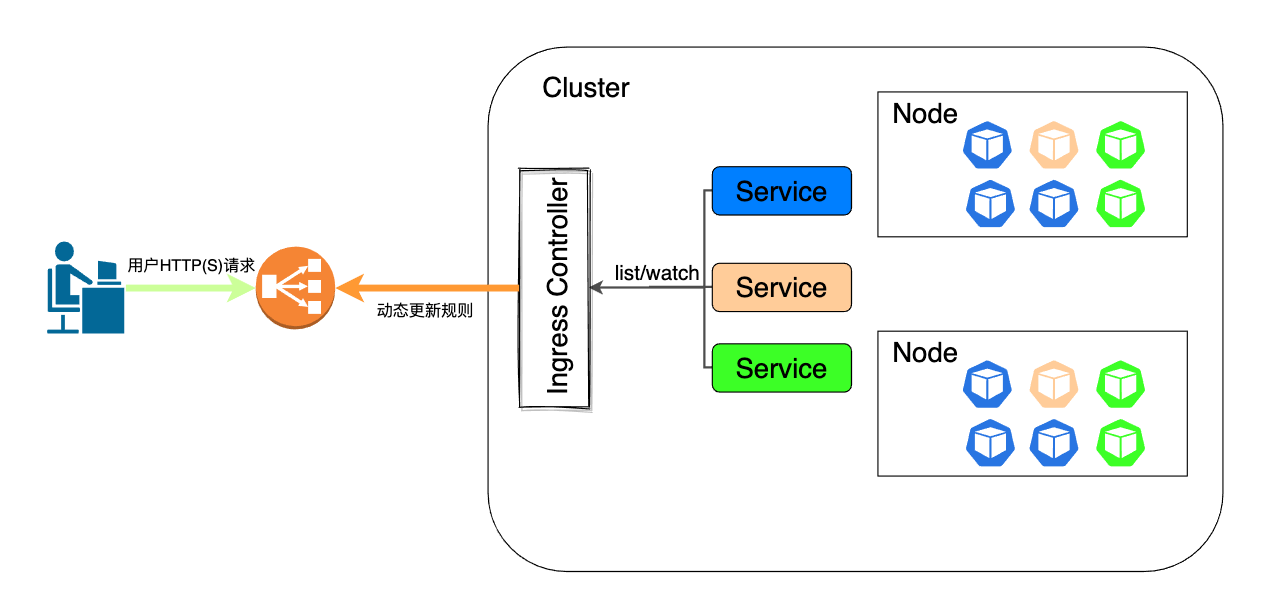
传统的反向代理(例如Nginx和HAProxy)对服务的动态变化是带有滞后性的,也就是说服务发生变更后,反向代理可能会需要一些时间来改变配置和重新加载。在微服务的开发模式下,这个问题会进一步放大,影响了微服务效能的最大化。Ingress控制器的出现使得这个问题得到了极大改善,它不仅继承了反向代理的职能,还可以通过关注服务注册、编排随时感知后端服务的变更,将服务变更同步到负载均衡器的配置中,如有必要甚至自动重新热加载。这整个过程对用户来说是透明的,整个同步和热加载期间服务也不会停止对外提供服务。以Kubernetes维护的ingress-nginx控制器为例,它以Kubernetes集群和负载均衡器之间的适配器的身份发挥职能,不仅要与Kubernetes集群交互,还要根据需要对Nginx配置进行热更新和重载。而Traefik在设计之初就坚持了云原生的思想,它在提供反向代理职能的同时,原生支持Kubernetes的Ingress,可以感知集群服务的变化并进行更新。
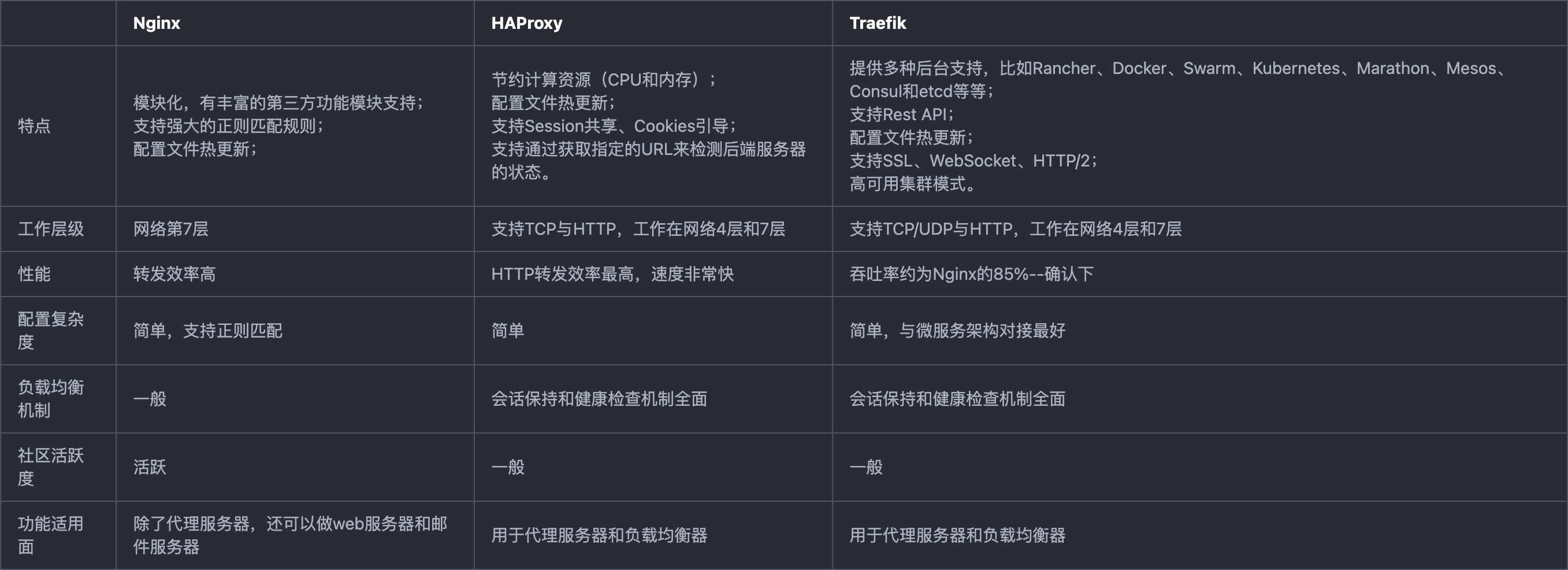
Nginx、HAProxy、Traefik三种方案的特点如表1所示:
以Kubernetes官方维护的ingress-nginx为例,ingress-nginx借助于三个组件完成Ingress的职责:控制器NginxController、协程Store和队列SyncQueue,其整体工作模式架构图如图所示:
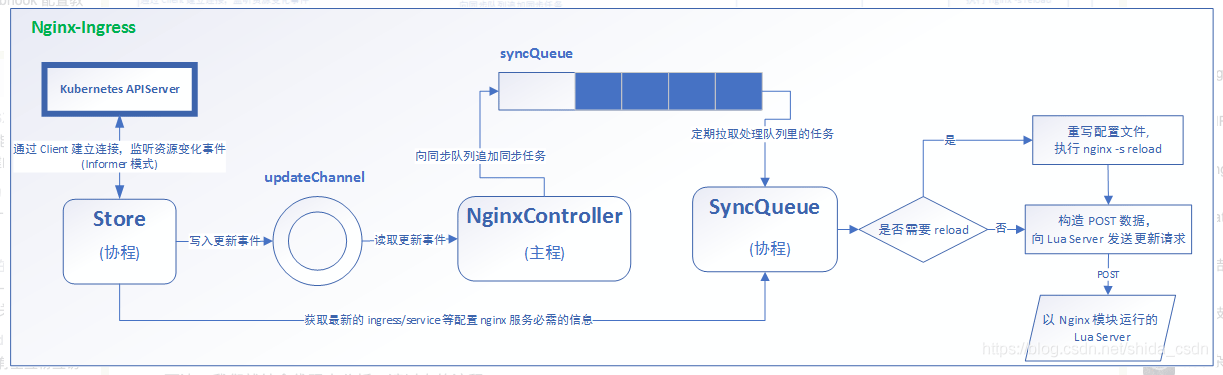
Store监控Kubernetes APIServer的运行状态,收集服务资源的变化信息,然后会将这些变化写入一个updateChannel。NginxController会将写入的更新事件同步到队列syncQueue中。协程SyncQueue从syncQueue中取出更新任务并生成新的nginx配置数据,并根据更新的性质决定是否重载nginx配置,最后构建POST数据通知本地Lua Server执行配置的动态更新操作。
前面提到Ingress的存在会使得Kube-Proxy失去作用,实际是因为Ingress控制器会从Service所属的EndPoints集合中选择一个Pod,并将请求直接发送到当前被选中的Pod上。换句话说,请求不再经过Service层面即可到达Pod上,只是借助Service所掌握的endpoints信息选择一个Pod而已。但是如果使用Ingress以应用负载器的身份作用于Node Port上时,还是需要Kube-Proxy将HTTP请求转发到某个Pod上。这整个过程的执行过程如图4所示:
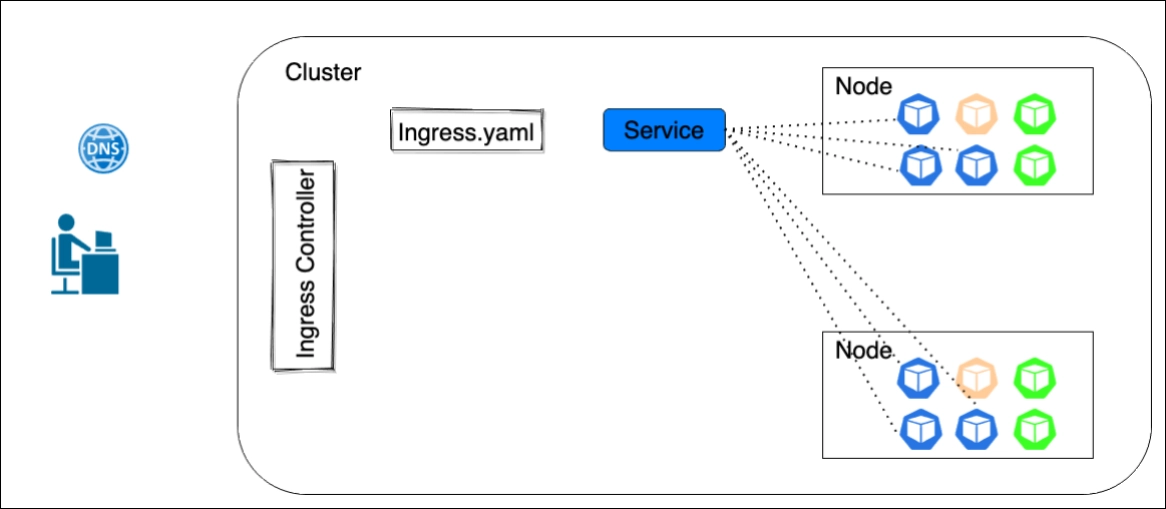
图 - 4 Ingress工作流程
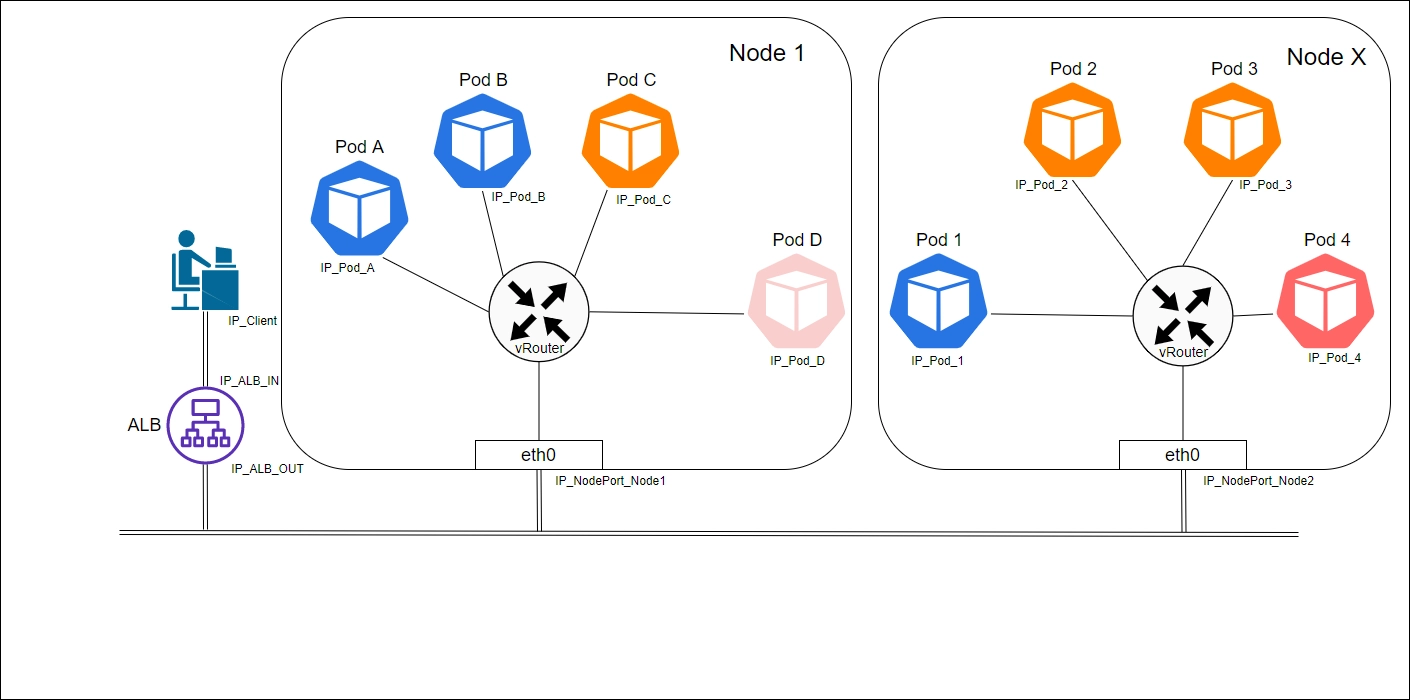
图 - 5 Ingress以应用负载均衡器(ALB)直接作用于Pod上
在某些场景下,Ingress控制器可以作用于NodePort上。这种场景下,Ingress控制器根据Ingress配置决定由哪个服务来处理当前的HTTP请求,并将请求转发到一个NodePort上,由该节点的Kube-Proxy完成到后端Pod的转发工作。
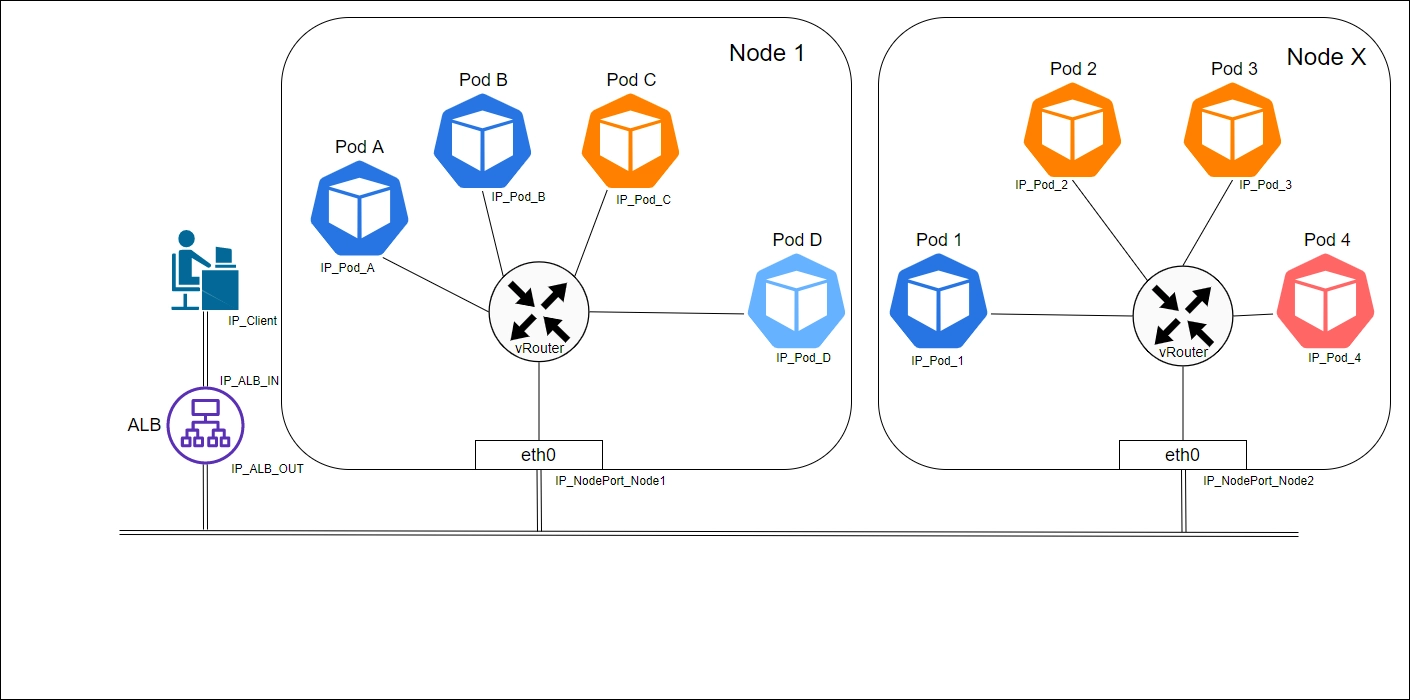
图 - 6 Ingress以应用负载均衡器(ALB)直接作用于NodePort上
在一些产品实现中,Ingress控制器也可以以网络负载均衡器的身份在OSI第4层发挥作用。在这种应用模式下,Ingress以服务的方式对外集群外暴露,同时配置外部网络负载均衡器(Network Load Balancer,NLB),接入所有来自NLB的流量,之后根据Ingress配置将HTTP请求直接转发到某个Pod上,这种场景同样不需要Kube-Proxy的参与。如图6所示:
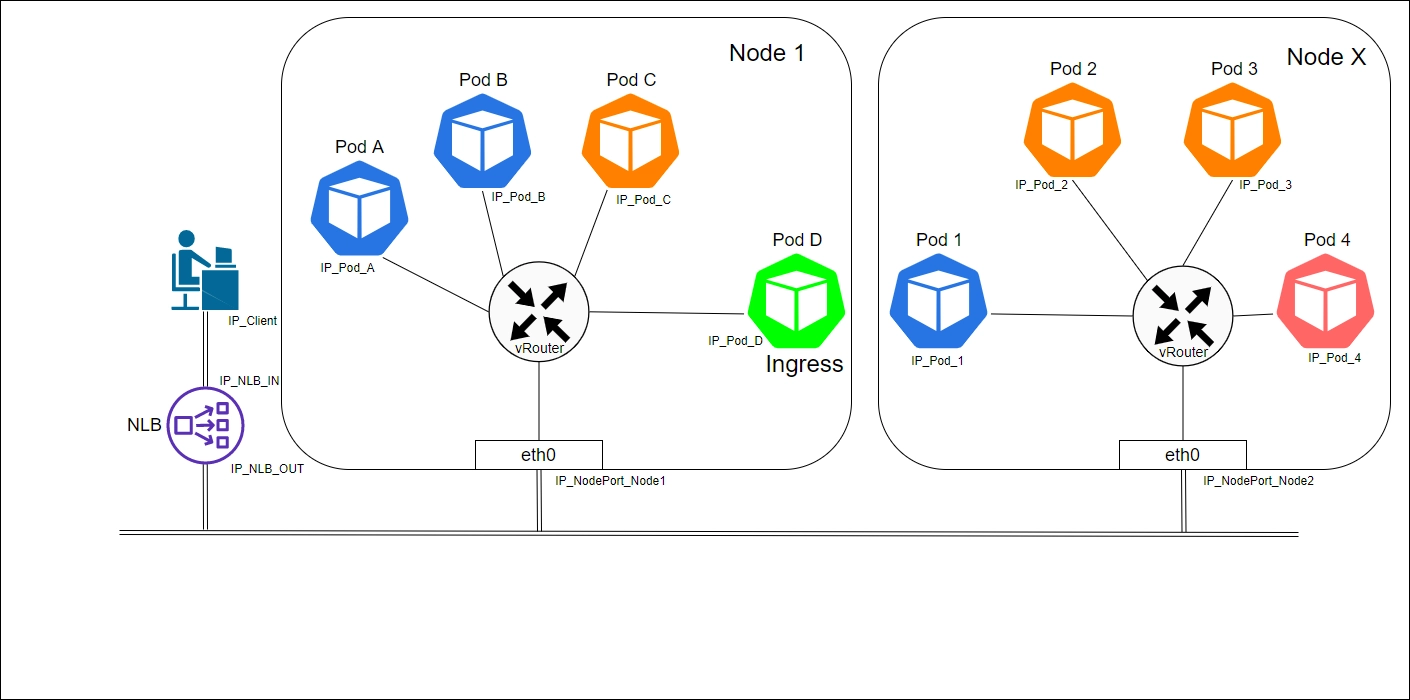
图 - 7 Ingress以网络负载均衡器的身份工作
有了Ingress,我们可以在对外提供服务的同时满足Service无法提供的诸多特性。你可以根据二者的特性在实际使用过程中进行选择来更好的满足需要。这里对二者进行了一个简单的比较:
- 二者流量方向不同。Kube-Proxy主导下的Service专注的是出站流量,Ingress关注的入站流量(出站、入站指的是出入Pod)
- 二者在OSI模型中位置不同。Service工作在OSI模型4层,而Ingress工作在7层。针对Ingress控制器的不同实现,有的产品除了7层外还可以根据需要在4层发挥作用
- 二者功能存在差异。Service无法提供诸如HTTP路由、URL转发等功能,而Ingress提供了负载平衡器的典型特性:HTTP路由、黏性会话、SSL终止、SSL直通、TCP和UDP负载平衡等
- 二者服务对外暴露实现方案不同。多个Service对外暴露需要多个相互独立的公网IP地址和端口,Ingress可以在一个公网IP地址上完成对多个服务的暴露和路由功能。
域名解析和服务发现
Kubernetes是可以支持IP地址加端口的形式来完成相互通信和访问的,但是这样会带来一个问题,Kubernetes内部Pod和Service的迭代速度是比较高的,每次迭代都可能导致Pod和Service的IP地址和端口发生变化。但是Service名字等一些标识信息是不会经常变动的,所以Kubernetes更推荐通过Service的名字来访问服务。这就需要一个高效可靠的服务发现机制来支持借助Service名字完成服务访问的功能。
服务发现的基本实现思想一般是事先部署好一个网络位置稳定的服务注册中心,由服务提供方向注册中心上报自己的相关信息,同时还要及时的向注册中心同步自己的状态变更。服务请求方在发起服务请求时会通过注册中心获取对应的服务提供方的相关信息,从而与提供方建立连接请求服务。根据发现过程的实现方式,服务发现可分为两种类型:
- 客户端发现。客户端自身到注册中心查询其依赖服务的相关信息,因此客户端需要实现一套服务发现程序和发现逻辑
- 服务端发现。服务请求方将请求发往一个独立的中央路由器或者负载均衡器的组件,这个中央路由器或者负载均衡器负责到注册中心查询服务提供方的相关信息并将客户端请求转发到对应的服务提供方
服务发现和域名(名称)解析是Kubernetes的基础服务之一。Kubernetes集群上的每个Service资源对象在创建时都会被自动委派一个格式为<service>.<ns>.svc.<zone>格式的名称,并由ClusterDNS为该名称自动生成资源记录,其中,service、ns、zone分别标识服务的名称、命名空间和集群域名。无论具体采用哪种实现方案,每个Service对象都会拥有如下3种类型的DNS资源记录。
普通Service对象
A/AAAA记录
如果是Service的Cluster IP是IPv4地址,会生成一条如下格式的记录:
<service>.<ns>.svc.<zone>. <ttl> IN A <cluster-ip>
如果是Service的Cluster IP是IPv6地址,会生成一条如下格式的记录:
<service>.<ns>.svc.<zone>. <ttl> IN AAAA <cluster-ip>
上述格式中,<service>指的是Service的名称,<ns>为命名空间,<zone>为集群域名,<ttl>为DNS记录的存活时间,<cluster-ip>为Service的Cluster IP
如果存在被定义了名称的端口,那么就为这个端口生成一条SRV记录。未命名的端口则不会有该记录。
_<port>._<proto>.<service>.<ns>.svc.<zone>. <ttl> IN SRV <weight> <priority> <port-number> <service>.<ns>.svc.<zone>.
上述格式中,_<port>为端口名称,_<proto>为端口遵循的协议,<service>为服务名称,<ns>为命名空间,<zone>为集群域名,<ttl>为DNS记录的存活时间,<priority>为目标域名的优先级,值越小越优先,<weight>为相同优先级记录的相对权重,值越大越优先 ,<port-number>为端口号。当有多个server提供服务时,通过priority和weight可以设置由哪个server优先提供服务。换句话,哪个server可以接受并处理更多的请求。如果一个server的priority值越小,那么这个server会接受更多的流量请求。如果几个server的priority值相同,那么server的weight值越高,这个server就会接受更多的流量请求。这两个值看似作用相同,实际上还是有点区别的:在判定由哪个server来处理请求时,会先使用priority进行判定,如果判定成功,那么不论weight值如何,都不会影响判定结果。但如果使用priority无法判定出一个server,此时weight就会介入判定过程。关于<priority>和<weight>的详细定义,可浏览RFC 2782。
针对为每个Service分配的Cluster IP,会生成一条PTR记录。格式如下:
如果Cluster IP为IPv4版本:
<D>.<C>.<B>.<A>.in-addr.arpa. <ttl> IN PTR <service>.<ns>.svc.<zone>.
如果Cluster IP为IPv6版本a1a2a3a4:b1b2b3b4:c1c2c3c4:d1d2d3d4:e1e2e3e4:f1f2f3f4:g1g2g3g4:h1h2h3h4:
h4.h3.h2.h1.g4.g3.g2.g1.f4.f3.f2.f1.e4.e3.e2.e1.d4.d3.d2.d1.c4.c3.c2.c1.b4.b3.b2.b1.a4.a3.a2.a1.ip6.arpa <ttl> IN PTR <service>.<ns>.svc.<zone>.
Headless Service对象
A/AAAA记录
如果Endpoints的IP是IPv4地址,会生成一条如下记录:
<service>.<ns>.svc.<zone>. <ttl> IN A <endpoint-ip>
上述格式中,<service>指的是Service的名称,<ns>为命名空间,<zone>为集群域名,<ttl>为DNS记录的存活时间,<endpoint-ip>为endpoint的IP地址
如果Endpoints的IP是IPv6地址,会生成一条如下记录:
<service>.<ns>.svc.<zone>. <ttl> IN AAAA <endpoint-ip>
如果Endpoints不仅有IPv4的endpoint-ip,还有域名,那么记录格式如下:
<hostname>.<service>.<ns>.svc.<zone>. <ttl> IN A <endpoint-ip>
如果Endpoints不仅有IPv6的endpoint-ip,还有域名,那么记录格式如下:
<hostname>.<service>.<ns>.svc.<zone>. <ttl> IN AAAA <endpoint-ip>
同普通Service一样,如果存在被定义了名称的端口,那么就为这个端口生成一条SRV记录。未命名的端口则不会有该记录。
_<port>._<proto>.<service>.<ns>.svc.<zone>. <ttl> IN SRV <weight> <priority> <port-number> <hostname>.<service>.<ns>.svc.<zone>.
给定一个分配了域名和IP地址的endpoint,会有一条PTR记录,格式如下:
如果IP地址为IPv4格式<a>.<b>.<c>.<d>:
<d>.<c>.<b>.<a>.in-addr.arpa. <ttl> IN PTR <hostname>.<service>.<ns>.svc.<zone>.
如果IP地址为IPv6格式<a1a2a3a4:b1b2b3b4:c1c2c3c4:d1d2d3d4:e1e2e3e4:f1f2f3f4:g1g2g3g4:h1h2h3h4>:
h4.h3.h2.h1.g4.g3.g2.g1.f4.f3.f2.f1.e4.e3.e2.e1.d4.d3.d2.d1.c4.c3.c2.c1.b4.b3.b2.b1.a4.a3.a2.a1.ip6.arpa <ttl> IN PTR <hostname>.<service>.<ns>.svc.<zone>.
外部服务
如果一个服务被分配了一个外部服务名称,那么会生成一条CNAME记录。格式如下:
<service>.<ns>.svc.<zone>. <ttl> IN CNAME <extname>.
需要注意的是,IPv4和IPv6地址的CNAME记录的格式是一致,需要在查询和解析的时候指明IP地址的版本号:
foo.default.svc.cluster.local. IN A 会尝试解析域名并得到一条IPv4格式的响应:
- foo.default.svc.cluster.local. 10 IN CNAME www.example.com.
- www.example.com. 28715 IN A 192.0.2.53foo.default.svc.cluster.local. IN AAAA 则会尝试解析域名并得到一条IPv6格式的响应:
- foo.default.svc.cluster.local. 10 IN CNAME www.example.com.
- www.example.com. 28715 IN AAAA 2001:db8::1Pod
在Kubernetes中,Pod也会执行DNS记录的插入和维护工作。如果要为Pod生成一条DNS记录,则其格式如下:
<pod-ip-address>.<my-namespace>.pod.<cluster-domain.example>
例如,给定一个在“dns-test”命名空间里的IP地址为172.172.0.3的Pod,这个Pod所在集群的域名是cluster.dns.test.local,那么生成的记录如下:
172-172-0-3.dnsTest.pod.cluster.dns.test.local
如果Pod是被deployment或者通过Service暴露的daemonSet创建的,那么其对应的DNS记录格式如下:
<pod-ip-address>.<deployment-name>.<my-namespace>.svc.<cluster-domain.example>
集群内DNS
在Kubernetes集群内,DNS作为系统级服务,主要用于解析集群内各个Service的服务名,完成从服务名到对应的Cluster IP的解析,因此需要在集群内设置一个相对固定的网络IP地址,还要保证这个IP不能和真实的DNS服务器发生冲突。可以在每台Node的Kubelet启动参数上指定—cluster-dns=X.X.X.X —cluster-domain= cluster.local来通知节点内每个Pod关于DNS服务的具体信息,这些信息会在容器的配置文件/etc/resolv.conf中得以体现。接下来就需要通过插件来启动集群内的DNS服务了,Kubernetes的DNS服务提供产品也从v1.3之间的SkyDNS、v1.3之后的kube-dns过渡到了v1.10之后的CoreDNS,同时在Kubernetes的v1.21版本中,官方已经停止了对kube-dns的支持。CoreDNS是CoreOS公司用Go语言开发的Kubernetes DNS服务框架,在Kubernetes v1.10版本中作为beta版集群DNS服务,希望可以逐步替代kube-dns服务。CoreDNS具有高性能、非常灵活、可扩展的插件式模型,各种插件根据请求提供不同的操作,例如日志记录、重定向、自定义DNS记录等。CoreDNS解决了kube-dns的一些问题,例如dnsmasq的安全漏洞、externalName不能使用stubDomains设置,等等。CoreDNS的一般架构如图8所示:
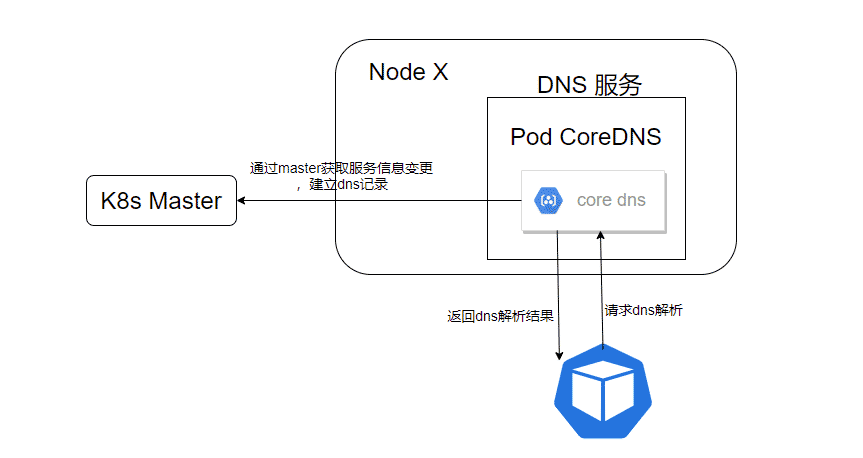
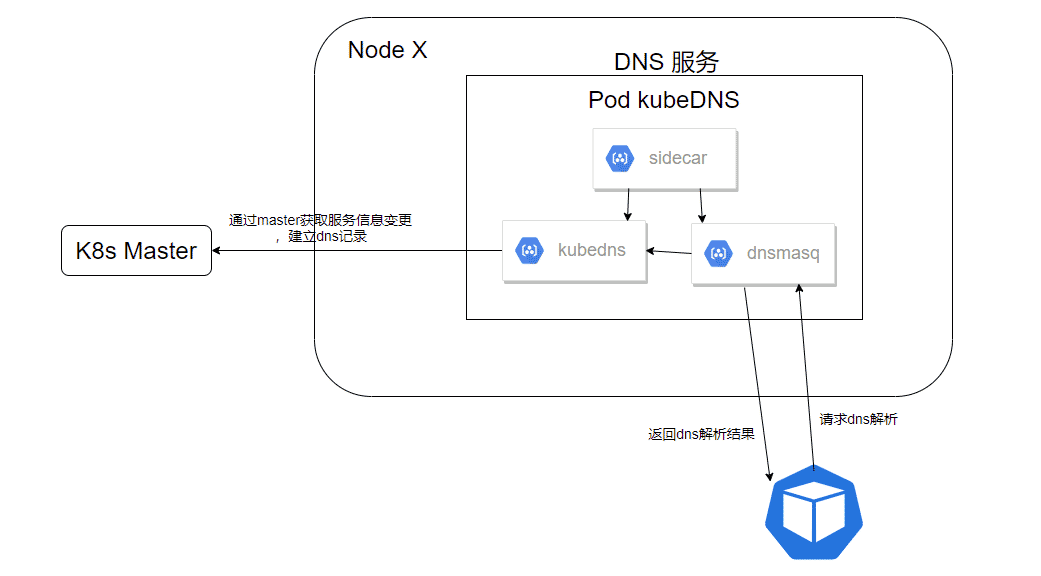
相较于kube-dns,CoreDNS只用一个容器就完成了DNS服务的所有工作,在可用性和效率上会比kube-dns优秀很多。kube-dns中,kubedns用于监控Service和endpoints的变更并建立和更新DNS记录,并将相关记录保存在内存中,dnsmasq则提供具体的DNS解析服务,数据均来自kubedns。sidecar则负责kubedns和dnsmasq的健康状态监测。
CoreDNS服务的相关配置都在corefile文件中得到体现,并且向用户提供了一种简单易懂的DSL来定义满足用户需求的DNS服务实现。DSL的具体语法结构如下:
1 | label { |
在DSL的支持下,corefile的典型格式如下:
1 | //ZONE 定义server负责的zone |
在corefile中,借助上述语法格式可以定义若干个server block,每个block有一个标签label和紧随其后的一对花括号及括号内的内容构成。每个server block定义了DNS server以什么协议在哪个端口上监听DNS请求、DNS server会用到哪些插件来构建插件链以及DNS server负责哪个zone(可以理解为域名)的DNS解析工作。一个简单的corefile文件定义(部分)如下:
1 | coredns.io:5300 { |
在CoreDNS中,每个端口会指向一个dnsserver.Server,所以尽管上述的配置文件中有5个server block,但是最后会得到三个dnsserver.Server。CoreDNS会把指向相同端口的server block聚合成一个dnsserver.Server,如果有多个label标签指向了同一个端口,那么在匹配时会按照自右向左最长匹配原则进行处理和选择。这个Server会在这个相同的端口上通过多路复用提供DNS解析服务,并根据不同的域名传递到不同的插件链中进行处理。
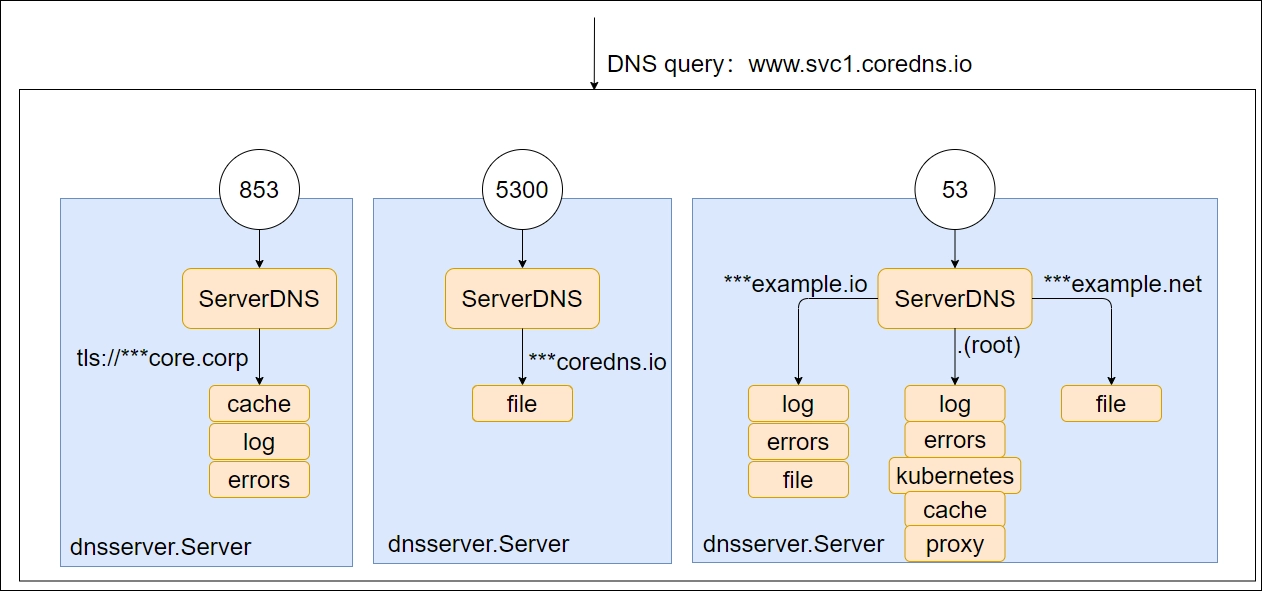
图 - 10 corefile配置示例
需要注意的是,在最后一个server block的配置中含有一个health插件,但是在图-10中并未出现对应的health插件。这是因为在CoreDNS的设计中将插件分为了两种类型的插件:一种插件是用来处理DNS请求的,因此会出现在插件链中。还有一类插件仅仅是用来修改server或者server block的配置,换言之,它们和处理DNS请求无任何关系,因此这类插件不会被插入到插件链中。这种类型的插件包括health、tls、startup、shutdown和root等插件。
CoreDNS支持如下四种协议来访问DNS解析服务:
- dns:// for plain DNS (默认值,无需指定前缀)
- tls:// for DNS over TLS(DoT), 参考 RFC 7858
- https:// for DNS over HTTPS(DoH),参考 RFC 8484
- grpc:// for DNS over gRPC
所以在第二个server block的定义中,定义了tls://前缀,这意味着这个server block仅支持使用tls协议来访问CoreDNS完成DNS的解析工作。
一个可以实现完整功能的CoreDNS应用是由若干个插件完成的,每个插件负责实现一个具体的功能。如果有多个插件,那么这些插件会形成一个调用链,即插件链。当一个DNS解析请求到达时,首先通过贪心原则来匹配zone,进而选择一个处理当前请求的server。接着会根据plugin.cfg中定义的顺序顺着插件链逐个通过每个插件完成其功能,每个插件会做出如下判断来决定是否处理当前请求:
- 请求被当前插件处理。当前插件会处理请求并直接向客户端返回响应,插件链调用结束。
- 请求跳过当前插件。当前插件不会处理请求并将请求直接传递给下一个插件。
- 请求被当前插件以Fallthrough形式处理。请求在当前插件处理过程中有可能会传递给下一个插件,这种现象称为fallthrough。
- 请求被当前插件处理并伴随hint信息一同传递给下一个插件。
plugin.cfg的内容如下所示(部分):
1 | //每行由冒号分隔,前面是插件名称,后面是插件包名。 |
每个插件的声明如下所示:
1 | type ( |
所以只需要实现ServerDNS()和Name()方法,即可实现一个新的插件。所以说,插件的实质就是一个出入参数都是Handler的函数。在插件链执行过程中,每个插件可以通过NextOrFailure函数调用下一个插件的ServerDNS()方法,如果next为nil,说明插件链已经调用结束,会直接返回no next plugin found。如果不想继续向后传递,也可以通过WriteMsg()结束整个调用链。
CoreDNS is powered by plugins.
— coredns.io
回到Kubernetes集群,如果想要使用CoreDNS实现DNS解析服务,那么只需要修改configmap文件,在其中加入corefile即可使用CoreDNS。示例如下:
1 | apiVersion: v1 |
除了配置集群级别的DNS服务和规则,Kubernetes还支持在Pod上配置相应的DNS策略和配置,从而实现基于Pod的个性化的DNS解析服务。在Pod的资源文件中,可以通过两个字段spec.dnsPolicy和spec.dnsConfig字段进行设置。其中,dnsPolicy字段用于设置DNS策略,dnsConfig可用来自定义DNS的相关配置。当前版本中,dnsPolicy支持的DNS策略包括如下:
Default。Pod会直接继承其所在节点(宿主机)的域名解析配置。实质上是让kubelet决定DNS策略,kubelet默认使用所在节点在/etc/resolv.conf下的配置,所以Pod默认会直接继承其所在节点的域名解析配置。同时,kubelet提供了参数–resolv-conf=来决定DNS策略的配置。
ClusterFirst。使用集群内的DNS服务(kube-dns或者CoreDNS)完成DNS解析工作。任何无法匹配和使用集群内DNS服务的DNS请求都会被转发到上游域名服务器进行处理,上游域名服务器的相关信息来自于Pod所在节点(宿主机)。
- ClusterFirstWithHostNet。如果有Pod直接运行在宿主机网络上,那么Pod会直接使用宿主机的 /etc/resolv.conf 配置进行DNS解析。如果不想这么做而是继续通过集群内的DNS服务完成解析时,那么应该显式的将DNS策略设置为ClusterFirstWithHostNet。
- None。Pod会忽略来自Kubernetes环境变量的所有DNS设置,而由dnsConfig字段的配置提供DNS配置。
同时,dnsConfig可以用于设置如下配置信息:
- nameservers。用来为Pod提供DNS服务的IP地址列表,最多可设置3个。如果Pod的dnsPolicy设置为None,这个字段必须至少指定一个IP地址。除了这种情况之外,这个字段可填可不填。
- searches。在Pod里用于域名查询的DNS搜索域列表。这个字段是可选项,如果指定了该字段,那么这个列表会被合并到由指定的DNS策略生成的基础搜索域名集合中。如果有重复域名,则只会保留一份。此外Kubernetes限制搜索域的个数最多有6个。
- options。DNS的配置选项列表。每个选项必须有一个name属性,可以有一个value属性。列表中的内容会被合并到由指定的DNS策略生成的配置选项数据中,如果有相同配置存在,只会保留一份。
尽管集群DNS服务(kube-dns/CoreDNS)的性能非常优秀,但是随着集群规模的迅速增长,如果每个Pod都直接和集群DNS服务交互完成DNS解析服务,那么集群DNS服务最终也会疲于应对以致性能下降。为了解决这个问题,Kubernetes在v1.18版本引入了NodeLocal DNSCache来缓解集群DNS服务的压力。NodeLocal DNSCache会在集群的每个节点上以DaemonSet形式运行一个dns缓存代理Pod,之后Pod会先通过其所在节点的缓存代理完成DNS解析请求,如果解析失败,缓存代理才会向集群DNS服务发起DNS解析请求完成DNS解析。这些dns缓存代理处于其所在节点的kube-system命名空间下。
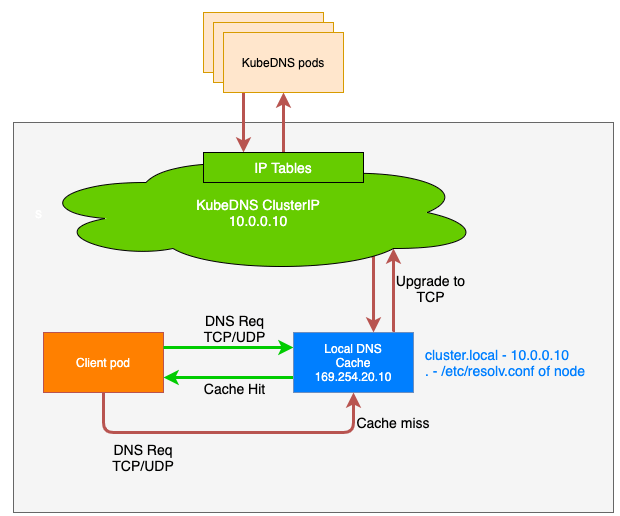
自定义DNS服务器和上游DNS服务器
kube-dns和CoreDNS都提供了自定义DNS服务器和上游DNS服务器的能力。在kube-dns中,通过如下配置便可以完成DNS服务器和上游服务器的配置:
1 | apiVersion: v1 |
上述配置文件转换成CoreDNS的corefile如下:
1 | .:53 { |
涉及基础知识点
DNS记录中A、AAAA、SRV、PTR、CNAME的含义
A由RFC 1035定义,用于IPv4版本的DNS解析。常用于将一个主机名映射到一个IPv4地址。记录包括域名、对应IP地址、以秒为单位的TTL值,TTL会告诉DNS服务器应该在缓存中保留给定记录多久。
AAAA由RFC 3596定义,用于IPv6版本的DNS解析。常用于将一个主机名映射到一个IPv6地址。
SRV由RFC 2782定义,SRV记录标记了哪台服务器提供了什么服务。它除了指明服务的IP地址外,还指明了哪个端口会提供对应的服务。
PTR由RFC 1035定义,是A/AAAA记录的逆向记录,用于将IP地址反向映射到一个域名,因此也称为IP反查记录或者指针记录。
CNAME(Canonical Name)由RFC 1035定义,通常称为别名指向。用于将多个域名映射到同一个主机上。
DNS Search Domain
DNS Search Domain(DNS 搜索域)是DNS服务用来解析非全限定域名的一个概念。
全限定域名可以从根域(根域只是一个空字符串)逐级向下解析并最终返回一个IP地址。换句话说,全限定域名以诸如.com, .org, .net, .ca之类的顶级域名为后缀。根域包含了为全球顶级域名服务的域名解析服务器信息。
以www.google.com.为例,在全球DNS体系中它是一个全限定域名。在com.之后是不可见的根域部分,专门在com之后留了一个点,意味着根域就是处理解析请求的最高级别区域。但是,myhost却不是一个全限定域名,在尝试定位和解析myhost的时候可能会引起歧义。
一个全限定域名(FQDN)一定是非歧义的。可能会有多个IP地址绑定在一个域名上,但是绝不可能出现两条冲突的DNS结果。继续以myhost为例,可能会有myhost.example.com、myhost.example2.com等等之类的域名地址,所以需要一种机制来消除这种歧义现象,这就是DNS搜索域产生的背景。说白了,搜索域就是一个用来追加在一个非全限定域名后面的有序的域列表。
许多公司和组织机构在构建内部网络时都有它们自己的DNS服务器。鉴于诸如现实和安全等一些目的,不使用全局域是一种普遍情况。一般而言,诸如”.local”, “.localdomain”, 和 “.corp”等等都是常见的内部域,在根域中是无法找到这些域的记录的。在同一台DNS服务器上,可能同时存在myhost.localdomain和myhost.otherdomain,搜索域会告诉服务器应该选择哪一个继续后面的工作。
上面摘自What does “DNS search domains” mean?中的内容。实际上搜索域就是一个域名后缀的集合,有的时候在做DNS解析的时候有可能给的不是一个完整的域名结构,比如”nrl-iman“。这个时候如果做域名解析的时候可能会有问题,因为”nrl-iman“所属的域无法确定,可能是”nrl-iman.com“、”nrl-iman.org“、”nrl-iman.corp“,”nrl-iman.cn.corp“等等。所以这个时候就需要给一个域后缀列表,指明当处理”nrl-iman“时,要在哪些域中尝试解析”nrl-iman“。假设设置搜索域为“corp”,“cn.corp”,那么当处理”nrl-iman“就只会考虑”nrl-iman.corp“,”nrl-iman.cn.corp“这两种情况,而不会尝试解析”nrl-iman.com“和”nrl-iman.org“。
参考文献
- 1.Kubernetes contributors. "Ingress" Kubernetes.io. N.p., 19 Aug. 2019. Web. 14 Apr. 2021.
- 2.shida_csdn. "K8S 源码探秘 之 Nginx-Ingress 工作原理分析." CSDN. N.p., 14 Nov. 2018. Web. 14 Apr. 2021.
- 3.Kubernetes contributors. "Using NodeLocal DNSCache in Kubernetes clusters" Kubernetes.io. N.p., 11 Jun. 2019. Web. 14 Apr. 2021.
- 4.Project Calico. Kubernetes Ingress Networking. YouTube, 3 May 2020, 14 Apr. 2021.
- 5.O’Haver, Chris, et al. "Kubernetes DNS-Based Service Discovery." GitHub. N.p., 10 Jan. 2017. Web. 15 Apr. 2021.
- 6."What Is a DNS SRV Record?" Cloudflare. N.p., n.d. Web. 15 Apr. 2021.
- 7.Wikipedia contributors. "List of DNS record types." Wikipedia, The Free Encyclopedia. Wikipedia, The Free Encyclopedia, 2 Jun. 2021. Web. 19 Apr. 2021.
- 8.Google Cloud contributors. "GKE Ingress for HTTP(S) Load Balancing." Google Cloud. N.p., n.d. Web. 15 Apr. 2021.
- 9.Luksa, Marko. Kubernetes in Action中文版. Trans. 七牛容器云团队. 1st ed. 北京: 电子工业出版社, 2019. Print.
- 10.杜军. Kubernetes网络权威指南:基础、原理与实践. 1st ed. 北京: 电子工业出版社, 2019. Print.
- 11.闫健勇, et al. Kubernetes权威指南:企业级容器云实战. 1st ed. 北京: 电子工业出版社, 2018. Print.
- 12.马永亮. Kubernetes进阶实战. 2nd ed. 北京: 机械工业出版社, 2019. Print.
- 13.Kubernetes contributors. "Customizing DNS Service" Kubernetes.io. N.p., 20 Jun. 2018. Web. 14 Apr. 2021.
- 14.CoreDNS contributors. "CoreDNS Manual." CoreDNS. N.p., n.d. Web. 15 Apr. 2021.
- 15.Kubernetes contributors. "DNS for Services and Pods" Kubernetes.io. N.p., 5 May. 2018. Web. 14 Apr. 2021.
- 16.Project Calico contributors. "Component Architecture." Project Calico. N.p., n.d. Web. 15 Apr. 2021.
- 17.晒太阳的猫. "CoreDNS 插件系统的实现原理." zhengyinyong.com. N.p., 4 Feb. 2019. Web. 13 Apr. 2021.
- 18.Google Cloud contributors. "Setting up NodeLocal DNSCache." Google Cloud. N.p., n.d. Web. 13 Apr. 2021.
- 19.Anthony, Cornell. "Using a Network Load Balancer with the NGINX Ingress Controller on Amazon EKS." AWS Open Source Blog. N.p., 9 Aug. 2019. Web. 14 Apr. 2021.
- 20.Kubernetes contributors. "Ingress Controllers." Kubernetes. N.p., 18 Feb. 2019. Web. 14 Apr. 2021.
- 21.Kubernetes contributors. "Ingress." Kubernetes. N.p., 19 Aug. 2019. Web. 14 Apr. 2021.
- 22.乾坤李. "CNI——容器网络是如何打通的." 李乾坤的博客. N.p., 11 Oct. 2018. Web. 14 Apr. 2021.
- 23.Belamaric, John, and Cricket Liu. Learning CoreDNS:Configuring DNS for Cloud-Native Environments. 1st ed. Boston: O’Reilly Media, 2019. Print.
- 24."How It Works." NGINX Ingress Controller. N.p., n.d. Web. 14 Apr. 2021.